我這程式碼是使用預訓練模型如InceptionV3、VGG16等做狗的品種分類,但我運行時遇到一個很奇妙的問題,在訓練集、驗證集的結果都很不錯,有達到95%以上,但 當我自己使用資料測試並將結果輸出到EXCEL時,有些種類是全答對(我輸入A的圖片答B),有些種類是全答錯(我輸入B的圖片答C,或C的出現率非常高 ),我懷疑是在編碼時的順序出了問題,我不論使用InceptionV3、VGG16都得到類似的結果,但我實在找不出問題出在哪裡,將前面的資料Print出來順序也都是對的, 不知是哪裡出了問題
上傳bloodhood的圖片全錯,老實說這沒甚麼,但神奇的是,我找很多不同的bloodhood的圖片,跑出來都是一樣的結果,都是french bulldog,也就是說他是能辨認出來的
目前測15個,有兩個是對的,其他狀況都一樣,我找同品種不同的照片,都能辨識出來,但是是錯的結果
也就是說: 如果原本給A要答B,但今天我輸入了10張A的圖片,得到的都是C,不是說有B有C有D這樣,他錯得很一致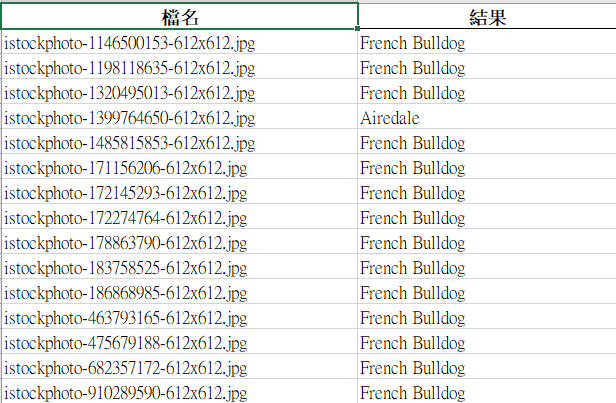
上傳Airedale的圖片全對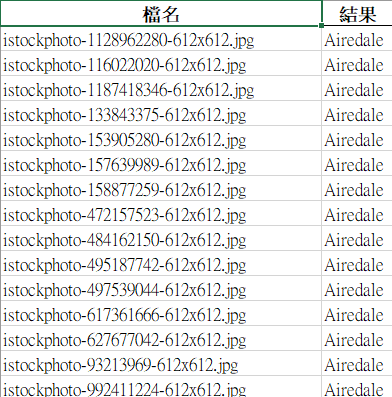
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 讀取標籤檔案
labels_df = pd.read_csv("./archive/dogs.csv")
# 選定類別
selected_breeds = ["Airedale", "Beagle", "Bloodhound", "Bluetick", "Chihuahua", "Collie", "Dingo",
"French Bulldog", "German Sheperd", "Malinois", "Newfoundland", "Pekinese",
"Pomeranian", "Pug", "Vizsla"]
# 篩選所需類別
filtered_labels = labels_df[labels_df['labels'].isin(selected_breeds)]
# 將訓練集、驗證集、測試集分割
train_df = filtered_labels[filtered_labels['data set']=='train'].copy()
test_df = filtered_labels[filtered_labels['data set']=='test'].copy()
valid_df = filtered_labels[filtered_labels['data set']=='valid'].copy()
# 資料集路徑
data_dir = "./archive/"
# 資料預處理
label_encoder = LabelEncoder()
train_df['encoded_labels'] = label_encoder.fit_transform(train_df['labels']).astype(str)
valid_df['encoded_labels'] = label_encoder.transform(valid_df['labels']).astype(str)
# 構建完整的檔案路徑
train_df['filepaths'] = data_dir + train_df['filepaths']
valid_df['filepaths'] = data_dir + valid_df['filepaths']
test_df['filepaths'] = data_dir + test_df['filepaths']
# 使用ImageDataGenerator進行數據增強和載入
datagen = ImageDataGenerator(
rescale=1./255,
)
train_generator = datagen.flow_from_dataframe(
train_df,
x_col='filepaths',
y_col='encoded_labels',
target_size=(224, 224),
batch_size=32,
class_mode='sparse'
)
val_generator = datagen.flow_from_dataframe(
valid_df,
x_col='filepaths',
y_col='encoded_labels',
target_size=(224, 224),
batch_size=32,
class_mode='sparse'
)
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Dropout
from tensorflow.keras.optimizers import RMSprop,Adam
from sklearn.model_selection import train_test_split
from tensorflow.keras.regularizers import l2
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.applications import InceptionV3
# 使用 VGG16 預訓練模型
# base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 使用 InceptionV3 預訓練模型
base_model = InceptionV3(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 凍結預訓練模型的權重
for layer in base_model.layers:
layer.trainable = False
# #逐次降低學習率
# def lr_scheduler(epoch):
# return 0.0005 * pow(0.9, epoch // 5)
# lr_schedule = LearningRateScheduler(lr_scheduler)
# 建立新的模型,添加全連接層
model = Sequential()
model.add(base_model)
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(15, activation='softmax'))
model.summary()
# 編譯模型
model.compile(optimizer = RMSprop(learning_rate=0.0001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 訓練模型
model.fit(train_generator, epochs=25, validation_data=val_generator)
# 使用測試集進行預測
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_dataframe(
test_df,
x_col='filepaths',
target_size=(224, 224),
batch_size=32,
class_mode=None,
shuffle=False
)
predictions = model.predict(test_generator)
# 使用驗證集進行性能評估
val_metrics = model.evaluate(val_generator)
# 取得 Accuracy
val_accuracy = val_metrics[1]
# 印出 Accuracy
print("Validation Set Accuracy: {:.2f}%".format(val_accuracy * 100))
import os
import pandas as pd
import numpy as np
from tensorflow.keras.preprocessing import image
from PIL import Image
# 檔案夾路徑
testing_data_folder = "./test_data3/Bloodhound"
# 檔名列表
file_names = [f for f in os.listdir(testing_data_folder) if f.endswith('.jpg')]
# 建立 DataFrame
result_df = pd.DataFrame({'檔名': file_names})
# 製作測試資料集
test_data = []
# 收集預測機率的列表
probabilities = []
for file_name in file_names:
img_path = os.path.join(testing_data_folder, file_name)
img = Image.open(img_path)
img = img.resize((224, 224))
img_array = image.img_to_array(img)
img_array = img_array / 255.0 # 歸一化
test_data.append(img_array)
test_data = np.array(test_data)
# 使用模型進行預測
predictions = model.predict(test_data)
# 類別名稱
# class_names = ["Airedale", "Beagle", "Bloodhound", "Bluetick", "Chihuahua", "Collie", "Dingo",
# "Bloodhound", "German Sheperd", "Malinois", "Newfoundland", "Pekinese",
# "Pomeranian", "Pug", "Vizsla"]
# class_names = ["Airedale", "Beagle", "Bloodhound", "Bluetick", "Chihuahua", "Collie", "Dingo",
# "French Bulldog", "German Sheperd", "Malinois", "Newfoundland", "Pekinese",
# "Pomeranian", "Pug", "Vizsla"]
# 印出訓練集中每個類別的編碼
print(predictions)
# 使用預測結果對應到的類別標籤
predicted_labels = label_encoder.inverse_transform(predictions.argmax(axis=1))
# 將預測結果加入 DataFrame
result_df['結果'] = predicted_labels
# 將結果保存到 Excel 文件
result_df.to_excel("test_data.xlsx", index=False)
print("結果已成功輸出到 test_data.xlsx 檔案中。")
已邀請的邦友 {{ invite_list.length }}/5
我自己的思路會是
如果bloodhood本來就不準然後Airedale學得很好,有你現在遇到的狀況感覺蠻合理的

 iThome鐵人賽
iThome鐵人賽