我們昨天已經看過如何在Scala中獨立使用Kafka。以我之前的經驗,Kafka Producer的部份有比較多的可能會與其他系統而不是Spark整合,這時候就能用Java/Scala/Python/JS等撰寫。當然Producer端也可能來自於Spark,常見的情景是ETL的過程中從一個Topic取出Data,透過Spark處理完後後,丟入另外一個Topic做pipeline等。今天來看看如何透過Spark使用Kafka吧!
Spark提供兩種方式整合Kafka:
Receiver
DirectConnector
Reciever若處理過程中crash,有可能產生一筆資料被重複處理。而Spark1.3版導入了DirectConnector,相較於Reciever這種方式主要有3個優點:
從空間或是處理角度成本來看都不是有效率的作法。在directStream若資料遺失了,再次從Kafka源頭拿取就是了。至少一次的特性),但某些情境(例如Spark接收資料端與追蹤Zookeeper中的offset沒有完全同步)有可能意外地讓資料被處理了一次以上。因此directStream不再透過Zookeeper管理offset,轉而透過系統內checkpoint機制管理offset(所以就要開啟checkpoint功能囉~)。而這樣帶來的好處是巨大的,最重要的就是即便處理過程中有失效,offset與Spark的一致還是可以保證資料只被處理一次的特性,這再某些對統計值敏感的情境中相當有用。注意唯一一次的特性還必須搭配相對應的Output Operation(因為若Output不是原子性的也沒用阿XD)~簡言之,還有其他effort要處理才有辦法達成。本篇將以DirectConnector的方式連接Kafka。
先來看看之前很複雜的KafkaConsumer,如果用Spark接會如何?
[Snippet.59] Create SparkKafka DirectStream
import org.apache.spark.streaming.kafka.KafkaUtils
val kafkaStream = KafkaUtils.
createDirectStream[String, String, StringDecoder, StringDecoder](ssc,
kafkaReceiverParams, Set("orders"))
kafkaStream就類似之前的consumer,但有沒有大幅簡化的感覺阿。1-to-1 mapping果然很威阿~但就要設計好partition的部份。那資料透過kafkaStream接進來後透過各種方式處理後,總要往下個pipeline走吧,那要透過啥勒?
//
def foreachRDD(foreachFunc: RDD[T] => Unit): Unit
def foreachRDD(foreachFunc: (RDD[T], Time) => Unit): Unit
像Java8/Scala的Lambda串到最後(或是中間)可以透過foreach作回傳UNLL的任何動作。Scala當然也有很威的foreachRDD版本可以使用,等看到code時會更有感覺。
好,說完了Consumer,接著提Producer吧。延續先前被我們反覆玩耍的finalStream為例XD,若想將處理過後的finalStream寫回Kafka的metric topic該怎麼做?
//cannot serializable, need to create a Producer in executors
import kafka.producer.Producer
import kafka.producer.KeyedMessage
import kafka.producer.ProducerConfig
finalStream.foreachRDD((rdd) => { ①
val prop = new java.util.Properties ②
prop.put("metadata.broker.list", "192.168.10.2:9092")
prop.put("serializer.class", "kafka.serializer.StringEncoder")
prop.put("producer.type", "async")
//▲
rdd.foreach(x => { ③
val p = new Producer[String, String](new ProducerConfig(prop))④
p.send(new KeyedMessage("metric", x)) ⑤
p.close() ⑥
//▲
})
})
①開foreachRDD並導入foreachFunc函式邏輯
②準備各種Prop,就像之前開Producer時一樣
③每個RDD再開Foreach並導入邏輯函式
④開Producer
⑤建立KeyedMessage並送出
⑥關閉Producer
注意,上圖例子中被▲框起來的程式段會在各個executor中執行,而其他的則在Driver端,但這樣的寫法很不好,在rdd.foreach導入的函式中裏面建立producer,這代表每個Message都會建一個Producer!所以一定要改良阿,該怎麼做?
finalStream.foreachRDD((rdd) => {
val prop = new java.util.Properties
prop.put("metadata.broker.list", "192.168.10.2:9092")
//▲
rdd.foreachPartition((iter) => { ①
val p = new Producer[String, String](new ProducerConfig(prop))
iter.foreach(x => p.send(new KeyedMessage("metric",x)))
p.close()
//▲
})
})
①從RDD升級成foreachPartition這樣每個RDD partition才會起一個producer。有比較好了,但還不夠。能不能每個JVM只起一個Producer?
[Snippet.60] Singleton Kafka Producer
其實singleton來解決這個問題,而Scala中的singleton可以透過Companion Object(還記得Object嗎?)而Producer本身是Thread-safe的,所以用singleton沒有問題,那該怎麼寫呢?
package SparkIronMan
import kafka.producer.{KeyedMessage, Producer, ProducerConfig}
/**
* Created by joechh on 2017/1/9.
*/
case class KafkaProducerWrapper(brokerList: String) { ①
val producerProps = {
val prop = new java.util.Properties ②
prop.put("metadata.broker.list", brokerList)
prop.put("serializer.class", "kafka.serializer.StringEncoder")
prop.put("producer.type", "async")
prop
}
val p = new Producer[String, String](new ProducerConfig(producerProps))③
def send(topic: String, key: String, value: String) { ④
p.send(new KeyedMessage(topic, key, value))}
def send(topic: String, value: String) { ⑤
p.send(new KeyedMessage[String, String](topic, value))}
def close() {p.close()} ⑥
}
object KafkaProducerWrapper { ⑦
var brokerList = ""
lazy val getInstance = new KafkaProducerWrapper(brokerList)
}
object SingletonKafkaTest extends App { ⑧
KafkaProducerWrapper.brokerList = "192.168.56.1:9092"
val producer = KafkaProducerWrapper.getInstance
producer.send("testTopic", "this is a test")
producer.close()
}
① 宣告一個case Class的Wrapper類別,並在⑦建立對應的Companion Object
② 建立Prop以及塞入所需的參數設定
③ 建立Producer
④ wrap代理的send方法(需要key)
⑤ wrap代理的send方法(不需要key)
⑥ wrap代理的close方法
⑦ 在body初始化一個KafkaProducerWrapper,因為Object為Singleton,被包裹的Producer也就只有一個啦
⑧ 測試測試進入點,可以開一個console-consumer看看有沒有寫值到testTopic
Streaming系列終於要結束了,最後附上一個改造完成的完整程式吧!
[Snippet.61] Spark-Kafka in/out Example
package SparkIronMan
/**b
* Created by joechh on 2016/12/6.
*/
import java.sql.Timestamp
import java.text.SimpleDateFormat
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming._
import kafka.serializer.StringDecoder
object Day27_Kafka extends App {
val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaStreaming") ①
val ssc = new StreamingContext(conf, Seconds(10))
val kafkaReceiverParams = Map[String, String]("metadata.broker.list" -> "192.168.56.1:9092") ②
val kafkaStream = KafkaUtils.
createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaReceiverParams, Set("orders")) ③
val orders = kafkaStream.flatMap(line => {
val dateFormat = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
val words = line._2.split(",")
try {
assert(words(6) == "B" || words(6) == "S")
List(Order(new Timestamp(dateFormat.parse(words(0)).getTime),
words(1).toLong,
words(2).toLong,
words(3),
words(4).toInt,
words(5).toDouble,
words(6) == "B"
))
}
catch {
case e: Throwable => println("wrong line format(" + e + "):" + line)
List()
}
})
val amountPerClient = orders.map(record => (record.clientId, record.amount * record.price))
val updatePerClient = (clientId: Long, amount: Option[Double], state: State[Double]) => {
var total = amount.getOrElse(0.toDouble)
if (state.exists())
total += state.get()
state.update(total)
Some((clientId, total))
}
val amountState = amountPerClient.mapWithState(StateSpec.function(updatePerClient)).stateSnapshots()
val numPerType = orders.map(o => (o.buy, 1L)).
reduceByKey(_ + _)
val buySellList = numPerType.map(t =>
if (t._1) ("BUYS", List(t._2.toString))
else ("SELLS", List(t._2.toString))
)
val top5clients = amountState.
transform(_.sortBy(_._2, false).
zipWithIndex().
filter(_._2 < 5)).
map(_._1)
val top5clList = top5clients.repartition(1).
map(_._1.toString).
glom.
map(arr => ("TOP5CLIENTS", arr.toList))
val stocksPerWindow = orders.map(x => (x.symbol, x.amount)).
window(Minutes(60)).
reduceByKey(_ + _)
val topStocks = orders.map(x => (x.symbol, x.amount)).
reduceByKeyAndWindow((_ + _), (_ - _), Minutes(60)).
transform(_.sortBy(_._2, false).
zipWithIndex.
filter(_._2 < 5)).
map(_._1).
repartition(1).
map(_._1.toString).
glom.
map(arr => ("TOP5STOCKS", arr.toList))
val finalStream = buySellList.union(top5clList).union(topStocks)
ssc.sparkContext.setCheckpointDir("/home/joechh/chpoint") ④
finalStream.foreachRDD((rdd) => { ⑤
rdd.foreachPartition((iter) => { ⑥
KafkaProducerWrapper.brokerList = "192.168.56.1:9092" ⑦
val producer = KafkaProducerWrapper.getInstance ⑧
iter.foreach(
{
case (k, v) => producer.send("metrics", k+", "+ v.toString) ⑨
}
)
}
)
}
)
ssc.start
ssc.awaitTermination
}
case class Order(time: java.sql.Timestamp, orderId: Long, clientId: Long,
symbol: String, amount: Int, price: Double, buy: Boolean)
① 建立SparkConf並產生ssc
② 建立Kafak所需的Paras
③ 透過KafaUtils搭配Params以createDirect方式產生kafkaStream
中間段就是之前邏輯的大雜燴了,可以趁機複習一下
④ 別忘了對Streaming很重要的checkpoint
⑤ 要開始處理finalStreaming了,開foreachRDD吧
⑥ 然後每個Partition平行處理(會對應到Kafka的Partition)
⑦ 設定ObjectWrapper的brokerList
⑧ 取得Singleton的Producer
⑨ 用pattern match匹配寫值的作法
執行畫面: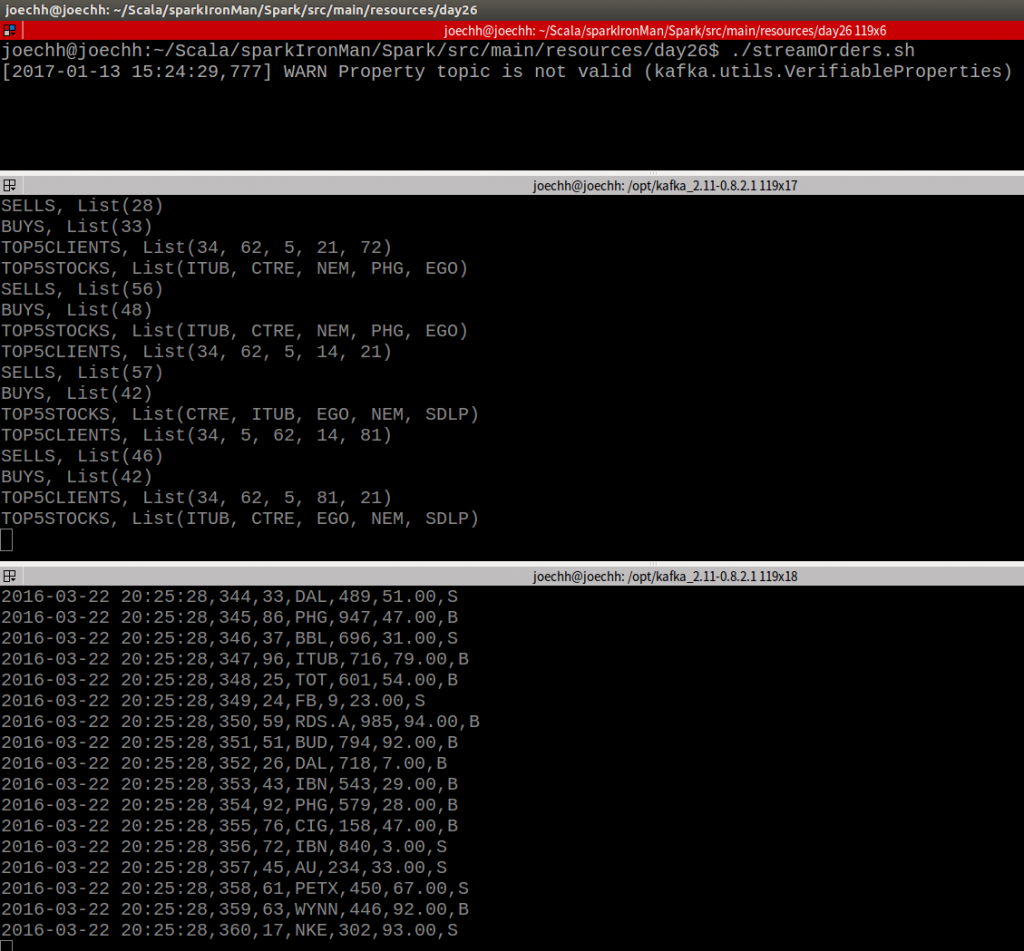



 iThome鐵人賽
iThome鐵人賽