大家好:
因個人長期在我的粉絲團,張貼相關身障相關新聞,我是想說,是否可以自製搜尋引手擎,只要輸入相關關鍵字後,就可以把當天搜尋關鍵字新聞搜尋出來。
已邀請的邦友 {{ invite_list.length }}/5
def search_news(keyword):
# 假設使用 Google 新聞作為搜尋來源
url = f"https://news.google.com/search?q={keyword}&hl=zh-TW&gl=TW&ceid=TW%3Azh-Hant"
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
articles = soup.find_all('article')
news_links = []
for article in articles:
title = article.find('h3').text if article.find('h3') else '無標題'
link = article.find('a')['href'] if article.find('a') else '#'
news_links.append(f"標題: {title}\n連結: {link}\n")
return "\n".join(news_links)
else:
return "無法獲取新聞資料"
def post_to_facebook(message, access_token):
graph = facebook.GraphAPI(access_token)
graph.put_object(parent_object='me', connection_name='feed', message=message)
# 使用範例
search_keyword = input("請輸入關鍵字: ")
news_message = search_news(search_keyword)
if news_message:
# 替換為你的 Facebook 存取令牌
access_token = 'YOUR_ACCESS_TOKEN'
post_to_facebook(news_message, access_token)
說明
搜尋新聞:
使用 requests 獲取 Google 新聞的搜尋結果,並用 BeautifulSoup 解析 HTML 提取標題和連結。
發佈到 Facebook:
使用 facebook-sdk 將提取的新聞內容發佈到你的粉絲專頁。請確保你有適當的存取令牌。
3. 部署和自動化
將上述代碼保存為 .py 文件,並安裝必要的庫(例如使用 pip install requests beautifulsoup4 facebook-sdk)。
可以考慮使用排程任務(如 cron 作業)來定期執行這個腳本,每天自動搜尋並發佈最新新聞。
4. 注意事項
確保遵守新聞網站的爬蟲政策,避免過於頻繁地抓取數據。
Facebook API 有使用限制,需遵循其開發者政策。
這樣,你就可以建立一個自動化系統,根據關鍵字搜尋相關新聞並將其發佈到你的 Facebook 粉絲團。
語法
https://www.facebook.com/groups/freedisabled/search/?q=關鍵字
瀏覽器新增搜尋引擎
設定 > 搜尋引擎 > 網站搜尋 > 新增 >
輸入如下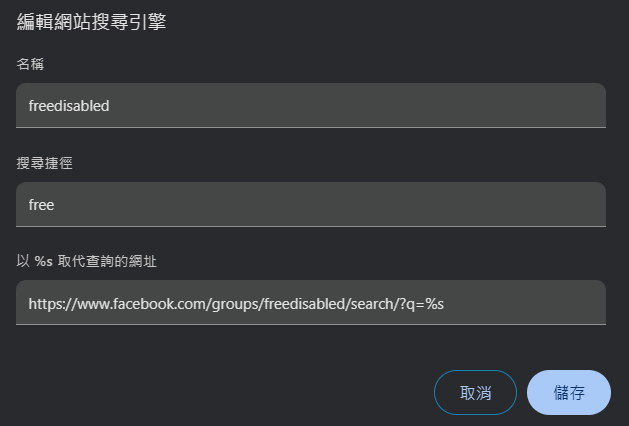
會出現
然後網址列按下 FREE 出現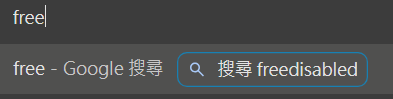
大完收工
他那個是私密社團~要查以前的文章記錄...0.0a
這招我來試試能否找以前的資料~
有學到,那我是要找各家新聞網站的關鍵字,如,身障之類的新聞囉!
但這個方式要一一的鍵相關關鍵字
語法 https://news.google.com/search?q=身心障礙&%s
就這樣啊 ...

 iThome鐵人賽
iThome鐵人賽