講完了pairRDD與聚合函數後,再來講CoreAPI最後一塊拼圖:Task & Stages。今天的文章比較偏概念性的內容,說明Spark的工作概念與RDD間的相依性與Checkpoint,但這也很重要唷~整天看指令畫面,看看UI也不錯~
先來看一段簡單的聚合操作:
scala> val list = List.fill(500)(scala.util.Random.nextInt(10)) ①
list: List[Int] = List(0, 9, 6, 3, 3, 0, 9, 2, 8, 5, 3, 6, 0, 4, 4, 0, 5, 8, 8, 1, 9, 1, 3, 3, 3, 9, 3, 2, 6, 2, 7, 1, 7, 8, 8, 4, 7, 4, 4, 2,..
scala> val listrdd = sc.parallelize(list, 5) ②
listrdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26
scala> val pairs = listrdd.map(x => (x, x*x)) ③
pairs: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[1] at map at <console>:28
scala> val reduced = pairs.reduceByKey((v1, v2)=>v1+v2) ④
reduced: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[2] at reduceByKey at <console>:30
scala> val finalrdd = reduced.mapPartitions( ⑤
iter => iter.map({case(k,v)=>"K="+k+",V="+v}))
finalrdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[3] at mapPartitions at <console>:32
scala> finalrdd.collect()
res0: Array[String] = Array(K=0,V=0, K=5,V=1250, K=1,V=47, K=6,V=1656, K=7,V=2401, K=2,V=212, K=3,V=558, K=8,V=3264, K=4,V=816, K=9,V=3159)
①用fill搭配Curry化的參數寫法,產生500個變數的List
②建立RDD,並指定5個partition(不用預設值)
③轉pairRDD
④聚合操作~reduceByKey又出場了XD
⑤這邊有個有趣的寫法,一樣是map操作,但這次是用mapPartitions。還記得map操作會抹除partitioner的資訊嗎?用mapPartitions則會保留。在mapPartitions裡面我們再對依般元素進行map操作,這時候的scope已經是每個partition內了,所以用標準map即可。
在Spark內,RDD間有所謂的相依關係(Dependence),我們可以用DAG(有向無循環圖,directed acyclic graph)進行描述,其中節點為一個個RDD,而邊則為有關係的RDD,假設RDD A透過transformation操作產生RDD B,則B與A之間有dependence,A為B的parent RDD;而B為A的child RDD。基本的Dependence又分兩種:
沒有shuffling資料有shuffling發生RDD lineage(RDD血統圖)來看看剛剛一系列操作的lineage長的如何吧:
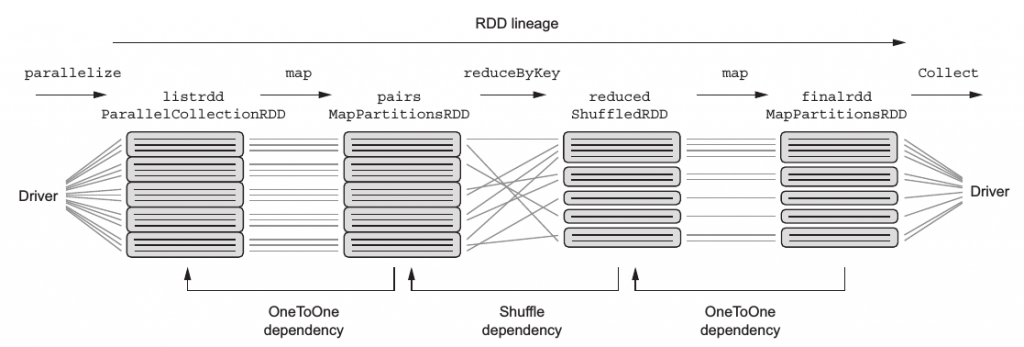
每個方塊代表一個RDD,方塊間的線條代表資料流。其中平行執行的代表操作沒有發生shuffling,反之則有。從上圖可以看出哪個操作有發生shuffling?沒錯,就是reduceByKey,還記得昨天的內容?map後的reduceByKey會產生shuffling~
知道這些有啥用勒?因為這些資訊可以用來了解Spark task與stage的概念:簡單說,每個工作代表一個轉換操作,而工作會被包奘在某個stages內,意味著一個stages可以包含多個tasks,而Stage的切分就是shuffling發生時,看看剛剛的例子會產生幾個Stages吧:
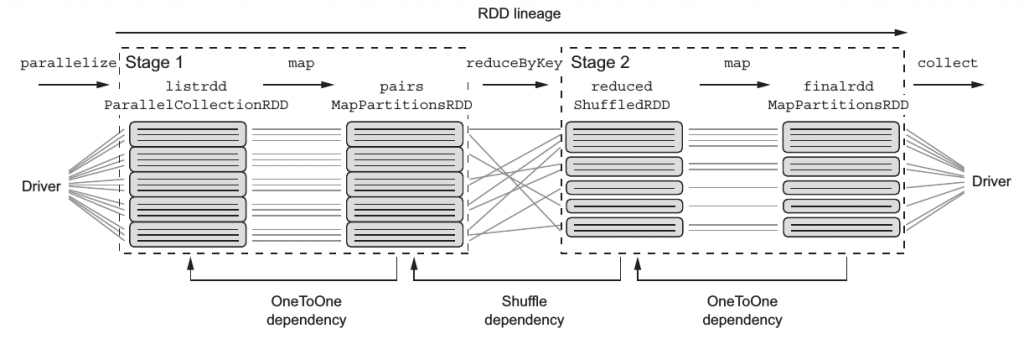
很明顯了吧,shuffling後的reduced RDD及後續的操作被歸類在Stage2了,如果又產生一個shuffling的操作,則又會切出下一個Stage。
Spark有很方便的工具可以觀察這些Stages,那就是SparkUI啦!該怎麼打開勒?還記得Day1的不囉唆賀圖嗎XD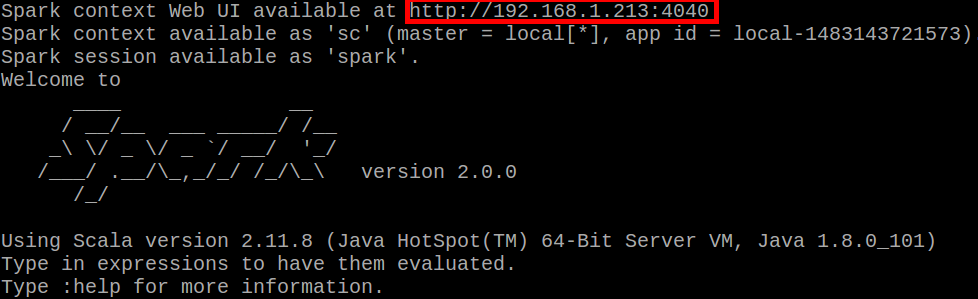
沒錯,那個URL就是位置,Spark UI是個web-based的服務,快去打開吧!
[Snippet.35]開啟Spark UI
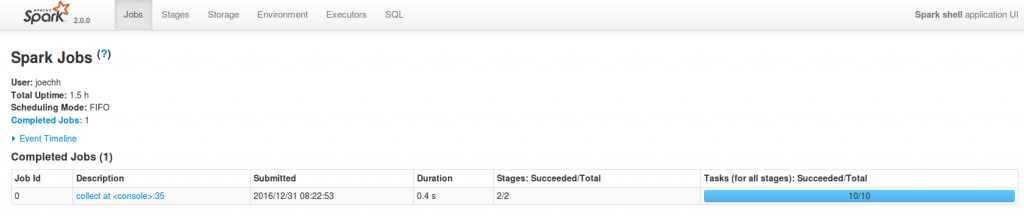
一進去可以發現最上面是幾個頁籤,有機會再來多說一點。剛進去的時候會在Jobs頁籤,下面的長條圖就是我們之前執行的一個工作,有一些描述:
Description可以繼續點進去看:
恩,Stages的說明被拆成兩個說明,又更細了一點。往下點就會切到Stages頁籤了先跳過XD,我們的重點勒?有看到左上角有個DAG Visualization嗎?點下去!
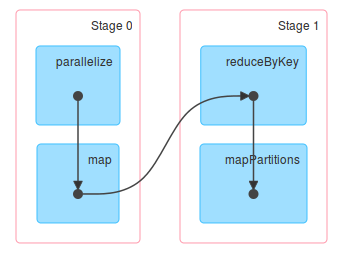
噹噹~DAG圖,我覺得這張圖也蠻好理解的,記住切換Stage時就是有進行shuffling。短暫的SparkUI先到此一遊。
有了lineage概念後,試想一個問題:
分散式環境下,如果某個節點壞掉了,裡面有某個RDD的資料,有機會重建嗎?當然有啦~如果ParentRDD資料還在不就可以套用一樣的操作重建了,如果ParentRDD也壞掉了勒?那就找ParentOfParent RDD...無限loop!!當然如果到頂端還是沒有那就fail了。
好,感覺蠻厲害的,內建分區容錯,嘖嘖,但有沒有想過假設操作很複雜,中間產生了一堆RDD轉換,要重建有可能要花很久?因此,這就是checkpoint可以導入的時機啦,他會把RDD中的資料持久化到儲存系統(通常是HDFS等分散式容錯系統上啦,儲存在本機,剛好本機連同RDD一起壞掉不就搞笑了~),因此,他可以讓RDD的重建路徑抄近路。此外checkpoint對Spark Streaming也非常重要,到時候再說。
要建立RDD的checkpoint,要先透過sparKContext(在shell中就是sc)指定checkpoint儲存路徑,實驗關係就先設在本機吧。那要怎麼對RDD建立checkpoint勒?就用checkpoint函式阿~
scala> sc.setCheckpointDir("/home/joechh/testCheckPointDir")
scala> finalrdd.checkpoint
進目錄看一下:
joechh@joechh:~$ ll /home/joechh/testCheckPointDir/
總計 12
drwxrwxr-x 3 joechh joechh 4096 12月 31 10:18 ./
drwxr-xr-x 97 joechh joechh 4096 12月 31 10:18 ../
drwxrwxr-x 2 joechh joechh 4096 12月 31 10:17 4988463a-54f0-4c67-bcce-05a2a780e7ef/
joechh@joechh:~$
恩,寫入成功!



 iThome鐵人賽
iThome鐵人賽