我們都知道, 關聯式資料庫(以MySQL為例) 建議欄位值不允許null, 因為欄位被用來做為查詢條件, 並且也加入索引, 如此一來null值就會降低查詢的效率, 所以通常像是varchar的欄位若非必填, 可設預設值為''、數值型欄位預設值可設成0, 那麼, 日期(Date)的欄位如果非必填, 要怎麼設計?
假如某需求可允許使用者不填日期(但它在table的欄位不允許null), 如果在不填日期的情況下新增資料完成後, 在頁面上看到此日期顯示的值是空白。而此日期欄位是常用的搜索條件之一, 所以有被加入索引。
因此我能想到的方法有兩個:
方法1. 日期欄位型別是Date, 預設值設成0001-01-01, 所以每次資料撈出來後, 要特別處理日期的資料, 處理的地方可在select語法裡做, 或是在讀出資料後的程式裡做, 做法就是判斷若是0001-01-01就返回空字串。但如果整個系統有100的地方會顯示這個日期, 那不就要在這100個地方做這種特殊處理, 實在很不理想!
方法2. 日期欄位型別是用varchar, 預設值設成空字串 '', 方便之處在於不用做 方法1 那種額外的資料處理, 但缺點就是它是字串, 不是強型別的資料, 也就是資料庫無法幫我檢查user輸入的日期格式是否正確, 就變成要依賴程式在user輸入時做日期格式的檢查
想請教各位, 當你們遇到日期欄位可不填, 但為了提高搜索效能須將它設成不允許null並且加入index, 有什麼好的做法嗎? 謝謝
已邀請的邦友 {{ invite_list.length }}/5
NULL 一樣可以建立index, 一樣可以在查詢條件中使用index.
create table it220703a (
id int unsigned not null auto_increment primary key
, val1 int unsigned not null
, val2 int unsigned
, dt1 date not null
, dt2 date
);
------
insert into it220703a(val1, val2, dt1, dt2)
with t1 as (
select 1
from information_schema.keywords k1
, information_schema.keywords k2
)
select ceil(rand() * 600000)
, ceil(rand() * 60000)
, date_add('2000-01-01', interval ceil(rand() * 6000) day)
, date_add('2000-01-01', interval ceil(rand() * 3000) day)
from t1;
Query OK, 544644 rows affected
----
with t1(tid) as (
select ceil(rand() * 600000)
from information_schema.keywords
)
update it220703a
set val2 = null
where id in (select tid from t1);
Query OK, 669 rows affected (0.03 sec)
---
with t1(tid) as (
select ceil(rand() * 600000)
from information_schema.keywords
)
update it220703a
set dt2 = null
where id in (select tid from t1);
Query OK, 665 rows affected (0.02 sec)
-------
create index idx_val2 on it220703a(val2);
create index idx_dt2 on it220703a(dt2);
-----
explain
select count(*)
from it220703a
where val2 is null\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: it220703a
partitions: NULL
type: ref
possible_keys: idx_val2
key: idx_val2
key_len: 5
ref: const
rows: 669
filtered: 100.00
Extra: Using where; Using index
---
explain
select count(*)
from it220703a
where dt2 is null\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: it220703a
partitions: NULL
type: ref
possible_keys: idx_dt2
key: idx_dt2
key_len: 4
ref: const
rows: 665
filtered: 100.00
Extra: Using where; Using index
---
select *
from it220703a
where dt2 is null
limit 1;
+-----+--------+------+------------+------+
| id | val1 | val2 | dt1 | dt2 |
+-----+--------+------+------------+------+
| 365 | 578037 | 5331 | 2009-02-07 | NULL |
+-----+--------+------+------------+------+
select version();
+-----------+
| version() |
+-----------+
| 8.0.26 |
+-----------+
謝謝你,因為以往在網路上看到很多說法是說欄位允許NULL值將不走索引,而昨天又看到另一種說法,是說如果索引只有一個欄位且允許NULL還是會走索引,就如同你的測試結果;但如果是在複合索引中使用NULL將不走索引,不過我今天測試之後發現,即便複合索引中某欄位是允許NULL,一樣也會執行索引,我用的MYSQL版本是8.0.28。
我在想會不會是MYSQL以前確實會因NULL而不執行索引,但隨著技術的進步以及優化,現在已經不再有這種問題了,但從前的人以當時的情況來講,他們也沒錯?
如果現在允許NULL都不影響索引執行的話,那是否設計資料表的思維就會有所改變?又或者NULL在某些情況下仍會影響索引的執行或查詢效能,只是我們沒有測到或是沒發現到?
網路上會有很多資料,但要驗證.
看來,你是因為某種規範說建議不要是null。所以你的日期欄位設計成不能是null,而非其它限制,比如資料庫你無權變更之類。建議你,就把日期欄位設成可 null。凡事有取捨。縱然資料庫欄位本身建議不要null,但是將程式流程綜合起來,卻又要多花心力,多耗費資源,那不如就設為null.
正確解答就是一級屠豬士大大的解答無誤
建 INDEX, 日期欄位允許 NULL 值
如果你堅心要日期欄位在UI上非必填, 但在資料表裡不允許它是null, 並且要加入INDEX以提高查詢效能, 要如何設計?
那我選方法1
原因是
我覺得 Not Null在提高查詢效能這件事上
可能還比不上 Not duplicate
另外
順帶一提
MySQL 的日期範圍是'1000-01-01' to '9999-12-31'
你會選方法一 ? 所以如果有100個查詢語法會用到這個欄位, 你會寫100次 SELECT IF(myDate = '1000-01-01', '', myDate) myDate, ... ? 重複又枯燥的做法, 我以為這是最不會有人選的。
我的需求裡, 日期欄位是可以有相同的日期, 所以沒有Not duplicate的限制, 比如出生年月日的欄位, 會員資料一定允許同年同月同日生的人
順帶一提, 我用的MYSQL版本是8.0.28, DateTime或Date型別是可以寫入0001-01-01, 見附圖 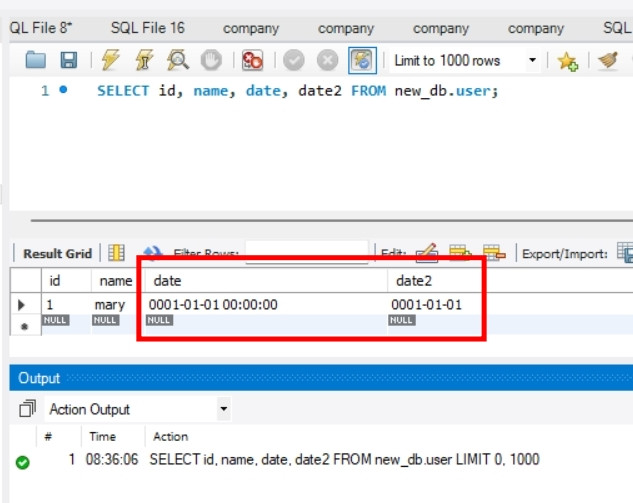
所以如果有100個查詢語法會用到這個欄位, 你會寫100次 SELECT IF(myDate = '1000-01-01', '', myDate) myDate, ... ?
這是在你的設計前提下做的選擇
我是不會寫100次的
因為
我不會設計出這種資料表/UI
可以用 view, 就不用到處改.保持一致性,不怕漏掉.
依據我過去的經驗,如果存入的是只有日期的話,那麼欄位預設就會是varchar(),如果需要計算,就在SQL裡面轉換資料型別來進行計算,而且我記得資料庫應該只有Datetime,沒有單純的日期吧(印象中),而且資料庫處理Datetime會比varchar還要耗時間。(前提是你有先設定varchar的長度)
而要判斷這個日期的資料是不是正確,正確應該是在前端輸入的時候(假設前端是HTTP),在判斷資料內容是不是正確的時候就應該要有這個日期判斷函式,同時在前端判斷是不是允許空值。因為你一定會有一個程式在前端判斷輸入的資料是不是日期;否則你輸入一個不是日期的資料,你就一定會有問題;這問題可能是在資料轉換的時候出錯,也有可能在資料庫處理的時候出錯。
順帶一提幾個觀念和資訊安全有關:1.資料內容輸入正確必須要在使用者輸入端就進行判斷,不應該丟到後面去處理,這個是SQL injection的防禦手法之一。2.資料庫的錯誤不可以傳到前端,否則你的資料庫格式和架構就會被外部人士知道。
資料欄位設定為varchar,就可以預設填入空值'',而不是null,你的前端輸入的資料,拋到SQL應該要空值而不是null,這樣你的資料庫就不會有null的問題。(我想你應該有null 與空值不相同的觀念。)
依照這樣的設計觀念,你的資料庫就可以將這個欄位用index來加速運算,但前提是你要知道怎麼依照你的查詢語法來組織index。
我也看過有人將日期資料存成字串, 但就是日期檢查這件事變成要依賴程式, 如果程式檢查沒做好, 資料庫本身也無法驗證日期, 就有可能存進去非正確格式資料的風險。感覺上是各有利弊
MySQL有Date的型別! 可以只存 2022-01-01 , 你可以試試
說到安全性, 我會前後端都做驗證, 光靠前端驗證並不安全(只能防君子不防小人), 因為有個東西叫做瀏覽器內建的開發者工具, 在它面前, 前端驗證將視為無物~
RE: (我想你應該有null 與空值不相同的觀念。) 當然知道~ 我的第一段都講了:「所以通常像是varchar的欄位若非必填, 可設預設值為''」
謝謝你的分享, 我也是想看看有多少人用字串來儲存日期。不過"一級屠豬士"的測試結果。讓我有了明確的想法, 現在的MYSQL, 即使是NULL值一樣可以走索引, 效能不減
我現在才看到你的資料庫是用MySQL,原來MySQL還有單純日期的型別。
以前(十幾年前),我們在寫這個程式,日期的部分都會用varchar來儲存,不過日期的格式都是固定,用YYYYMMDD的格式,在MSSQL本身就有函式可以做轉換,雖然有時候麻煩點,但覺得還好。
而且那時候用Group的時候還挺好用的,比如說寫個Group by left(YYYYMMDD,6), 就可以依月份來排序了。
那時候用MSSQL,語法還是SQL2000,也許現在在MySQL上面可以有不一樣的做法也不一定。
關聯式資料庫(以MySQL為例) 建議欄位值不允許null
我懷疑這句話是寫反了,Mysql 的預設值是 null 的。
舉例來說,如果您下這道指令(Mysql)
CREATE TABLE Persons (
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);
既不指定是null , 也不指定是 not null , 它建立出來的預設就是 null。
這是 mysqldump 出來的結果,每個欄位都加上了【NULL DEFAULT NULL】語句。
DROP TABLE IF EXISTS `Persons`;
CREATE TABLE `Persons` (
`PersonID` int(11) NULL DEFAULT NULL,
`LastName` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`FirstName` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`Address` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`City` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
null 是個好東西,我個人非常喜歡,不過我的工程師很害怕 null , 他所建的每個欄位,都要費心指定 not null。
我覺得這要分成兩個觀點去看,預設值歸預設值,建議做法歸建議做法。sql把預設值設成null很合理,因為它並不知道每個人心中的預設值是多少,故先設成null,再讓設計者去改成他想要的。至於為什麼會有所謂"建議盡量不用Null",這是因為它可能會造成效能的問題,我不知道你對資料庫效能有多少著墨,或是在不在乎效能這件事,你不妨試著google這個關鍵字: mysql null 效能
做為一名程式設計師,【效能的問題】需要實測,而不是人云亦云,照單全收。
我測試了一個330萬筆的資料,其中對日期欄位分別做了null和not null二次select ... where 測試,效能絲毫沒有影響。
我不知道您是怎麼測試出 null 欄位會『造成效能的問題』?可以舉例說明嗎?
Null可以index,該鍵值全當空值來排序,unique index下就只能一個NULL
要增加查詢速度,可以在主索引外多增幾組可能使用的index即可
既然表單允許NULL,那麼DB欄位也就改成可以NULL,這樣比較一致
值得一提的是:不建議NULL的原因是...
NULL和所有的資料邏輯運算(and/or/=/<>...)答案都是NULL,不會是True也不會是False(是甚麼?我不知道!),要特別用isnull/isnotnull處理,這會增加Where或程式撰寫的複雜度
如果這個欄位有可能被搜尋,設成Not Null,初始值一律先給""(空值或0,但不是NULL,我的DB允許這麼做)
