想請教各位關於排序上可以優化的方式,目前有一個table如下圖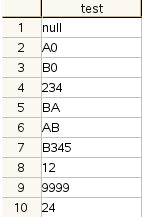
想要排序的順序為 先null->英文(只要英文就是要先排序)->數字
最終的結果應該如下圖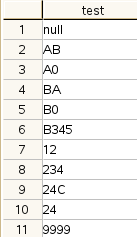
目前自己下的語法如下(用Teradata資料庫)
sel test,
CASE WHEN trim(nvl(test,''))='' THEN 0
WHEN substr(test,1,1) BETWEEN 'A' AND 'Z' THEN 1 ELSE 2 END T1,
CASE WHEN substr(test,2,1) BETWEEN 'A' AND 'Z' THEN 0 ELSE 1 END T2,
CASE WHEN substr(test,3,1) BETWEEN 'A' AND 'Z' THEN 0 ELSE 1 END T3,
CASE WHEN substr(test,4,1) BETWEEN 'A' AND 'Z' THEN 0 ELSE 1 END T4
FROM PSTAGE_DVM.TEST
ORDER BY T1||substr(test,1,1)||T2||substr(test,2,1)||T3||substr(test,3,1)||T4||substr(test,4,1)
但是知道這樣會很影響效能,目前還在思考可以優化的方式
故想請教各位如果是這種特殊排序是否有更好的優化方式 謝謝!
已邀請的邦友 {{ invite_list.length }}/5
可以用空間換時間
建立一個欄位代表 Priority 在新增 & 更新資料異動此 Priority
--null->英文->數字
null = 0
英文 = 1
數字 = 2
上面建立一個 Index 效能理論會提升
使用PostgreSQL
CREATE COLLATION ithelp1010_weird (
PROVIDER = 'icu',
LOCALE = 'en-u-kr-space-latn-digit'
);
create table it221010 (
id int primary key
, test text
);
insert into it221010 values
(1, 'AB'),(2, '12'), (3, 'BX'), (4, NULL), (5, '34'), (6, '');
select *
from it221010
order by test COLLATE ithelp1010_weird nulls first;
id test
4 null
6
1 AB
3 BX
2 12
5 34
以下是用 MSSQL 的做法
也提供給你參考看看
drop table if exists TestData
create table TestData(
test nvarchar(100)
);
insert into TestData
values (null), ('A0'), ('B0'), ('234'), ('BA'), ('AB'), ('B345'), ('12'), ('9999'), ('24')
GO
select [test]
from TestData
order by IIF(test like '[a-zA-Z]%' or test is null, 0, 1)
我比較直,不改動資料庫,只用ORDER BY CASE .... WHEN ... END 一行搞定
用公司的800多現職員工來做例子
SELECT * FROM EMPLOYEE
WHERE QUITDATE IS NULL
ORDER BY CASE LEFT(EMPCNAME,1) WHEN '許' THEN 0 WHEN '吳' THEN 1 ELSE 3 END
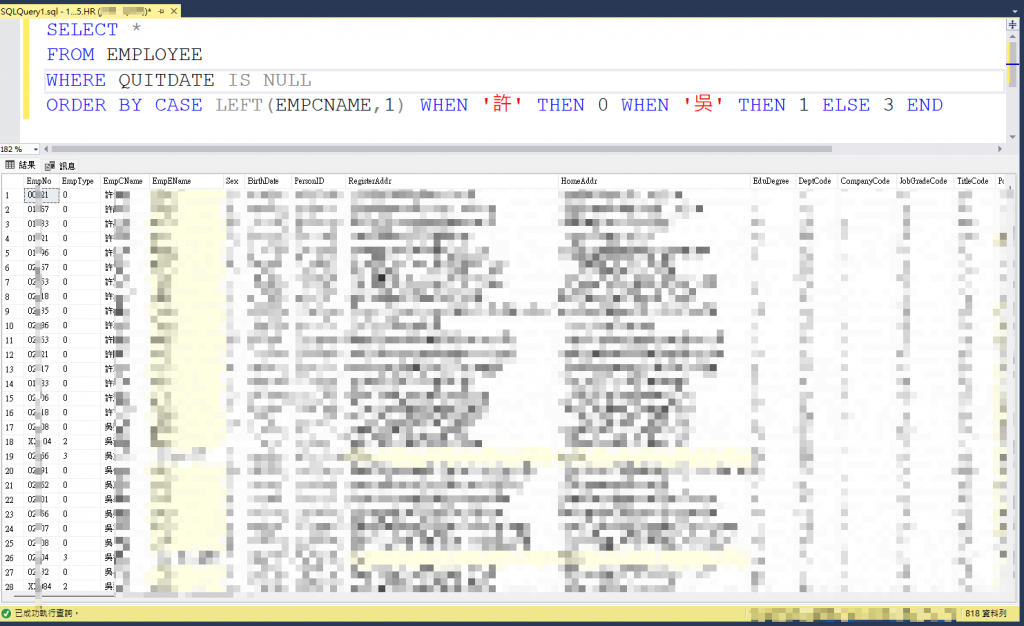
你的問題比照辦理,做成視圖view即可
