<em>[<a href="forum.php?mod=forumdisplay&fid=95&filter=typeid&typeid=716">999</a>]</em> <a href="forum.php?mod=viewthread&tid=168399999&extra=page%3D988%26filter%3Ddateline%26orderby%3Ddateline" onclick="if (!window.__cfRLUnblockHandlers) return false; atarget(this)" class="s xst">【自购】【13.23G/2V】附 TVB 布兰迪·爱</a>-
[阅读权限 <span class="xw1">
我的正則
a href="forum\.php\?mod=viewthread.*?atarget\(this\)" class="s xst">(.*?)</a>
到這邊沒問題
可以取出【自购】【13.23G/2V】附 TVB 布兰迪·爱
但是有一個關鍵條件是他的
[阅读权限 <span class="xw1">
這個是在a標籤的下一行有這個關鍵字串才算完整符合條件
不知道這則該如何寫?正則表達式可以這樣把下一行必須是什麼來作為匹配條件嗎?
請教各位大神了
不指定下一行是 [阅读权限 可以正確匹配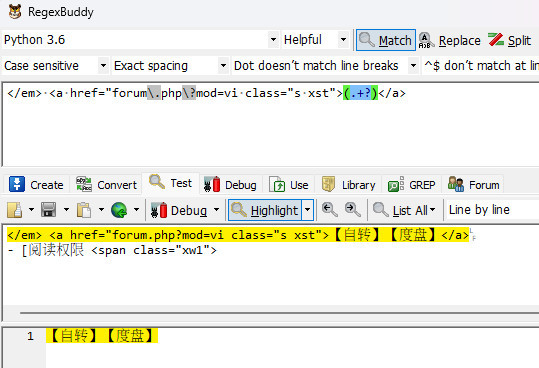
加入\n[阅读权限 還是匹配不到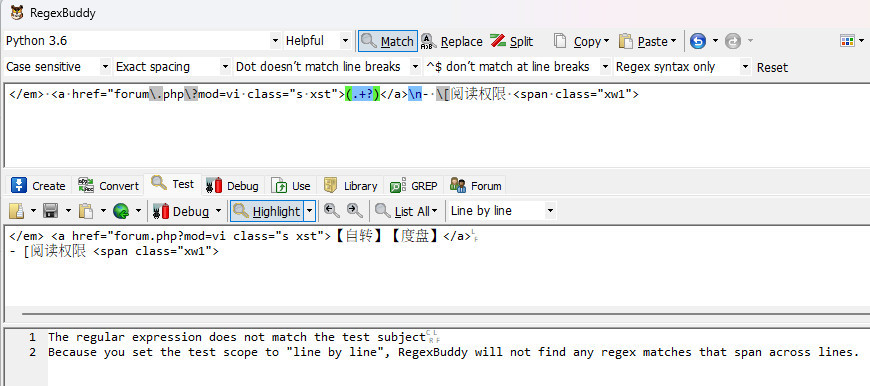
已邀請的邦友 {{ invite_list.length }}/5
換行就一樣用 '\n' 表示, 像是這樣:
>>> s1 = 'hello\nworld'
>>> print(s1)
hello
world
>>> import re
>>> m = re.search(r'o\nw', s1)
>>> m
<re.Match object; span=(4, 7), match='o\nw'>
>>> m.group(0)
'o\nw'
建議你用 raw string 表示規則表達式, 可以減少使用一大堆 '\' 的麻煩。
不指定下一行是 [阅读权限 可以正確匹配
加入\n[阅读权限 還是匹配不到
這跟換行不見得有關係。
我建議你不要用正則去寫,就是因為很有可能會有換行和不換行兩種狀況都存在的情形。用CSS selector寫會比較準。
另外用正則寫就原本的規則加上你後面閱讀權限那些字而已。
但這僅限你直接把網頁原始碼當作字串做正則去找的狀況,用playwright去找,可能會因為他的api內部處理找不到。
加入\n[阅读权限 還是匹配不到
應該是你在\n後少了一個"空格" 我測試是可以的喔 範例如下:
source="""
<em>[<a href="forum.php?mod=forumdisplay&fid=95&filter=typeid&typeid=716">999</a>]</em> <a href="forum.php?mod=viewthread&tid=168399999&extra=page%3D988%26filter%3Ddateline%26orderby%3Ddateline" onclick="if (!window.__cfRLUnblockHandlers) return false; atarget(this)" class="s xst">【权限】【13.23G/2V】附 TVB 布兰迪·爱</a>-
[阅读权限 <span class="xw1">
=====
<em>[<a href="forum.php?mod=forumdisplay&fid=95&filter=typeid&typeid=716">999</a>]</em> <a href="forum.php?mod=viewthread&tid=168399999&extra=page%3D988%26filter%3Ddateline%26orderby%3Ddateline" onclick="if (!window.__cfRLUnblockHandlers) return false; atarget(this)" class="s xst">【無限】【99.99G/9V】附 ABC 爱·布兰迪</a>-
<span class="xw1">
=====
<em>[<a href="forum.php?mod=forumdisplay&fid=95&filter=typeid&typeid=716">999</a>]</em> <a href="forum.php?mod=viewthread&tid=168399999&extra=page%3D988%26filter%3Ddateline%26orderby%3Ddateline" onclick="if (!window.__cfRLUnblockHandlers) return false; atarget(this)" class="s xst">【無限】【99.99G/9V】附 ABC 爱·布兰迪</a>-
LOLLOL<span class="xw1">
"""
import re
ls = re.findall(r'<a href=".*?" .*?>(.*?)</a>-',source)
print('全部',ls) #全部
ls = re.findall(r'<a href=".*?" .*?>(.*?)</a>-\n \[阅读权限',source)
print('只列有权',ls) #只列有阅读权限
ls = re.findall(r'<a href=".*?" .*?>(.*?)</a>-\n[^ \[]',source)
print('只列無权',ls) #只列無阅读权限
輸出結果:
全部 ['【权限】【13.23G/2V】附 TVB 布兰迪·爱', '【無限】【99.99G/9V】附 ABC 爱·布兰迪', '【無限】【99.99G/9V】附 ABC 爱·布兰迪']
只列有权 ['【权限】【13.23G/2V】附 TVB 布兰迪·爱']
只列無权 ['【無限】【99.99G/9V】附 ABC 爱·布兰迪', '【無限】【99.99G/9V】附 ABC 爱·布兰迪']
中括號[]裡面用^開頭的話是反匹配的意思,在上列的範例中 -\n[^ \[]' 就是換行之後第一個字元不可以是空格或[
希望有幫助~
謝謝froce大的幫忙解答.
後來這個正則我換了一個方法搞定了.
先用source_str = re.sub(r'\n', '', response)把所有患行把所有換行符都拿掉了.可以匹配成功.但是匹配出來的東西也不是我要的.因為他會匹配過多其他不是我要的進來.
所以看來這個需求用正則會很累.
您是對的.
也要感謝ccutmis大的幫忙測試.
任何幫忙對我都一定是有幫助的.
from bs4 import BeautifulSoup
soup = BeautifulSoup(r'<em>[<a href="forum.php?mod=forumdisplay&fid=95&filter=typeid&typeid=716">999</a>]</em> <a href="forum.php?mod=viewthread&tid=168399999&extra=page%3D988%26filter%3Ddateline%26orderby%3Ddateline" onclick="if (!window.__cfRLUnblockHandlers) return false; atarget(this)" class="s xst">【自购】【13.23G/2V】附 TVB 布兰迪·爱</a>-[阅读权限 <span class="xw1">', "html.parser")
a = soup.select("a.xst[href*='viewthread']")
res = [link for link in a if link.next_sibling.text == "-[阅读权限 "]
print(res)
怎麼會用正則去直接爬?用CSS selector比較方便吧?
froce大我是用CSS去爬沒錯.但是CSS會爬回所有主題.但是我想要過濾掉一些需要閱讀權限的主題不要爬取.觀察了後發現有閱讀權限的跟沒閱讀權限的差異就在a標籤後多了這行-[阅读权限 所以才想用正則過濾調一些需要閱讀權限的主題.
回到正題:請問froce大正則表達式是不是不能指定下一行一定要什麼的這種條件?
我知道可以指定關鍵字的前面或後面一定是要什麼字符串.
但是指定下一行一定要什麼的內容.我好像也沒看過這樣的教學.
你一定要用正則的話,把下一行也一起列入正則規則就好...
雖然我個人還是建議用next_sibling去篩。
請問froce大如何把下一行也加入到正則的條件去呢?
我有使用你的程式碼res = [link for link in a if link.next_sibling.text == "-[阅读权限 "]但是沒辦法找到目標.他這個結構怪怪的.所以我才想說用正則來取.
剛好也想知道正則是不是可以這樣使用(加入下一行做判斷條件)
page.goto(url)
# 执行你需要的操作
page.get_by_text('请点此进入').click()
page.wait_for_load_state("networkidle")
response = page.content()
print(response)
# 来源字符串(假设有多个匹配项)
source_str = response
# 正则表达式
# 正则表达式,允许跨行匹配
pattern = r'<a href="forum\.php\?mod=viewthread.*?atarget\(this\)" class="s xst">(.*?)</a>.+?[阅读权限 <span class="xw1">"'
# 使用 re.findall() 提取所有匹配的关键字
matches = re.findall(pattern, source_str , re.DOTALL)
# 初始化空列表并扩展匹配结果
keywords_list = []
keywords_list.extend(matches)
# 打印结果
print(f'提取的关键字列表: {keywords_list}')
https://playwright.dev/docs/other-locators#css-matching-elements-based-on-layout
你用playwright,那可能更不用寫正則了。
"a.xst[href*='viewthread']:left-of(:text('-[阅读权限 '))"
我原本以為你是對網頁原始碼做正則
我是對網頁原始碼做正則處理沒錯.
主要是挑選出一些帶有"閱讀權限"的帖子出來
找到這些帶有閱讀權限的帖子找出來後還要取到這個主題的名稱
將這個主題加入到排除爬取的清單中.