終於進入下一個主題:Spark Family的Spark Streaming篇~
講解過程中要從一些外部系統接資料,特別是HDFS跟Kafka,所以免不了要提一下怎麼安裝。我所使用的版本如下:
先開始安裝HDFS吧:
[Snippet.38]建立StandAlone HDFS (Pseudo-Distribution mode)
我們只有用到Hadoop的HDFS的部份,我會以Pseudo-Distribution mode在本機起一個單一節點的叢集環境,而且不設定YARN那部份讓環境盡可能單純。
先安裝一下遠端登入與同步的套件吧:
$ sudo apt-get install ssh
$ sudo apt-get install rsync
接著設定JAVA_HOME環境變數
joechh@joechh:~$ vim ~/.bashrc
---in ~/.bashrc---
export JAVA_HOME="/usr/lib/jvm/java-8-oracle"
export PATH=JAVA_HOME:$PATH
安裝路徑要視個人環境修改唷~像我的話是在/usr/lib/jvm/java-8-oracle
重新load環境變數並測試:
joechh@joechh:~$ source ~/.bashrc
joechh@joechh:~$ java -version
java version "1.8.0_101"
Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
joechh@joechh:~$
OK,有正確抓到java,可以下指令
接著安裝HDFS,設定套件包底下的 etc/hadoop/hadoop-env.sh:注意這邊的etc不是系統的/etc,別搞混囉~
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
接著設定套件包底下的etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
可以看到我們將hdfs的URI設定為本機
接著設定套件包底下的etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name> ①
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name> ②
<value>/opt/hadoop-2.7.3/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name> ③
<value>/opt/hadoop-2.7.3/data/datanode</value>
</property>
</configuration>
①因為我們只有一台主機,所以HDFS的replication為1
②設定namenode的block資訊(類似metadate)要存在哪
③設定資料(block)存放位置
若沒有設定②的話,namenode的資料預設會在/tmp,很容易就被清掉...整個悲劇的預設值,想玩久一點就要改阿,不然format指令會練的很熟練XD,啥是format指令?繼續看下去吧
設定ssh免密碼登入:
joechh@joechh:~$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
joechh@joechh:~$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
joechh@joechh:~$ chmod 0600 ~/.ssh/authorized_keys
檢查是否有成功:
joechh@joechh:~$ ssh localhost
Welcome to Ubuntu 16.04.1 LTS (GNU/Linux 4.4.0-57-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
128 packages can be updated.
4 updates are security updates.
Last login: Tue Jan 3 10:59:07 2017 from 127.0.0.1
joechh@joechh:~$
然後要到處可以執行hdfs指令的話就要把路徑登錄進PATH環境變數中,進家目錄設定一下.bashrc
#HADOOP in ~/.bashrc file
export HADOOP_HOME="/opt/hadoop-2.7.3"
export PATH=$HADOOP_HOME/bin:$PATH
做完後別忘記用resource ~/.bashrc reload一下環境變數
OK,第一次啟用HDFS需要做類似格式化(format)的動作,開始吧:bin/hdfs namenode -format
joechh@joechh:/opt/hadoop-2.7.3$ bin/hdfs namenode -format
....
....
ages with txid >= 0
17/01/03 11:02:04 INFO util.ExitUtil: Exiting with status 0
17/01/03 11:02:04 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at joechh/127.0.1.1
************************************************************/
看到離開狀態為0(Exiting with status 0)代表正常結束了,啟動服務吧!: sbin/start-dfs.sh
joechh@joechh:/opt/hadoop-2.7.3$ sbin/start-dfs.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /opt/hadoop-2.7.3/logs/hadoop-joechh-namenode-joechh.out
localhost: starting datanode, logging to /opt/hadoop-2.7.3/logs/hadoop-joechh-datanode-joechh.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is SHA256:bGzAPASM8JqJaNDWWOi2DzZorWjQw3P+W367LJKGYjs.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop-2.7.3/logs/hadoop-joechh-secondarynamenode-joechh.out
先透過jps指令(java process)檢查看看: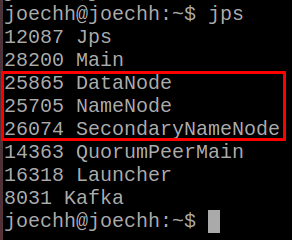
有看到DataNode、NameNode跟SecondaryNameNode代表HDFS的程序有啟動了。
再看看http://localhost:50070 的Web UI有沒有產生!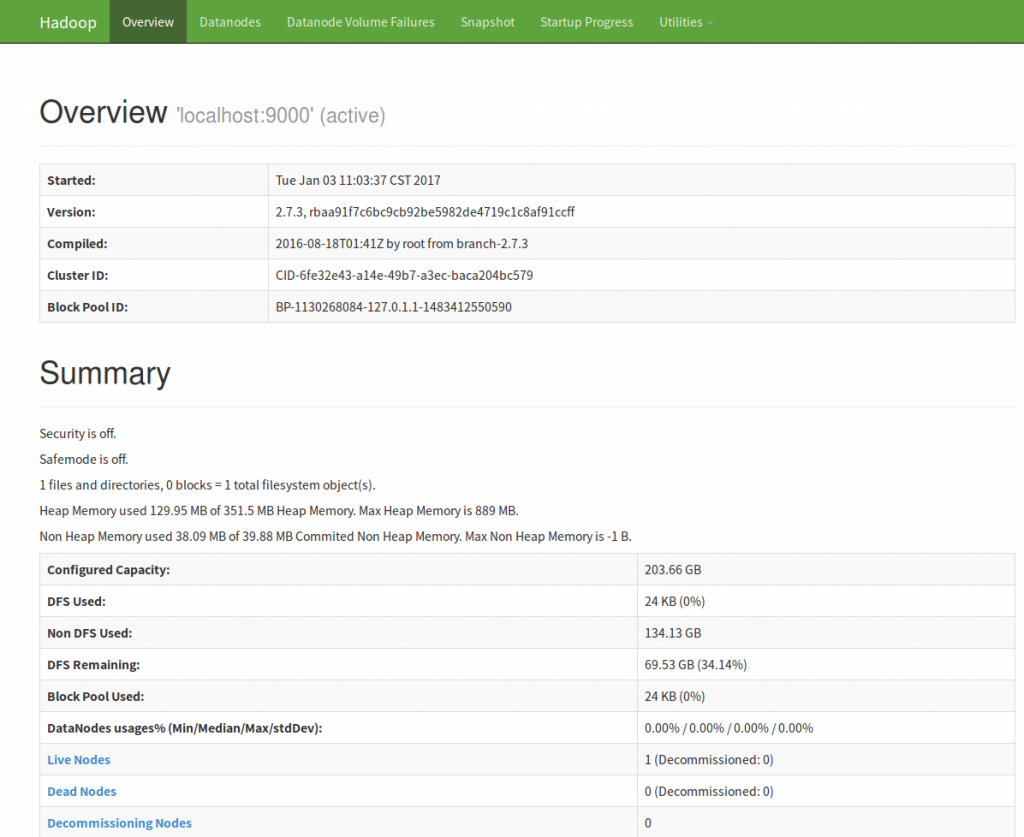
OK,檢查完畢,玩一下,其實跟linux的指令蠻像的,完整shell指令列表可以參考:
https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/FileSystemShell.html
疑,怎麼下個ls就掛掉了XD~
joechh@joechh:~$ hdfs dfs -ls
ls: `.': No such file or directory
喔喔,原來是joechh這個人在HDFS上面還沒有家目錄,建個家目錄吧:
joechh@joechh:~$ hdfs dfs -mkdir /user
joechh@joechh:~$ hdfs dfs -mkdir /user/joechh
joechh@joechh:~$ hdfs dfs -ls
joechh@joechh:~$
家目錄依個人環境為主,像我的帳號是joechh(可以用$whoami指令檢查),所以我開成/user/joechh。再次執行ls指令!這次沒說找不到了,只是目錄下沒檔案,所以ls沒傳回任何東西,put個檔案上去看看
joechh@joechh:/opt/hadoop-2.7.3$ hdfs dfs -put README.txt testfile ①
joechh@joechh:/opt/hadoop-2.7.3$ hdfs dfs -ls ②
Found 1 items
-rw-r--r-- 1 joechh supergroup 1366 2017-01-03 11:21 testfile
joechh@joechh:/opt/hadoop-2.7.3$
①透過hdfs dfs -put將本地的README.txt傳到HDFS上,並且更變名稱為testfile
②再ls一次,有東西囉
跑跑看Hadoop內建的算pi MapReduce Sample範例:
joechh@joechh:/opt/hadoop-2.7.3$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 100 100 ①
...略
...略
File Input Format Counters
Bytes Read=11800
File Output Format Counters
Bytes Written=97
Job Finished in 4.501 seconds
Estimated value of Pi is 3.14080000000000000000
OK,沒問題,但①我有將hadoop下面的bin加入環境變數內才能在隨意的目錄下執行XD~
如何關掉HDFS服務勒?
$ sbin/stop-dfs.sh
[Snippet.39]建立StandAlone KafKa(standAlone mode)
kafka bin套件預設值已經可以順利本機模式了,只是我們在config.properties加入一行:
delete.topic.enable=true
讓kafka允許我們刪除topic。
基本上設定都不用動,未來要改設定,或是轉成叢集模式需要修改:
啟動服務吧,在kafka的頂端目錄:
//先啟動zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
//再啟動kafka
bin/kafka-server-start.sh config/server.properties
注意到不像HDFS會返回prompt,這樣啟動會吃掉兩個terminator,就算加&(背景執行)還是會時不時的噴訊息,所以production上還要用透過upstarter或systemd來啟動才好。
檢查kafka topic列表的指令:
joechh@joechh:/opt/kafka_2.11-0.8.2.1$ bin/kafka-topics.sh --list --zookeeper 192.168.56.1:2181
空的,建立一個testTopic吧:
joechh@joechh:/opt/kafka_2.11-0.8.2.1$ bin/kafka-topics.sh --create --zookeeper 192.168.56.1 --replication-factor 1 --partitions 1 --topic testTopic
Created topic "testTopic".
若要移除測試的topic勒?
joechh@joechh:/opt/kafka_2.11-0.8.2.1$ bin/kafka-topics.sh --delete --zookeeper 192.168.56.1 --topic testTopicTopic testTopic is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
你看,他有說如果沒有將 delete.topic.enable設定為true的話刪除指令則無效。
測試:開一個producer、一個consumer來對傳測試看看吧:
本段測試要開兩個terminator
先在第一個terminator建立console-producer:
joechh@joechh:/opt/kafka_2.11-0.8.2.1$ bin/kafka-console-producer.sh --broker-list 192.168.56.1:9092 --topic testTopic
[2017-01-03 12:03:18,868] WARN Property topic is not valid (kafka.utils.VerifiableProperties)
然後在第二個terminator建立console-consumer:
joechh@joechh:/opt/kafka_2.11-0.8.2.1$ bin/kafka-console-consumer.sh --zookeeper 192.168.56.1:2181 --topic testTopic
都沒問題的話,可以在producer的 prompt開始隨意輸入一些字串,測試consumer有沒有吃到:
畫面大概是這樣:
畫面有點小,左邊的是producer,隨意鍵入字串。右邊的consumer應該會收到並印出在console上~
自此簡易的開發環境設定完成。



 iThome鐵人賽
iThome鐵人賽