恩~遇到一個不知道如何用純SQL寫法的當月排班班別區間
只能想到用T-SQL來達成寫法...
先給前置資料的SQL
declare @Shift table(
Name nvarchar(20)
,SetDate date
,Code nvarchar(5)
)
insert into @Shift
values('小明','2024/10/1','A'),('小明','2024/10/2','A'),('小明','2024/10/3','A'),('小明','2024/10/4','A')
,('小明','2024/10/5','休'),('小明','2024/10/6','休'),('小明','2024/10/7','A'),('小明','2024/10/8','A')
,('小明','2024/10/9','A'),('小明','2024/10/10','休'),('小明','2024/10/11','A'),('小明','2024/10/12','休')
,('小明','2024/10/13','休'),('小明','2024/10/14','B'),('小明','2024/10/15','B'),('小明','2024/10/16','B')
,('小明','2024/10/17','B'),('小明','2024/10/18','B'),('小明','2024/10/19','休'),('小明','2024/10/20','休')
,('小明','2024/10/21','A'),('小明','2024/10/22','A'),('小明','2024/10/23','A'),('小明','2024/10/24','A')
,('小明','2024/10/25','A'),('小明','2024/10/26','休'),('小明','2024/10/27','休'),('小明','2024/10/28','A')
,('小明','2024/10/29','A'),('小明','2024/10/30','A'),('小明','2024/10/31','A')
,('大白','2024/10/1','特'),('大白','2024/10/2','特'),('大白','2024/10/3','B'),('大白','2024/10/4','B')
,('大白','2024/10/5','休'),('大白','2024/10/6','休'),('大白','2024/10/7','B'),('大白','2024/10/8','B')
,('大白','2024/10/9','B'),('大白','2024/10/10','休'),('大白','2024/10/11','B'),('大白','2024/10/12','休')
,('大白','2024/10/13','休'),('大白','2024/10/14','A'),('大白','2024/10/15','A'),('大白','2024/10/16','A')
,('大白','2024/10/17','A'),('大白','2024/10/18','A'),('大白','2024/10/19','休'),('大白','2024/10/20','休')
,('大白','2024/10/21','B'),('大白','2024/10/22','B'),('大白','2024/10/23','B'),('大白','2024/10/24','B')
,('大白','2024/10/25','B'),('大白','2024/10/26','休'),('大白','2024/10/27','休'),('大白','2024/10/28','B')
,('大白','2024/10/29','B'),('大白','2024/10/30','B'),('大白','2024/10/31','B')
--A代表 08-16 早班時段
--B代表 13-21 午班時段
--想要的結果:
--大白 , B:1~13、A:14~20、B:21~31
--小明 , A:1~13、B:14~20、A:21~31
我用T-SQL後,得到此結果~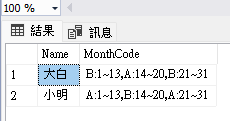
看有哪位高手比較厲害的SQL寫法...^^
我再分享我寫的T-SQL
好像我表達的不好~我貼出T-SQL好了~看如何改善成為純SQL
我也把直轉橫列出~比較看得懂..
select *
from (
select Name
,day(SetDate) DayNum
,Code
from @Shift
) k
pivot (
max(Code)
for DayNum in(
[1],[2],[3],[4],[5],[6],[7],[8],[9],[10]
,[11],[12],[13],[14],[15],[16],[17],[18]
,[19],[20],[21],[22],[23],[24],[25],[26]
,[27],[28],[29],[30],[31]
)
) p

T-SQL語法的寫法....0.0
declare @ShiftMonth table(
Name nvarchar(20)
,MonthCode nvarchar(max)
)
declare @ShiftName table(
Sort int
,Name nvarchar(20)
)
declare @ShiftSet table(
Name nvarchar(20)
,SetDate date
,Code nvarchar(5)
,LastDate date
,LastCode nvarchar(5)
)
declare @Count int = 0
declare @Code nvarchar(5) = ''
declare @LastCode nvarchar(5) = ''
declare @StartDate date,@EndDate date
declare @UpdStartDate date,@UpdEndDate date
declare @i int = 0,@n int=0
declare @MonthCode nvarchar(max) = ''
declare @MonthStart date = '2024/10/1'
declare @MonthEnd date = dateadd(day,-1,dateadd(month,1,@MonthStart))
insert into @ShiftName
select Row_Number()Over(order by Name) Sort
,Name
from @Shift
where SetDate between @MonthStart and @MonthEnd
group by Name
declare @NameCount int = isNull((select count(0) from @ShiftName),0)
declare @Name nvarchar(20)
declare @k int = 0
while(@k<@NameCount)
begin
set @k = @k + 1
select @Name=Name
from @ShiftName
where Sort = @k
insert into @ShiftSet
select *
,isNull((
select top 1 b.SetDate
from @Shift b
where a.Name = b.Name
and Code not in('休','特')
and a.SetDate < b.SetDate
),a.SetDate) LastDay
,isNull((
select top 1 b.Code
from @Shift b
where a.Name = b.Name
and Code not in('休','特')
and a.SetDate < b.SetDate
),a.Code) LastCode
from @Shift a
where Code not in('休','特')
and Name = @Name
set @i = 0
set @n = 0
set @Count = isNull((select count(0) from @ShiftSet),0)
set @MonthCode = ''
set @StartDate = @MonthStart
while(@i<@Count)
begin
set @i = @i + 1
if(@i=1)
begin
select top 1 @EndDate=LastDate
,@Code=Code
,@LastCode=LastCode
from @ShiftSet
order by SetDate
end
select @UpdStartDate=SetDate
,@UpdEndDate=dateadd(day,-1,LastDate)
,@Code=Code
,@LastCode=LastCode
from (
select Row_Number()Over(order by SetDate) Sort
,*
from @ShiftSet
) k
where Sort = @i
and Code<>LastCode
if(@Code<>@LastCode)
begin
set @n = @n + 1
set @EndDate = @UpdEndDate
if(@MonthCode='')
begin
set @MonthCode = Convert(varchar,@Code) + ':' + Convert(varchar,Day(@StartDate)) + '~' + Convert(varchar,Day(@EndDate))
end
else
begin
set @MonthCode = @MonthCode + ',' + Convert(varchar,@Code) + ':' + Convert(varchar,Day(@StartDate)) + '~' + Convert(varchar,Day(@EndDate))
end
set @StartDate = dateadd(day,1,@EndDate)
set @Code = @LastCode
end
end
if(@Count>0)
begin
select @EndDate=max(SetDate)
from @Shift
where Name = @Name
if(@MonthCode='')
begin
set @MonthCode = Convert(varchar,@Code) + ':' + Convert(varchar,Day(@StartDate)) + '~' + Convert(varchar,Day(@EndDate))
end
else
begin
set @MonthCode = @MonthCode + ',' + Convert(varchar,@Code) + ':' + Convert(varchar,Day(@StartDate)) + '~' + Convert(varchar,Day(@EndDate))
end
insert into @ShiftMonth
select @Name
,@MonthCode
delete from @ShiftSet
end
end
select *
from @ShiftMonth
10/14號更新
謝謝 一級屠豬士 用 WITH 方式提醒
原來 WITH 的用法,是會繼承上個資料表的查詢,生成獨立的資料表
謝謝 rogeryao、pilipala 想法,將排班的班別改為連續班別,會比較簡單判斷
由其知道 2022 有個新函數【IGNORE NULLS】更簡單應用填入班別
我這個SQL版本比較舊是2016版本,有些新函數不能使用~只能寫比較多SQL來查詢了@@..
經改善的SQL如下,謝謝三位高手的指導~
WITH
NewShift as (
select Name
,SetDate
,isNull((
select top 1 b.Code
from @Shift b
where a.Name = b.Name
and b.Code not in(N'特',N'休')
and a.SetDate >= b.SetDate
order by b.SetDate desc
),(
select top 1 b.Code
from @Shift b
where a.Name = b.Name
and b.Code not in(N'特',N'休')
and a.SetDate < b.SetDate
order by b.SetDate desc
)) Code
from @Shift a
)
,CTE01 AS (
SELECT M.Name,M.SetDate,M.Code
,1 + SUM(M.Num) OVER (PARTITION BY M.Name ORDER BY M.SetDate) AS No
FROM (
SELECT NewShift.*,
CASE WHEN Code = LAG(Code,1,Code) OVER (PARTITION BY Name ORDER BY SetDate) THEN 0 ELSE 1 END AS Num
FROM NewShift
) M
)
,CTE02 AS (
SELECT Name,Code,No
,Min(SetDate) AS MinDate
,Max(SetDate) AS MaxDate
FROM CTE01
GROUP BY Name,Code,No
)
,CTE03 AS (
SELECT Name,No,Code
,Code+':'+Right(MinDate,2)+'~'+Right(MaxDate,2) AS PartStr
FROM CTE02
)
SELECT Name
,stuff((
select ',' + PartStr
from CTE03 b
where a.Name = b.Name
order by no
for xml path('')
),1,1,'') as AllStr
--,STRING_AGG(PartStr,',') WITHIN GROUP (ORDER BY No) AS AllStr
FROM CTE03 a
GROUP BY Name
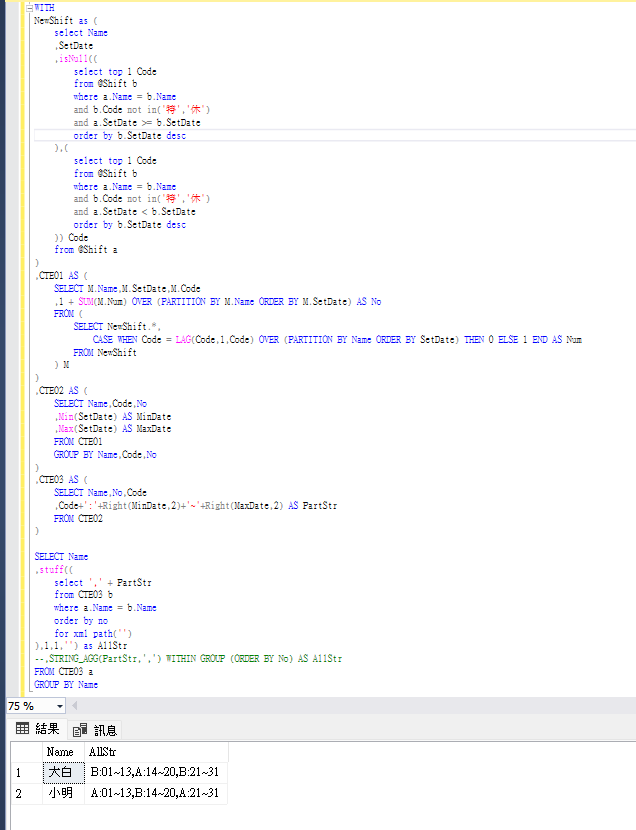
謝謝 rogeryao 再次測試
國外網站 db<>fiddle 測試,因為文化特性要補上 N 來修正語言問題
已邀請的邦友 {{ invite_list.length }}/5
with t1 as (
select boy, sdate
, case when code = '休' or code = '特' then null
else code
end
from it1013
), t2 as (
select *
, sum(case when code is null then 0 else 1 end) over(order by boy, sdate) as code_grp
from t1
), t3 as (
select boy, sdate
, first_value(code) over(partition by code_grp order by sdate) as new_code
from t2
), t4 as (
select boy, sdate, new_code
, sum(case when new_code is null then 0 else 1 end) over(order by boy, sdate desc) as new_code_grp
from t3
), t5 as (
select boy, sdate
, first_value(new_code) over(partition by new_code_grp order by sdate desc) as new_code2
from t4
), t6 as (
select boy, sdate
, new_code2
, lag(new_code2) over(partition by boy order by sdate) lagcode
from t5
), t7 as (
select boy, sdate, new_code2 as code
, case when new_code2 = 'A' and lagcode = 'B' then true
when new_code2 = 'B' and lagcode = 'A' then true
else false
end as cut
from t6
), t8 as (
select boy, sdate, code, date_part('day', sdate)::int as cutdate
from t7
where cut
or date_part('day', sdate)::int = 1
), t9 as (
select boy, code, cutdate, coalesce(lead(cutdate) over (partition by boy order by sdate) - 1, 31) as enddate
from t8
) , t10 as (
select boy
, cutdate
, code || ':' || cutdate::text || '~' || enddate::text as datestr
from t9
)
select boy
, string_agg(datestr, ',' order by cutdate)
from t10
group by boy;
result:
boy | string_agg
------+------------------------
大白 | B:1~13,A:14~20,B:21~31
小明 | A:1~13,B:14~20,A:21~31
(2 rows)
完整的應該是在 coalesce(lead(cutdate) over (partition by boy order by sdate) - 1, 31)
這裡的31 要用日期函數計算出當月的最後一天.
但是我們使用的DB 不同, 這對純真的人大大來說,小菜一碟,所以我就偷懶直接使用31了.
挖~~SQL化厲害~
正常流程應該是,理論班表 => 實際出勤班表 => 幫 HR 勾稽兩者異常之處,讓 HR 去釐清判斷是否合理
休假日前後是 A、B 班別時,有邏輯可以判斷是歸屬哪個班別嗎?
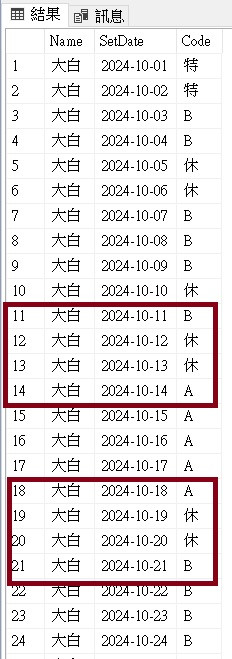
班別是若遇當月休假換班別~就歸屬前一個班別~
例如 10/13 休 14/14 換成A班
那麼 10/13 會往前 抓到 最後一天的班別 若是B班~
那麼10/13就算B班薪資
但是像月初就特休就會往後抓班別來判斷
至於HR勾稽~他們輪班比較沒辦做吧~
因為他們要排下個月班時~
會一個組討論~哪天誰可以上班~誰有事休假~
過年是沒有休假的~用輪班處理(會給特別加班費)
我這個題目範例是用固定排班來敘述的~
不是用輪班比較麻煩輸入@@...
Step1:把特、休字樣改成所屬班別,使用 SQL 2022 視窗函數新參數 IGNORE NULLS 來整理
Step2:連續日期、連續班別來判斷群組
Step3:產生對應需求的資料
;
WITH T1 AS
(
SELECT * ,
IIF(Code IN ('A' , 'B') , Code , NULL) AS NewCode
FROM @Shift
)
, T2 AS
(
SELECT * ,
COALESCE(
NewCode ,
LAG(NewCode) IGNORE NULLS OVER (PARTITION BY Name ORDER BY SetDate) ,
LEAD(NewCode) IGNORE NULLS OVER (PARTITION BY Name ORDER BY SetDate)) AS GroupNO
FROM T1
)
, T3 AS
(
SELECT
* ,
DATEADD(
d ,
ROW_NUMBER() OVER (PARTITION BY Name , GroupNO ORDER BY SetDate) * -1 ,
SetDate) AS GroupDate
FROM T2
)
, T4 AS
(
SELECT
T3.Name ,
T3.GroupDate ,
T3.GroupNO ,
MIN(SetDate) AS MinDate ,
T3.GroupNO + ':' + CAST(DAY(MIN(SetDate)) AS varchar(2)) + '~' + CAST(DAY(MAX(SetDate)) AS varchar(2)) AS CodeInfo
FROM T3
GROUP BY Name , GroupDate , GroupNO
)
SELECT
Name ,
STRING_AGG(CodeInfo , ' , ') WITHIN GROUP (ORDER BY MinDate)
FROM T4
GROUP BY Name
喔~了解~
你採用的是刪除特、休,改為Null值
利用 SQL 2022新視窗函數 IGNORE NULLS 填滿 上次日期的班別
再利用連續班別,算出區段~
我的SQL版本比較舊~
所以重點就是變成連續班別填滿,SQL就會比較簡單
Code : 只有班別代號,不含休假或特休
CREATE TABLE da (
Name nvarchar(20),
SetDate date,
Code nvarchar(5));
INSERT INTO da (Name, SetDate,Code) VALUES
(N'小明','2024/10/1','A'),(N'小明','2024/10/2','A'),(N'小明','2024/10/3','A'),(N'小明','2024/10/4','A')
,(N'小明','2024/10/5',N'A'),(N'小明','2024/10/6',N'A'),(N'小明','2024/10/7','A'),(N'小明','2024/10/8','A')
,(N'小明','2024/10/9','A'),(N'小明','2024/10/10',N'A'),(N'小明','2024/10/11','A'),(N'小明','2024/10/12',N'A')
,(N'小明','2024/10/13',N'A'),(N'小明','2024/10/14','B'),(N'小明','2024/10/15','B'),(N'小明','2024/10/16','B')
,(N'小明','2024/10/17','B'),(N'小明','2024/10/18','B'),(N'小明','2024/10/19',N'B'),(N'小明','2024/10/20',N'B')
,(N'小明','2024/10/21','A'),(N'小明','2024/10/22','A'),(N'小明','2024/10/23','A'),(N'小明','2024/10/24','A')
,(N'小明','2024/10/25','A'),(N'小明','2024/10/26',N'A'),(N'小明','2024/10/27',N'A'),(N'小明','2024/10/28','A')
,(N'小明','2024/10/29','A'),(N'小明','2024/10/30','A'),(N'小明','2024/10/31','A')
,(N'大白','2024/10/1',N'B'),(N'大白','2024/10/2',N'B'),(N'大白','2024/10/3','B'),(N'大白','2024/10/4','B')
,(N'大白','2024/10/5',N'B'),(N'大白','2024/10/6',N'B'),(N'大白','2024/10/7','B'),(N'大白','2024/10/8','B')
,(N'大白','2024/10/9','B'),(N'大白','2024/10/10',N'B'),(N'大白','2024/10/11','B'),(N'大白','2024/10/12',N'B')
,(N'大白','2024/10/13',N'B'),(N'大白','2024/10/14','A'),(N'大白','2024/10/15','A'),(N'大白','2024/10/16','A')
,(N'大白','2024/10/17','A'),(N'大白','2024/10/18','A'),(N'大白','2024/10/19',N'A'),(N'大白','2024/10/20',N'A')
,(N'大白','2024/10/21','B'),(N'大白','2024/10/22','B'),(N'大白','2024/10/23','B'),(N'大白','2024/10/24','B')
,(N'大白','2024/10/25','B'),(N'大白','2024/10/26',N'B'),(N'大白','2024/10/27',N'B'),(N'大白','2024/10/28','B')
,(N'大白','2024/10/29','B'),(N'大白','2024/10/30','B'),(N'大白','2024/10/31','B');
WITH CTE01 AS (SELECT M.Name,M.SetDate,M.Code,1 + SUM(M.Num) OVER (
PARTITION BY M.Name ORDER BY M.SetDate) AS No
FROM (
SELECT da.*,
CASE WHEN Code = LAG(Code,1,Code) OVER (
PARTITION BY Name ORDER BY SetDate) THEN 0 ELSE 1 END AS Num
FROM da) M),
CTE02 AS (
SELECT Name,Code,No,Min(SetDate) AS MinDate,Max(SetDate) AS MaxDate
FROM CTE01
GROUP BY Name,Code,No),
CTE03 AS (
SELECT Name,No,Code,Code+':'+Right(MinDate,2)+'~'+Right(MaxDate,2) AS PartStr
FROM CTE02)
SELECT Name,STRING_AGG(PartStr,',') WITHIN GROUP (ORDER BY No) AS AllStr
FROM CTE03
GROUP BY Name
休假或特休
CREATE TABLE dc (
Name nvarchar(20),
SetDate date,
Holiday nvarchar(5));
INSERT INTO dc (Name, SetDate,Holiday) VALUES
(N'小明','2024/10/5',N'休'),
(N'小明','2024/10/6',N'休'),
(N'小明','2024/10/10',N'休'),
(N'小明','2024/10/12',N'休'),
(N'小明','2024/10/13',N'休'),
(N'小明','2024/10/19',N'休'),
(N'小明','2024/10/20',N'休'),
(N'小明','2024/10/26',N'休'),
(N'小明','2024/10/27',N'休'),
(N'大白','2024/10/1',N'特'),
(N'大白','2024/10/2',N'特'),
(N'大白','2024/10/5',N'休'),
(N'大白','2024/10/6',N'休'),
(N'大白','2024/10/10',N'休'),
(N'大白','2024/10/12',N'休'),
(N'大白','2024/10/13',N'休'),
(N'大白','2024/10/19',N'休'),
(N'大白','2024/10/20',N'休'),
(N'大白','2024/10/26',N'休'),
(N'大白','2024/10/27',N'休');
SELECT F.Name,F.SetDate,F.Holiday,1 + SUM(F.HNum) OVER (
PARTITION BY F.Name ORDER BY F.SetDate) AS HNo
FROM (
SELECT dc.*,
CASE WHEN Holiday = LAG(Holiday,1,Holiday) OVER (
PARTITION BY Name ORDER BY SetDate) THEN 0 ELSE 1 END AS HNum
FROM dc) F
Demo
休假或特休 dc 與 da left join 應該可以產生出圖二,
此處 SQL 只便於找出休假或特休群組,不在贅述。
Code 可以包含 休、特的解法在底下回應區 :『修正版』
喔~
你採用沒有混合休假的排班~
純粹班別哪到哪~的確是很好查詢
休假有另外的資料表紀錄在混合進來~
可惜他們班表功能是這樣混合的
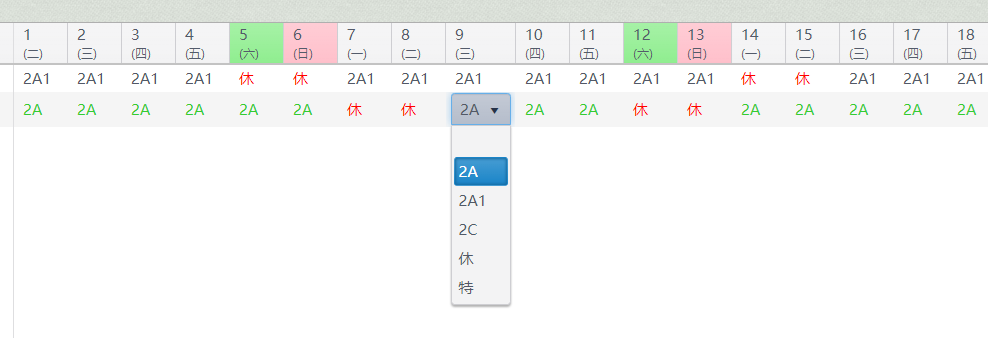
班別是若遇當月休假換班別~就歸屬前一個班別~
例如 10/13 休 14/14 換成A班
那麼 10/13 會往前 抓到 最後一天的班別 若是B班~
那麼10/13就算B班薪資
『那麼 10/13 會往前 抓到 最後一天的班別 若是B班~』
其實,這樣的論述可能是有問題的
一般來說應該是先有排班表,不同的班別薪資也會不一樣
10/13 請假時排到什麼班表,就扣除那個班表的錢
而不是往前推最後一次有上班的班表
仔細算薪資會有差別
或許有一天會發生
10/13 往前推是 B 班
但是人事部門算薪資時是用 A 班計算
這個就看人資訂下規則為準囉(通常會發公告,或者寫在員工手冊裡面)~
我們看他怎麼解釋~就怎樣設定了~
Code 可以包含 休、特
CREATE TABLE da (
Name nvarchar(20),
SetDate date,
Code nvarchar(5));
INSERT INTO da (Name, SetDate,Code) VALUES
(N'小明','2024/10/1','A'),(N'小明','2024/10/2','A'),(N'小明','2024/10/3','A'),(N'小明','2024/10/4','A')
,(N'小明','2024/10/5',N'休'),(N'小明','2024/10/6',N'休'),(N'小明','2024/10/7','A'),(N'小明','2024/10/8','A')
,(N'小明','2024/10/9','A'),(N'小明','2024/10/10',N'休'),(N'小明','2024/10/11','A'),(N'小明','2024/10/12',N'休')
,(N'小明','2024/10/13',N'休'),(N'小明','2024/10/14','B'),(N'小明','2024/10/15','B'),(N'小明','2024/10/16','B')
,(N'小明','2024/10/17','B'),(N'小明','2024/10/18','B'),(N'小明','2024/10/19',N'休'),(N'小明','2024/10/20',N'休')
,(N'小明','2024/10/21','A'),(N'小明','2024/10/22','A'),(N'小明','2024/10/23','A'),(N'小明','2024/10/24','A')
,(N'小明','2024/10/25','A'),(N'小明','2024/10/26',N'休'),(N'小明','2024/10/27',N'休'),(N'小明','2024/10/28','A')
,(N'小明','2024/10/29','A'),(N'小明','2024/10/30','A'),(N'小明','2024/10/31','A')
,(N'大白','2024/10/1',N'特'),(N'大白','2024/10/2',N'特'),(N'大白','2024/10/3','B'),(N'大白','2024/10/4','B')
,(N'大白','2024/10/5',N'休'),(N'大白','2024/10/6',N'休'),(N'大白','2024/10/7','B'),(N'大白','2024/10/8','B')
,(N'大白','2024/10/9','B'),(N'大白','2024/10/10',N'休'),(N'大白','2024/10/11','B'),(N'大白','2024/10/12',N'休')
,(N'大白','2024/10/13',N'休'),(N'大白','2024/10/14','A'),(N'大白','2024/10/15','A'),(N'大白','2024/10/16','A')
,(N'大白','2024/10/17','A'),(N'大白','2024/10/18','A'),(N'大白','2024/10/19',N'休'),(N'大白','2024/10/20',N'休')
,(N'大白','2024/10/21','B'),(N'大白','2024/10/22','B'),(N'大白','2024/10/23','B'),(N'大白','2024/10/24','B')
,(N'大白','2024/10/25','B'),(N'大白','2024/10/26',N'休'),(N'大白','2024/10/27',N'休'),(N'大白','2024/10/28','B')
,(N'大白','2024/10/29','B'),(N'大白','2024/10/30','B'),(N'大白','2024/10/31','B');
-- 每月 1 日'休'、'特', 找到第一個班別向上補
WITH CTE01 AS (
SELECT da.Name,da.SetDate,
CASE WHEN da.SetDate < K.SetDate THEN K.Code ELSE da.Code END AS Code
FROM da
LEFT JOIN (
SELECT * FROM (
SELECT Row_Number() OVER (PARTITION BY Name ORDER BY SetDate) AS RN,*
FROM da
WHERE Code IN ('A','B')) AS K
WHERE RN =1
) AS K ON K.Name=da.Name),
-- 向下補班別
CTE02 AS (
SELECT Row_Number() OVER (PARTITION BY Name ORDER BY SetDate) AS id,
Name,SetDate,
CASE WHEN Code NOT IN ('A','B') THEN NULL ELSE Code END AS CodeX
FROM CTE01),
--
CTE03 AS (
SELECT step_l.Name,step_l.SetDate,step_2.CodeX as Code
FROM (
SELECT id,Name,SetDate,CodeX,
SUM(CASE WHEN CodeX IS NULL THEN 0 ELSE 1 END) OVER (PARTITION BY Name ORDER BY SetDate) as rank_id
FROM CTE02) as step_l
LEFT JOIN (
SELECT id,Name,SetDate,CodeX,
Row_Number() OVER (PARTITION BY Name ORDER BY SetDate) AS join_id
FROM CTE02 WHERE CodeX IS NOT NULL) as step_2
ON step_l.Name = step_2.Name
AND step_l.rank_id = step_2.join_id),
-- Code 內無'休'、'特'
CTE04 AS (SELECT M.Name,M.SetDate,M.Code,1 + SUM(M.Num) OVER (
PARTITION BY M.Name ORDER BY M.SetDate) AS No
FROM (
SELECT CTE03.*,
CASE WHEN Code = LAG(Code,1,Code) OVER (
PARTITION BY Name ORDER BY SetDate) THEN 0 ELSE 1 END AS Num
FROM CTE03) M),
CTE05 AS (
SELECT Name,Code,No,Min(SetDate) AS MinDate,Max(SetDate) AS MaxDate
FROM CTE04
GROUP BY Name,Code,No),
CTE06 AS (
SELECT Name,No,Code,Code+':'+Right(MinDate,2)+'~'+Right(MaxDate,2) AS PartStr
FROM CTE05)
SELECT Name,STRING_AGG(PartStr,',') WITHIN GROUP (ORDER BY No) AS AllStr
FROM CTE06
GROUP BY Name
收到 2016 新寫法了~謝謝!
我今天測試你的寫法~(班別向上補及班別向下補)
left join效能比較好~
用子查詢的方式~跑1萬多筆很久快1分鐘都沒結果(我按中止)
用left join查詢,1萬多筆滿馬上就出現了^_^
早上本想請你測試執行速度的差異
真是心有靈犀
哈~畢竟改程式都有先後順序~
要等我有時間~才能空處理~
你寫的這種『子查詢』方式
我幾乎不使用,都改用 LEFT JOIN 處理
直覺上他是針對每一筆下一道 SQL
你可以用 SQL Server Profiler 看看
2 個 SQL的差異
子查詢其實弊端很大~
因為他是針對每一筆~
另開資料表總查詢~
所以跑很久~
LEFT JOIN 是先把總表處理好,在比對join有沒有而已~
因為他不是獨立去查詢的~所以會比較快
今天有試了 WITH + 加上用你的
WITH
略....
LEFT JOIN (
略......
) AS K
跑了一個歷史打卡資料看看(4萬多筆),結果跑了22秒...0.0a
後來想了一下~可能WITH會不斷遞迴關係~
我就移出 WITH 外面
用 declare @Tmp table 暫存一個資料表~1秒左右就跑完了@@...
declare @Tmp table
略....
insert into @Tmp
略....
LEFT JOIN (
略......
) AS K
WITH
略....
可能WITH會不斷遞迴關係~
應該不會吧
WITH 只是把原本一大串的 SQL分段處理
就上面的 Case 而言也可以寫成一大串,但是可讀性就變差了,
除錯也會變得很困難
歷史打卡資料的問題或許跟上面的 Case 有些差異
但是你硬把 SQL 套進去
可能就會不如預期吧
剛想到上面的 SQL 有個小瑕疵:
-- 向下補班別
CTE02 AS (
SELECT Row_Number() OVER (PARTITION BY Name ORDER BY SetDate) AS id,
CTE03 AS (
...
SELECT id,Name,SetDate,CodeX,
...
SELECT id,Name,SetDate,CodeX,
這個 id 是多餘的
另外,有個潛藏的問題
PARTITION BY Name
應該要改成下式,要加入年月(2024-10)
PARTITION BY Name,Left(SetDate,7)
否則,當只查詢一個人而且跨月時會有問題。
原本是(小明、大白,10月)
大白 2024-10-01 特
大白 2024-10-02 特
取代 休、特
大白 2024-10-01 B
大白 2024-10-02 B
................................................
當(大白,9~10月)
取代 休、特會變成
大白 2024-10-01 A
大白 2024-10-02 A
A 是 9月延伸而產生的
Demo:問題示範
『修正版』
CREATE TABLE da (
Name nvarchar(20),
SetDate date,
Code nvarchar(5));
INSERT INTO da (Name, SetDate,Code) VALUES
(N'大白','2024/09/1','A'),(N'大白','2024/09/2','A'),(N'大白','2024/09/3','A'),(N'大白','2024/09/4','A')
,(N'大白','2024/09/5',N'休'),(N'大白','2024/09/6',N'休'),(N'大白','2024/09/7','A'),(N'大白','2024/09/8','A')
,(N'大白','2024/09/9','A'),(N'大白','2024/09/10',N'休'),(N'大白','2024/09/11','A'),(N'大白','2024/09/12',N'休')
,(N'大白','2024/09/13',N'休'),(N'大白','2024/09/14','B'),(N'大白','2024/09/15','B'),(N'大白','2024/09/16','B')
,(N'大白','2024/09/17','B'),(N'大白','2024/09/18','B'),(N'大白','2024/09/19',N'休'),(N'大白','2024/09/20',N'休')
,(N'大白','2024/09/21','A'),(N'大白','2024/09/22','A'),(N'大白','2024/09/23','A'),(N'大白','2024/09/24','A')
,(N'大白','2024/09/25','A'),(N'大白','2024/09/26',N'休'),(N'大白','2024/09/27',N'休'),(N'大白','2024/09/28','A')
,(N'大白','2024/09/29','A'),(N'大白','2024/09/30','A')
,(N'大白','2024/10/1',N'特'),(N'大白','2024/10/2',N'特'),(N'大白','2024/10/3','B'),(N'大白','2024/10/4','B')
,(N'大白','2024/10/5',N'休'),(N'大白','2024/10/6',N'休'),(N'大白','2024/10/7','B'),(N'大白','2024/10/8','B')
,(N'大白','2024/10/9','B'),(N'大白','2024/10/10',N'休'),(N'大白','2024/10/11','B'),(N'大白','2024/10/12',N'休')
,(N'大白','2024/10/13',N'休'),(N'大白','2024/10/14','A'),(N'大白','2024/10/15','A'),(N'大白','2024/10/16','A')
,(N'大白','2024/10/17','A'),(N'大白','2024/10/18','A'),(N'大白','2024/10/19',N'休'),(N'大白','2024/10/20',N'休')
,(N'大白','2024/10/21','B'),(N'大白','2024/10/22','B'),(N'大白','2024/10/23','B'),(N'大白','2024/10/24','B')
,(N'大白','2024/10/25','B'),(N'大白','2024/10/26',N'休'),(N'大白','2024/10/27',N'休'),(N'大白','2024/10/28','B')
,(N'大白','2024/10/29','B'),(N'大白','2024/10/30','B'),(N'大白','2024/10/31','B')
,(N'小明','2024/10/1','A'),(N'小明','2024/10/2','A'),(N'小明','2024/10/3','A'),(N'小明','2024/10/4','A')
,(N'小明','2024/10/5',N'休'),(N'小明','2024/10/6',N'休'),(N'小明','2024/10/7','A'),(N'小明','2024/10/8','A')
,(N'小明','2024/10/9','A'),(N'小明','2024/10/10',N'休'),(N'小明','2024/10/11','A'),(N'小明','2024/10/12',N'休')
,(N'小明','2024/10/13',N'休'),(N'小明','2024/10/14','B'),(N'小明','2024/10/15','B'),(N'小明','2024/10/16','B')
,(N'小明','2024/10/17','B'),(N'小明','2024/10/18','B'),(N'小明','2024/10/19',N'休'),(N'小明','2024/10/20',N'休')
,(N'小明','2024/10/21','A'),(N'小明','2024/10/22','A'),(N'小明','2024/10/23','A'),(N'小明','2024/10/24','A')
,(N'小明','2024/10/25','A'),(N'小明','2024/10/26',N'休'),(N'小明','2024/10/27',N'休'),(N'小明','2024/10/28','A')
,(N'小明','2024/10/29','A'),(N'小明','2024/10/30','A'),(N'小明','2024/10/31','A');
-- 分割年月
WITH CTE00 AS (
SELECT Name,LEFT(SetDate,7) AS 'YM',SetDate,Code
FROM da),
-- 每月 1 日'休'、'特', 找到第一個班別向上補
CTE01 AS (
SELECT CTE00.Name,CTE00.YM,CTE00.SetDate,
CASE WHEN CTE00.SetDate < K.SetDate THEN K.Code ELSE CTE00.Code END AS Code
FROM CTE00
LEFT JOIN (
SELECT * FROM (
SELECT Row_Number() OVER (PARTITION BY Name,YM ORDER BY SetDate) AS RN,*
FROM CTE00
WHERE Code IN ('A','B')) AS K
WHERE RN =1
) AS K ON K.Name=CTE00.Name AND K.YM=CTE00.YM),
-- 向下補班別
CTE02 AS (
SELECT Name,SetDate,YM,
CASE WHEN Code NOT IN ('A','B') THEN NULL ELSE Code END AS CodeX
FROM CTE01),
--
CTE03 AS (
SELECT step_l.Name,step_l.YM,step_l.SetDate,step_2.CodeX as Code
FROM (
SELECT Name,YM,SetDate,CodeX,
SUM(CASE WHEN CodeX IS NULL THEN 0 ELSE 1 END) OVER (PARTITION BY Name,YM ORDER BY SetDate) as rank_id
FROM CTE02) as step_l
LEFT JOIN (
SELECT Name,YM,SetDate,CodeX,
Row_Number() OVER (PARTITION BY Name,YM ORDER BY SetDate) AS join_id
FROM CTE02 WHERE CodeX IS NOT NULL) as step_2
ON step_l.Name = step_2.Name
AND step_l.YM = step_2.YM
AND step_l.rank_id = step_2.join_id),
-- Code 內無'休'、'特'
CTE04 AS (
SELECT M.Name,M.YM,M.SetDate,M.Code,1 + SUM(M.Num) OVER (
PARTITION BY M.Name,M.YM ORDER BY M.SetDate) AS No
FROM (
SELECT CTE03.*,
CASE WHEN Code = LAG(Code,1,Code) OVER (
PARTITION BY Name,YM ORDER BY SetDate) THEN 0 ELSE 1 END AS Num
FROM CTE03) M),
CTE05 AS (
SELECT Name,YM,Code,No,Min(SetDate) AS MinDate,Max(SetDate) AS MaxDate
FROM CTE04
GROUP BY Name,YM,Code,No),
CTE06 AS (
SELECT Name,YM,No,Code,Code+':'+Right(MinDate,2)+'~'+Right(MaxDate,2) AS PartStr
FROM CTE05)
/*
SELECT Name,YM,STRING_AGG(PartStr,',') WITHIN GROUP (ORDER BY No) AS AllStr
FROM CTE06
GROUP BY Name,YM
*/
SELECT Name,YM
,stuff((
select ',' + PartStr
from CTE06 b
where a.Name = b.Name and a.YM = b.YM
order by no
for xml path('')
),1,1,'') as AllStr
FROM CTE06 a
GROUP BY Name,YM
那句SQL要用在跨月列出的話
我知道怎樣改~就加上跨月條件
Row_Number() OVER (PARTITION BY Name,format(SetDate,'yyyy-MM') ORDER BY SetDate) AS id
--在此join條件加上跨月
LEFT JOIN (
略......
) AS K on format(a.SetDate,'yyyy-MM') = format(k.SetDate,'yyyy-MM')
你的跨月寫法也是滿有趣的~
Left(SetDate,7)
然後~列出跑秒數過久的SQL好了~
昨天講錯了~是當月排班列出
跑21秒的SQL
declare @StartDate date = '2024/10/1'
,@DNO varchar(20) = 'xxx'
declare @EndDate date = dateadd(day,-1,dateadd(month,1,@StartDate))
declare @Shift table(
GroupName nvarchar(50)
,PNo nvarchar(50)
,PName nvarchar(50)
,SetDate date
,Code nvarchar(10)
)
insert into @Shift
略.....(當月排班)
;WITH
NewShift as (
select a.GroupName
,a.PNo
,a.PName
,a.SetDate
,isNull((
CASE WHEN a.SetDate > K1.SetDate THEN k1.Code ELSE (case when a.Code in(N'特',N'休') then null else a.Code end) END
),(
CASE WHEN a.SetDate < K2.SetDate THEN k2.Code ELSE a.Code END
)) Code
from @Shift a
left join (
select *
from (
SELECT Row_Number() OVER (PARTITION BY PNO ORDER BY b.SetDate ) AS RN
,*
FROM @Shift b
WHERE b.Code not in(N'特',N'休')
) k
where RN = 1
) k1 on a.PNo = k1.PNo
left join (
select *
from (
SELECT Row_Number() OVER (PARTITION BY PNO ORDER BY b.SetDate desc) AS RN
,*
FROM @Shift b
WHERE b.Code not in(N'特',N'休')
) k
where RN = 1
) k2 on a.PNo = k2.PNo
)
,CTE01 AS (
select GroupName
,PNo
,PName
,M.SetDate
,M.Code
,1 + SUM(M.Num) OVER (PARTITION BY M.PNo ORDER BY M.SetDate) AS No
FROM (
SELECT a.*,
CASE WHEN Code = LAG(Code,1,Code) OVER (PARTITION BY PNo ORDER BY SetDate) THEN 0 ELSE 1 END AS Num
FROM NewShift a
) M
)
,CTE02 AS (
select GroupName
,PNo
,PName
,Code
,No
,Min(SetDate) AS MinDate
,Max(SetDate) AS MaxDate
FROM CTE01
GROUP BY GroupName
,PNo
,PName
,Code
,No
)
,CTE03 AS (
select GroupName
,PNo
,PName
,No
,Code
,Code+':'+Right(MinDate,2)+'~'+Right(MaxDate,2) AS PartStr
FROM CTE02
)
select GroupName
,PNo
,PName
,stuff((
select ',' + PartStr
from CTE03 b
where a.PNo = b.PNo
order by no
for xml path('')
),1,1,'') as AllStr
FROM CTE03 a
GROUP BY GroupName
,PNo
,PName

跑1秒的SQL
declare @StartDate date = '2024/10/1'
,@DNO varchar(20) = 'xxx'
declare @EndDate date = dateadd(day,-1,dateadd(month,1,@StartDate))
declare @Shift table(
GroupName nvarchar(50)
,PNo nvarchar(50)
,PName nvarchar(50)
,SetDate date
,Code nvarchar(10)
)
insert into @Shift
略.....(當月排班)
declare @NewShift table(
GroupName nvarchar(50)
,PNo nvarchar(50)
,PName nvarchar(50)
,SetDate date
,Code nvarchar(10)
)
insert into @NewShift
select a.GroupName
,a.PNo
,a.PName
,a.SetDate
,isNull((
CASE WHEN a.SetDate > K1.SetDate THEN k1.Code ELSE (case when a.Code in(N'特',N'休') then null else a.Code end) END
),(
CASE WHEN a.SetDate < K2.SetDate THEN k2.Code ELSE a.Code END
)) Code
from @Shift a
left join (
select *
from (
SELECT Row_Number() OVER (PARTITION BY PNO ORDER BY b.SetDate ) AS RN
,*
FROM @Shift b
WHERE b.Code not in(N'特',N'休')
) k
where RN = 1
) k1 on a.PNo = k1.PNo
left join (
select *
from (
SELECT Row_Number() OVER (PARTITION BY PNO ORDER BY b.SetDate desc) AS RN
,*
FROM @Shift b
WHERE b.Code not in(N'特',N'休')
) k
where RN = 1
) k2 on a.PNo = k2.PNo
;WITH
CTE01 AS (
select GroupName
,PNo
,PName
,M.SetDate
,M.Code
,1 + SUM(M.Num) OVER (PARTITION BY M.PNo ORDER BY M.SetDate) AS No
FROM (
SELECT a.*,
CASE WHEN Code = LAG(Code,1,Code) OVER (PARTITION BY PNo ORDER BY SetDate) THEN 0 ELSE 1 END AS Num
FROM @NewShift a
) M
)
,CTE02 AS (
select GroupName
,PNo
,PName
,Code
,No
,Min(SetDate) AS MinDate
,Max(SetDate) AS MaxDate
FROM CTE01
GROUP BY GroupName
,PNo
,PName
,Code
,No
)
,CTE03 AS (
select GroupName
,PNo
,PName
,No
,Code
,Code+':'+Right(MinDate,2)+'~'+Right(MaxDate,2) AS PartStr
FROM CTE02
)
select GroupName
,PNo
,PName
,stuff((
select ',' + PartStr
from CTE03 b
where a.PNo = b.PNo
order by no
for xml path('')
),1,1,'') as AllStr
FROM CTE03 a
GROUP BY GroupName
,PNo
,PName

你可以看看問題在哪裡,我只是把 NewShift 表,移到 WITH 外面,就變快了@@...
,CTE01 AS (
其實你只要測這一行以上的速度就可以了,以下的程式碼是一樣的
若是差距很大的話,我只能猜測是 SQL Sever 配置記憶體的方式不一樣,
才導致計算速度的落差
結果我~SQL一段一段的慢慢拆開測試是哪邊有問題...
結果是出在最後面@@...
;WITH
NewShift as (
略...
)
,CTE01 AS (
略...
)
,CTE02 AS (
略...
)
,CTE03 AS (
略...
)
--27位員工 * 31天 = 837筆 跑0.5秒
select GroupName
,PNo
,PName
FROM CTE03 a
GROUP BY GroupName
,PNo
,PName
--27位員工 * 31天 = 837筆 跑21秒
select GroupName
,PNo
,PName
,stuff((
select ',' + PartStr
from CTE03 b
where a.PNo = b.PNo
order by no
for xml path('')
),1,1,'') as AllStr
FROM CTE03 a
GROUP BY GroupName
,PNo
,PName
把那段子查詢註解後~速度就正常了0.0...
select GroupName
,PNo
,PName
--,stuff((
-- select ',' + PartStr
-- from CTE03 b
-- where a.PNo = b.PNo
-- order by no
-- for xml path('')
--),1,1,'') as AllStr
FROM CTE03 a
GROUP BY GroupName
,PNo
,PName
看起來~只有升級2017版後~
這個函數才能解決效率變差的問題吧@@
STRING_AGG()
你有用我的修正版跟你的最後一版
去比對資料正確性跟速度嗎?
因為我一直覺得 WITH 這一段 SQL 的邏輯怪怪的
;WITH
NewShift as
我直接套你的SQL
2筆很快~
可是筆數一多~好像就跑不完...@@
declare @StartDate date = '2024/8/1'
,@DNO varchar(20) = 'xxxx'
declare @da table(
Name nvarchar(20),
SetDate date,
Code nvarchar(5));
declare @EndDate date = dateadd(day,-1,dateadd(month,1,@StartDate))
INSERT INTO @da (Name, SetDate,Code)
略....(實際當月班別)
SELECT *
FROM @da;
-- 每月 1 日'休'、'特', 找到第一個班別向上補
WITH
CTE01 AS (
SELECT a.Name,a.SetDate,
CASE WHEN a.SetDate < K.SetDate THEN K.Code ELSE a.Code END AS Code
FROM @da a
LEFT JOIN (
SELECT * FROM (
SELECT Row_Number() OVER (PARTITION BY Name ORDER BY SetDate) AS RN,*
FROM @da
WHERE Code IN ('2A','2C','3A','3B','3C')) AS K
WHERE RN =1
) AS K ON K.Name=a.Name
)
-- 向下補班別
,CTE02 AS (
SELECT Row_Number() OVER (PARTITION BY Name ORDER BY SetDate) AS id,
Name,SetDate,
CASE WHEN Code NOT IN ('2A','2C','3A','3B','3C') THEN NULL ELSE Code END AS CodeX
FROM CTE01
)
,CTE03 AS (
SELECT step_l.Name,step_l.SetDate,step_2.CodeX as Code
FROM (
SELECT id,Name,SetDate,CodeX,
SUM(CASE WHEN CodeX IS NULL THEN 0 ELSE 1 END) OVER (PARTITION BY Name ORDER BY SetDate) as rank_id
FROM CTE02
) as step_l
LEFT JOIN (
SELECT id,Name,SetDate,CodeX,
Row_Number() OVER (PARTITION BY Name ORDER BY SetDate) AS join_id
FROM CTE02 WHERE CodeX IS NOT NULL
) as step_2
ON step_l.Name = step_2.Name
AND step_l.rank_id = step_2.join_id
)
-- Code 內無'休'、'特'
,CTE04 AS (
SELECT M.Name,M.SetDate,M.Code,1 + SUM(M.Num) OVER (PARTITION BY M.Name ORDER BY M.SetDate) AS No
FROM (
SELECT CTE03.*,
CASE WHEN Code = LAG(Code,1,Code) OVER (
PARTITION BY Name ORDER BY SetDate) THEN 0 ELSE 1 END AS Num
FROM CTE03
) M
)
,CTE05 AS (
SELECT Name,Code,No,Min(SetDate) AS MinDate,Max(SetDate) AS MaxDate
FROM CTE04
GROUP BY Name,Code,No
)
,CTE06 AS (
SELECT Name,No,Code,Code+':'+Right(MinDate,2)+'~'+Right(MaxDate,2) AS PartStr
FROM CTE05
)
SELECT Name
,stuff((
select ',' + PartStr
from CTE06 b
where a.Name = b.Name
order by no
for xml path('')
),1,1,'') as AllStr
--,STRING_AGG(PartStr,',') WITHIN GROUP (ORDER BY No) AS AllStr
FROM CTE06 a
GROUP BY Name
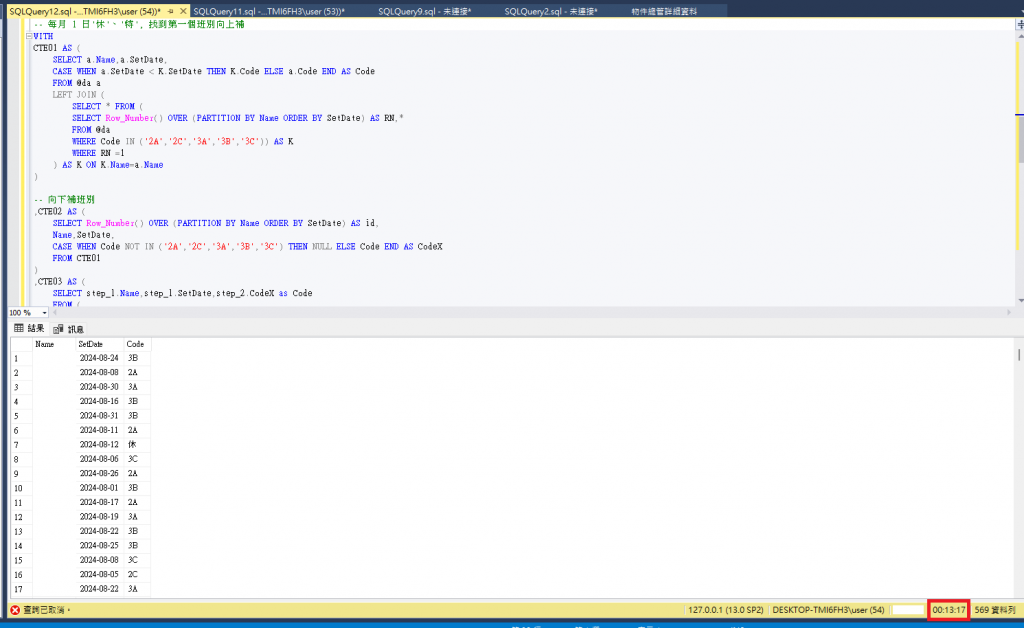
跑了13分鐘...我直接按中止查詢@@...
這內容不是我最後一版的修正版(2024-10-16 08:39:09)
修正版 內有 YM 這個欄位
後來我改成實際資料表儲存~速度就查到了@@a
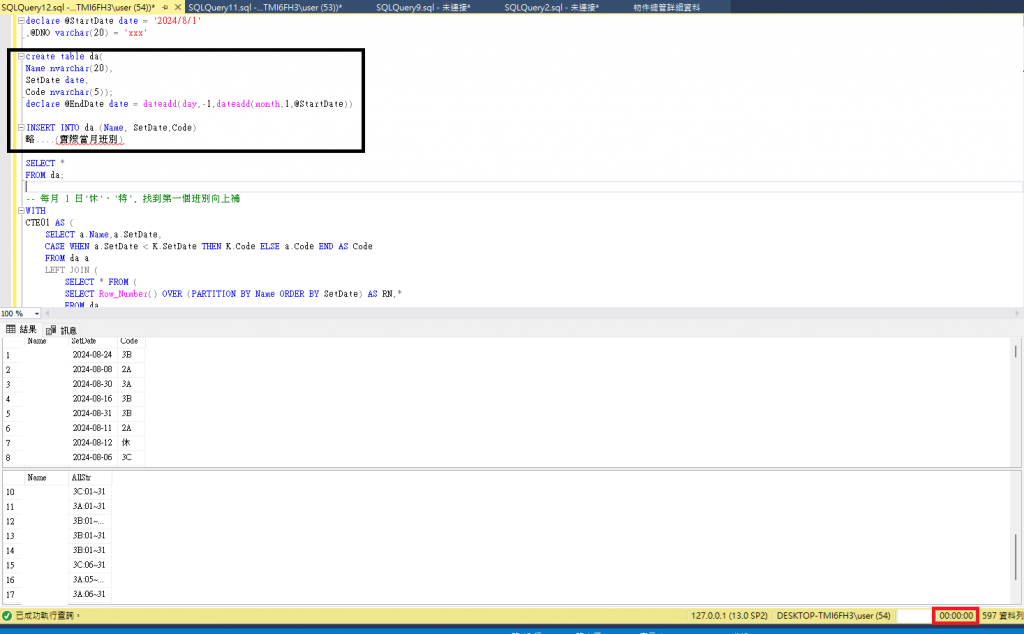
好像是因為 declare 就宣告會影響WITH效能存取..
我在試試 (2024-10-16 08:39:09) 若用 declare 是不是可以@@...
果然是 declare 宣告表格問題@@..
但是處理查詢又不能真的存表格..(因為那是很多join表格來的)
declare @StartDate date = '2024/8/1'
,@DNO varchar(20) = 'xxxx'
declare @da table(
Name nvarchar(20),
SetDate date,
Code nvarchar(5));
declare @EndDate date = dateadd(day,-1,dateadd(month,1,@StartDate))
INSERT INTO @da (Name, SetDate,Code)
略............(實際班別資料)
SELECT *
FROM @da;
-- 分割年月
WITH CTE00 AS (
SELECT Name,LEFT(SetDate,7) AS 'YM',SetDate,Code
FROM @da),
-- 每月 1 日'休'、'特', 找到第一個班別向上補
CTE01 AS (
SELECT CTE00.Name,CTE00.YM,CTE00.SetDate,
CASE WHEN CTE00.SetDate < K.SetDate THEN K.Code ELSE CTE00.Code END AS Code
FROM CTE00
LEFT JOIN (
SELECT * FROM (
SELECT Row_Number() OVER (PARTITION BY Name,YM ORDER BY SetDate) AS RN,*
FROM CTE00
WHERE Code IN ('2A','2C','3A','3B','3C')) AS K
WHERE RN =1
) AS K ON K.Name=CTE00.Name AND K.YM=CTE00.YM),
-- 向下補班別
CTE02 AS (
SELECT Name,SetDate,YM,
CASE WHEN Code NOT IN ('2A','2C','3A','3B','3C') THEN NULL ELSE Code END AS CodeX
FROM CTE01),
--
CTE03 AS (
SELECT step_l.Name,step_l.YM,step_l.SetDate,step_2.CodeX as Code
FROM (
SELECT Name,YM,SetDate,CodeX,
SUM(CASE WHEN CodeX IS NULL THEN 0 ELSE 1 END) OVER (PARTITION BY Name,YM ORDER BY SetDate) as rank_id
FROM CTE02) as step_l
LEFT JOIN (
SELECT Name,YM,SetDate,CodeX,
Row_Number() OVER (PARTITION BY Name,YM ORDER BY SetDate) AS join_id
FROM CTE02 WHERE CodeX IS NOT NULL) as step_2
ON step_l.Name = step_2.Name
AND step_l.YM = step_2.YM
AND step_l.rank_id = step_2.join_id),
-- Code 內無'休'、'特'
CTE04 AS (
SELECT M.Name,M.YM,M.SetDate,M.Code,1 + SUM(M.Num) OVER (
PARTITION BY M.Name,M.YM ORDER BY M.SetDate) AS No
FROM (
SELECT CTE03.*,
CASE WHEN Code = LAG(Code,1,Code) OVER (
PARTITION BY Name,YM ORDER BY SetDate) THEN 0 ELSE 1 END AS Num
FROM CTE03) M),
CTE05 AS (
SELECT Name,YM,Code,No,Min(SetDate) AS MinDate,Max(SetDate) AS MaxDate
FROM CTE04
GROUP BY Name,YM,Code,No),
CTE06 AS (
SELECT Name,YM,No,Code,Code+':'+Right(MinDate,2)+'~'+Right(MaxDate,2) AS PartStr
FROM CTE05)
/*
SELECT Name,YM,STRING_AGG(PartStr,',') WITHIN GROUP (ORDER BY No) AS AllStr
FROM CTE06
GROUP BY Name,YM
*/
SELECT Name,YM
,stuff((
select ',' + PartStr
from CTE06 b
where a.Name = b.Name and a.YM = b.YM
order by no
for xml path('')
),1,1,'') as AllStr
FROM CTE06 a
GROUP BY Name,YM
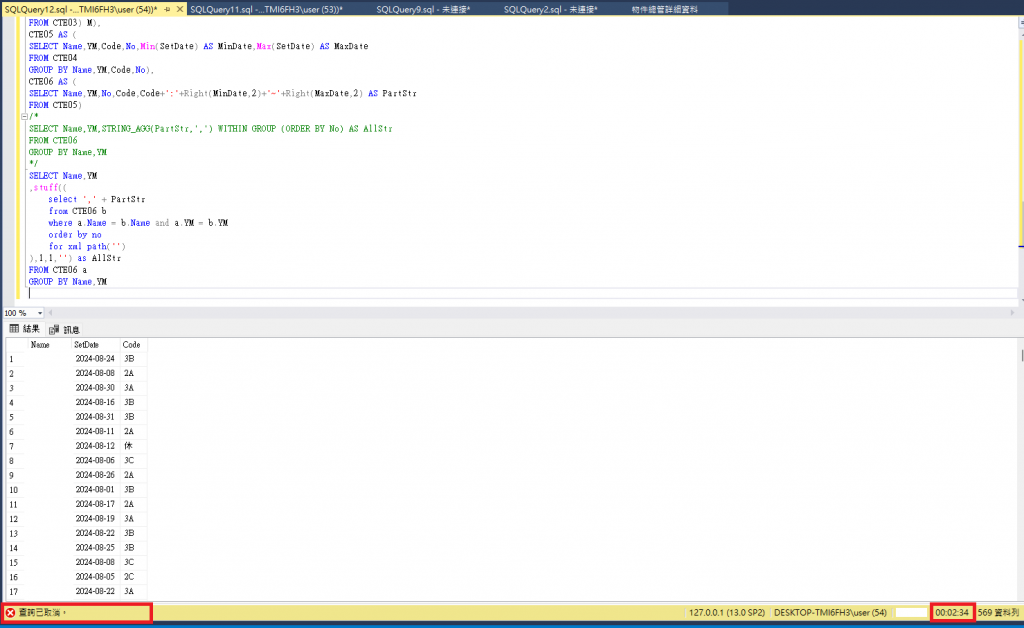
跑太久~按中止
我的解法不需要計算當月最後一天
恩~我在想想~如果存實際表格的話~
他們這個月有改班表才刷新~實際表格資料~
其他報表查詢就直接抓已紀錄的實際表格資料
剛剛~想到如果把 declare 改成宣告 暫存表格 #da
查詢速度就ok了@@~
declare @StartDate date = '2024/8/1'
,@DNO varchar(20) = 'xxx'
create table #da(
Name nvarchar(20),
SetDate date,
Code nvarchar(5));
declare @EndDate date = dateadd(day,-1,dateadd(month,1,@StartDate))
INSERT INTO #da (Name, SetDate,Code)
略.......
SELECT *
FROM #da;
-- 分割年月
WITH CTE00 AS (
SELECT Name,LEFT(SetDate,7) AS 'YM',SetDate,Code
FROM #da),
-- 每月 1 日'休'、'特', 找到第一個班別向上補
CTE01 AS (
SELECT CTE00.Name,CTE00.YM,CTE00.SetDate,
CASE WHEN CTE00.SetDate < K.SetDate THEN K.Code ELSE CTE00.Code END AS Code
FROM CTE00
LEFT JOIN (
SELECT * FROM (
SELECT Row_Number() OVER (PARTITION BY Name,YM ORDER BY SetDate) AS RN,*
FROM CTE00
WHERE Code IN ('2A','2C','3A','3B','3C')) AS K
WHERE RN =1
) AS K ON K.Name=CTE00.Name AND K.YM=CTE00.YM),
-- 向下補班別
CTE02 AS (
SELECT Name,SetDate,YM,
CASE WHEN Code NOT IN ('2A','2C','3A','3B','3C') THEN NULL ELSE Code END AS CodeX
FROM CTE01),
--
CTE03 AS (
SELECT step_l.Name,step_l.YM,step_l.SetDate,step_2.CodeX as Code
FROM (
SELECT Name,YM,SetDate,CodeX,
SUM(CASE WHEN CodeX IS NULL THEN 0 ELSE 1 END) OVER (PARTITION BY Name,YM ORDER BY SetDate) as rank_id
FROM CTE02) as step_l
LEFT JOIN (
SELECT Name,YM,SetDate,CodeX,
Row_Number() OVER (PARTITION BY Name,YM ORDER BY SetDate) AS join_id
FROM CTE02 WHERE CodeX IS NOT NULL) as step_2
ON step_l.Name = step_2.Name
AND step_l.YM = step_2.YM
AND step_l.rank_id = step_2.join_id),
-- Code 內無'休'、'特'
CTE04 AS (
SELECT M.Name,M.YM,M.SetDate,M.Code,1 + SUM(M.Num) OVER (
PARTITION BY M.Name,M.YM ORDER BY M.SetDate) AS No
FROM (
SELECT CTE03.*,
CASE WHEN Code = LAG(Code,1,Code) OVER (
PARTITION BY Name,YM ORDER BY SetDate) THEN 0 ELSE 1 END AS Num
FROM CTE03) M),
CTE05 AS (
SELECT Name,YM,Code,No,Min(SetDate) AS MinDate,Max(SetDate) AS MaxDate
FROM CTE04
GROUP BY Name,YM,Code,No),
CTE06 AS (
SELECT Name,YM,No,Code,Code+':'+Right(MinDate,2)+'~'+Right(MaxDate,2) AS PartStr
FROM CTE05)
/*
SELECT Name,YM,STRING_AGG(PartStr,',') WITHIN GROUP (ORDER BY No) AS AllStr
FROM CTE06
GROUP BY Name,YM
*/
SELECT Name,YM
,stuff((
select ',' + PartStr
from CTE06 b
where a.Name = b.Name and a.YM = b.YM
order by no
for xml path('')
),1,1,'') as AllStr
FROM CTE06 a
GROUP BY Name,YM
DROP TABLE #da
有用我的修正版跟你的最後一版
去比對資料正確性跟速度嗎?
這三種表格用法~在微軟解釋記憶體部分好像我看不出差異..
create table da
create table #da
declare @da table
速度你比較快~
資料正確性你的對~
從到職日開始上班的日期也正確~
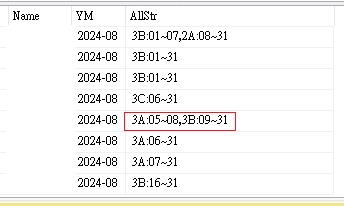
恭喜,打完收工
貼到正式空間的資料庫查詢也沒問題~謝謝你!
案例一:遞迴查詢取代 xml path 組合字串
-- 分割年月
WITH CTE00 AS (
SELECT Name,LEFT(SetDate,7) AS 'YM',SetDate,Code
FROM da),
-- 每月 1 日'休'、'特', 找到第一個班別向上補
CTE01 AS (
SELECT CTE00.Name,CTE00.YM,CTE00.SetDate,
CASE WHEN CTE00.SetDate < K.SetDate THEN K.Code ELSE CTE00.Code END AS Code
FROM CTE00
LEFT JOIN (
SELECT * FROM (
SELECT Row_Number() OVER (PARTITION BY Name,YM ORDER BY SetDate) AS RN,*
FROM CTE00
WHERE Code IN ('A','B')) AS K
WHERE RN =1
) AS K ON K.Name=CTE00.Name AND K.YM=CTE00.YM),
-- 向下補班別
CTE02 AS (
SELECT Name,SetDate,YM,
CASE WHEN Code NOT IN ('A','B') THEN NULL ELSE Code END AS CodeX
FROM CTE01),
--
CTE03 AS (
SELECT step_l.Name,step_l.YM,step_l.SetDate,step_2.CodeX as Code
FROM (
SELECT Name,YM,SetDate,CodeX,
SUM(CASE WHEN CodeX IS NULL THEN 0 ELSE 1 END) OVER (PARTITION BY Name,YM ORDER BY SetDate) as rank_id
FROM CTE02) as step_l
LEFT JOIN (
SELECT Name,YM,SetDate,CodeX,
Row_Number() OVER (PARTITION BY Name,YM ORDER BY SetDate) AS join_id
FROM CTE02 WHERE CodeX IS NOT NULL) as step_2
ON step_l.Name = step_2.Name
AND step_l.YM = step_2.YM
AND step_l.rank_id = step_2.join_id),
-- Code 內無'休'、'特'
CTE04 AS (
SELECT M.Name,M.YM,M.SetDate,M.Code,1 + SUM(M.Num) OVER (
PARTITION BY M.Name,M.YM ORDER BY M.SetDate) AS No
FROM (
SELECT CTE03.*,
CASE WHEN Code = LAG(Code,1,Code) OVER (
PARTITION BY Name,YM ORDER BY SetDate) THEN 0 ELSE 1 END AS Num
FROM CTE03) M),
CTE05 AS (
SELECT Name,YM,Code,No,Min(SetDate) AS MinDate,Max(SetDate) AS MaxDate
FROM CTE04
GROUP BY Name,YM,Code,No),
CTE06 AS (
SELECT Name,YM,No,Code,Code+':'+Right(MinDate,2)+'~'+Right(MaxDate,2) AS PartStr
FROM CTE05),
-- 遞迴查詢組合字串
CTE07 AS (
SELECT *,ROW_NUMBER() OVER (PARTITION BY Name,YM ORDER BY No) AS PX
FROM CTE06),
CTE08 AS (
SELECT Name,YM,No,PX,
CAST(PartStr as nvarchar(200)) as AllStr,1 as ID
FROM CTE07
UNION ALL
SELECT NS.Name,NS.YM,NS.No,NS.PX,
CAST(CTE08.AllStr +','+ NS.PartStr as nvarchar(200)) as AllStr,
ID + 1 AS ID
FROM CTE07 AS NS
INNER JOIN CTE08 ON NS.Name = CTE08.Name
AND NS.YM = CTE08.YM
AND NS.PX - 1 = CTE08.PX
)
--
SELECT A.Name,A.YM,A.AllStr
FROM CTE08 AS A
INNER JOIN (
SELECT Name,YM,MAX(ID) AS MAXID
FROM CTE08
GROUP BY Name,YM) AS B ON B.Name = A.Name
AND B.YM = A.YM
AND B.MAXID = A.ID
ORDER BY Name,YM
案例二:遞迴查詢取代 xml path 組合字串
-- 分割年月
WITH CTE00 AS (
SELECT Name,LEFT(SetDate,7) AS 'YM',SetDate,Code
FROM da),
-- 每月 1 日'休'、'特', 找到第一個班別向上補
CTE01 AS (
SELECT CTE00.Name,CTE00.YM,CTE00.SetDate,
CASE WHEN CTE00.SetDate < K.SetDate THEN K.Code ELSE CTE00.Code END AS Code
FROM CTE00
LEFT JOIN (
SELECT * FROM (
SELECT Row_Number() OVER (PARTITION BY Name,YM ORDER BY SetDate) AS RN,*
FROM CTE00
WHERE Code IN ('A','B')) AS K
WHERE RN =1
) AS K ON K.Name=CTE00.Name AND K.YM=CTE00.YM),
-- 向下補班別
CTE02 AS (
SELECT Name,SetDate,YM,
CASE WHEN Code NOT IN ('A','B') THEN NULL ELSE Code END AS CodeX
FROM CTE01),
--
CTE03 AS (
SELECT step_l.Name,step_l.YM,step_l.SetDate,step_2.CodeX as Code
FROM (
SELECT Name,YM,SetDate,CodeX,
SUM(CASE WHEN CodeX IS NULL THEN 0 ELSE 1 END) OVER (PARTITION BY Name,YM ORDER BY SetDate) as rank_id
FROM CTE02) as step_l
LEFT JOIN (
SELECT Name,YM,SetDate,CodeX,
Row_Number() OVER (PARTITION BY Name,YM ORDER BY SetDate) AS join_id
FROM CTE02 WHERE CodeX IS NOT NULL) as step_2
ON step_l.Name = step_2.Name
AND step_l.YM = step_2.YM
AND step_l.rank_id = step_2.join_id),
-- Code 內無'休'、'特'
CTE04 AS (
SELECT M.Name,M.YM,M.SetDate,M.Code,1 + SUM(M.Num) OVER (
PARTITION BY M.Name,M.YM ORDER BY M.SetDate) AS No
FROM (
SELECT CTE03.*,
CASE WHEN Code = LAG(Code,1,Code) OVER (
PARTITION BY Name,YM ORDER BY SetDate) THEN 0 ELSE 1 END AS Num
FROM CTE03) M),
CTE05 AS (
SELECT Name,YM,Code,No,Min(SetDate) AS MinDate,Max(SetDate) AS MaxDate
FROM CTE04
GROUP BY Name,YM,Code,No),
CTE06 AS (
SELECT Name,YM,No,Code,Code+':'+Right(MinDate,2)+'~'+Right(MaxDate,2) AS PartStr
FROM CTE05),
-- 遞迴查詢組合字串
CTE07 AS (
SELECT *,ROW_NUMBER() OVER (PARTITION BY Name,YM ORDER BY No) AS PX
FROM CTE06),
CTE08 AS (
SELECT Name,YM,No,PX,
CAST(PartStr as nvarchar(200)) as AllStr,1 as ID
FROM CTE07
UNION ALL
SELECT NS.Name,NS.YM,NS.No,NS.PX,
CAST(CTE08.AllStr +','+ NS.PartStr as nvarchar(200)) as AllStr,
ID + 1 AS ID
FROM CTE07 AS NS
INNER JOIN CTE08 ON NS.Name = CTE08.Name
AND NS.YM = CTE08.YM
AND NS.PX - 1 = CTE08.PX
)
--
SELECT Name,YM,AllStr
FROM (
SELECT *,ROW_NUMBER() OVER (PARTITION BY Name,YM ORDER BY ID Desc) AS Pos
FROM CTE08
) T
WHERE Pos = 1
ORDER BY Name,YM
可否幫忙用大量數據測一下最後一版(使用 xml path 組合字串)
與案例一、案例二遞迴查詢組合字串時間相差多少,謝謝。
兩個都查詢過久取消~
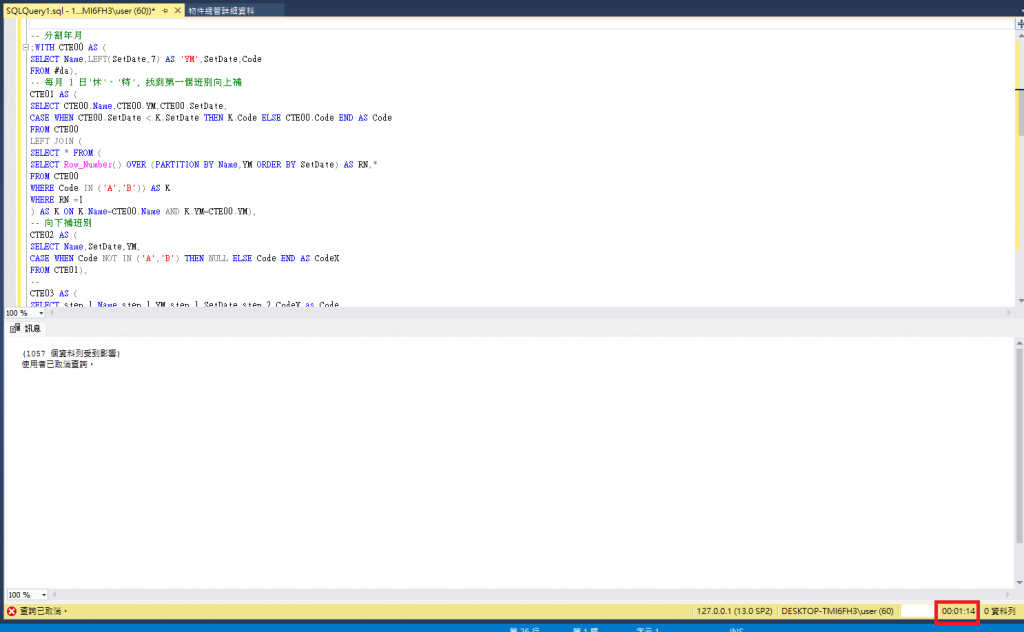
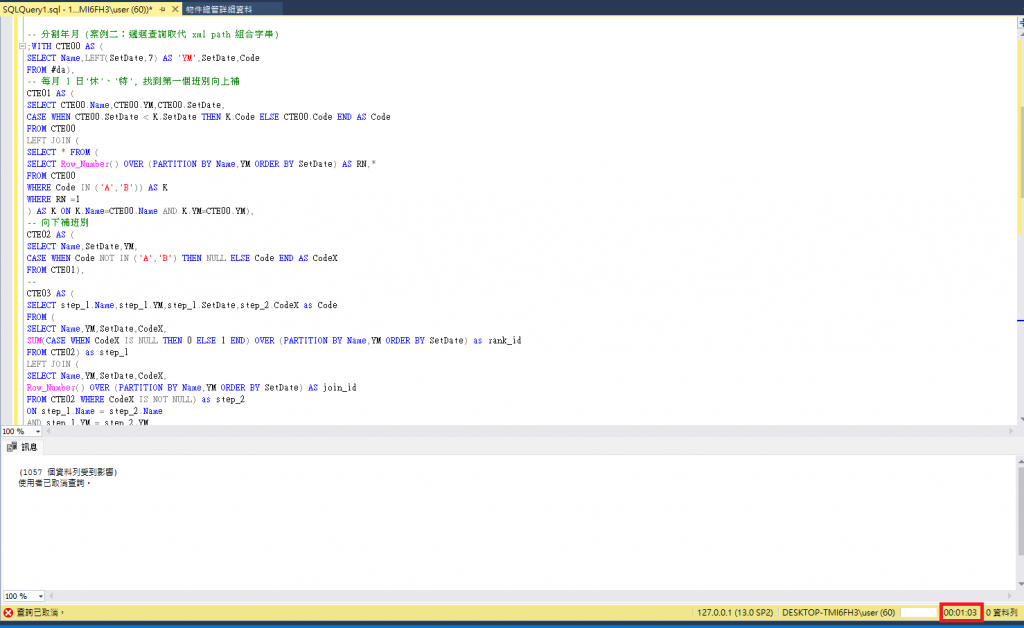
單純2筆的資料~馬上出來~
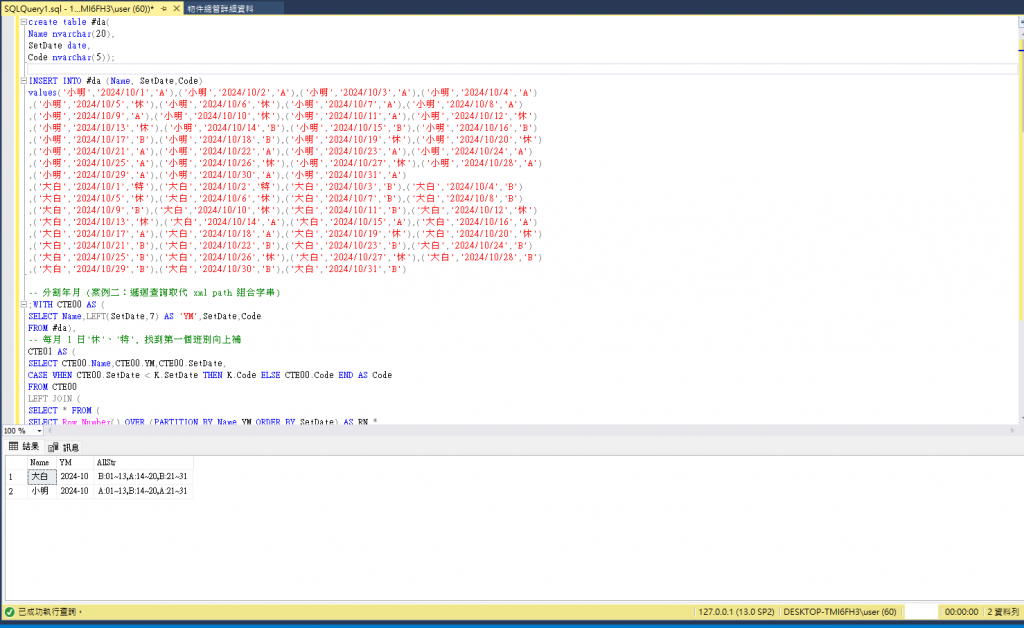
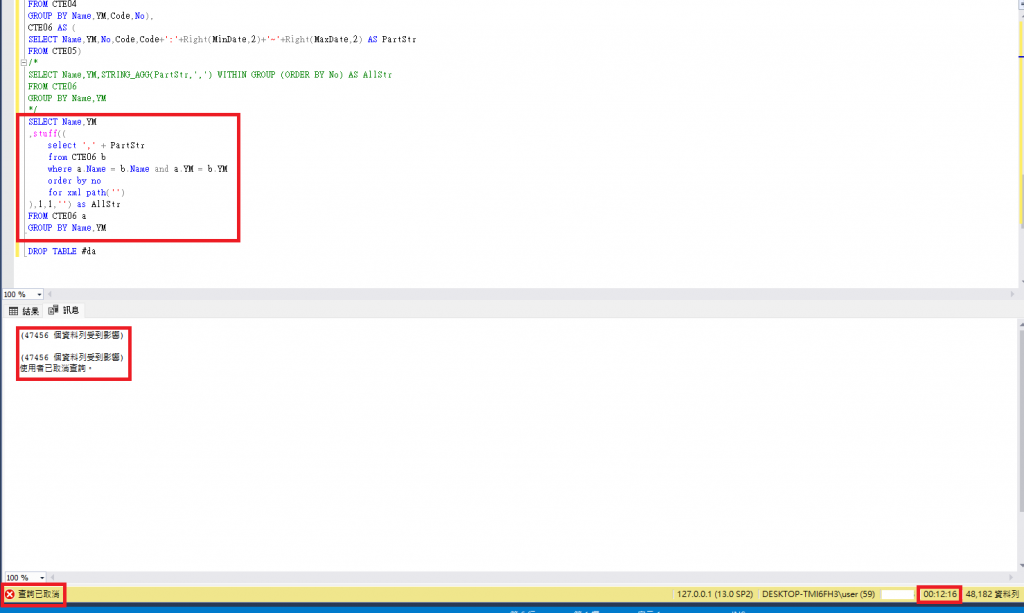
為取得時間相差多少,我在 Win 11 上的 SQL 2019 建立 1380 筆資料
1.STRING_AGG : 0.084 秒
2.xml path : 2.435 秒
3.遞迴查詢組合字串用 ROW_NUMBER 取得指定筆資料 : 14.874 秒
4.遞迴查詢組合字串 INNER JOIN + MAX 取得指定筆資料 : 30.976 秒
結論 :
1.指令優先選擇 : STRING_AGG > xml path > 遞迴查詢組合字串
2.取得指定筆資料 : ROW_NUMBER > INNER JOIN + MAX
果然微軟推出的新函數 STRING_AGG ,優化效能很多了~
若我把整個歷史資料4萬多筆~的確都跑不完😂😂😂
[SQL Server]STRING_AGG 在2017版以前的替代方案(SQLCLR)
或許你可以用這個方法在 2016 建立自己的 STRING_AGG
恩~不過我沒有主機權限~這個SQLCLR就放棄吧
我的工作是將已開發的程式碼,轉交另一個工程師(機房)驗證上線

 iThome鐵人賽
iThome鐵人賽