當很多人在同一個房間裡,Alexa需要弄清楚到底誰在說話。一開始比較簡單,當某個使用者說一句喚醒詞"Alexa" Echo對應方向的麥克風就會開啟,並對Alexa說"播放爵士音樂",而在這之後,在使用者身旁的人們可能持續不斷的跟使用者交談,那Alexa到底要如何辨別出到底是誰呼喚她的呢?
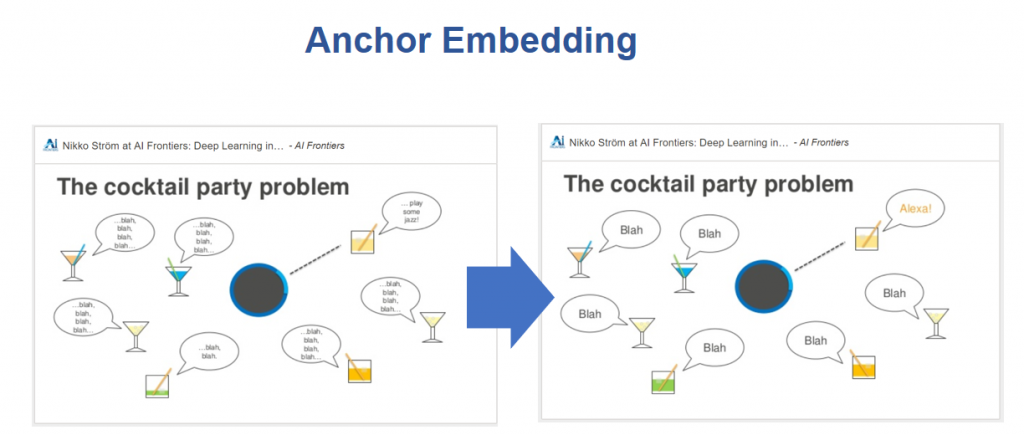
這個問題的解決方案來自2016年的一份論文<錨定語音偵測>(Anchored Speech Detection)
一開始Echo得到喚醒詞"Alexa",並使用一個遞迴神經網路RNN(RNN是為了對序列數據進行建模而產生的)從中擷取一個錨定嵌入(Anchor Embedding), 這代表喚醒詞裡包含語音特徵。接下來,用另一個不同的RNN,從後續要求敘述中擷取語音特徵,基於此得出一個端點決策,這就是Amazon解決雞尾酒派對難題的方法。
語音合成的步驟一般包括
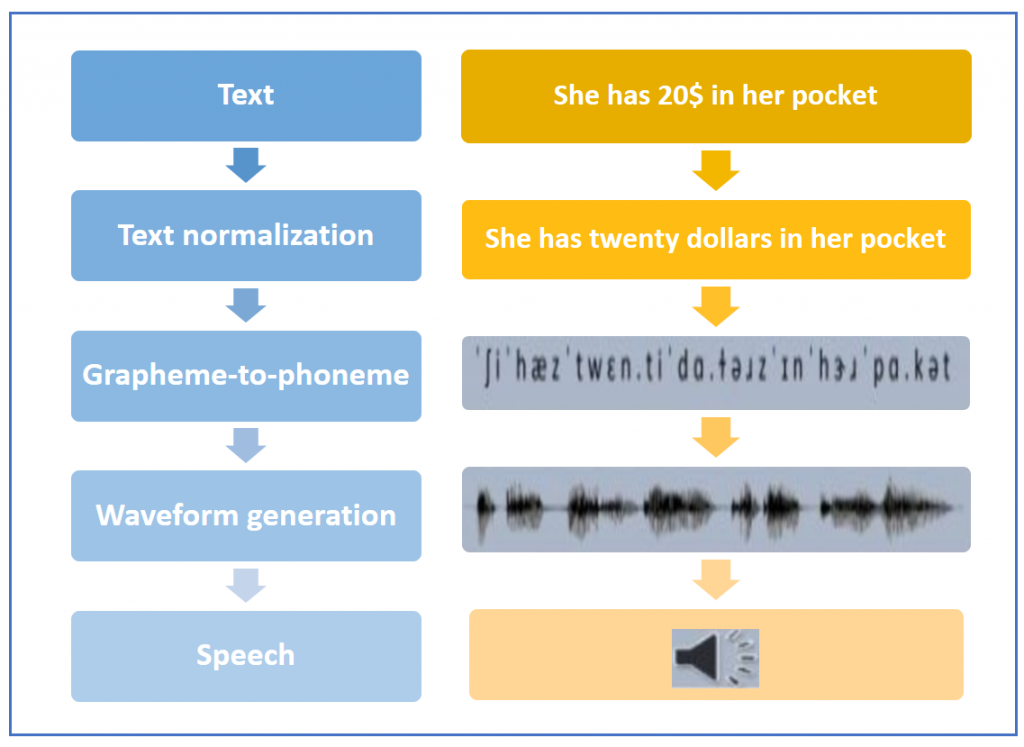
Alexa擁有連續的語音合成。Amazon的專案團隊錄製幾千小時的人類自然發音聲訊,然後得其切割成非常小的片段,由此生成一個資料程式庫。這些切割片段稱為”雙連音片段”。雙連音由一個音素的後半段和後一個音素的前半段組成。最終把語音整合起來時,聲音聽起來的效果就比較好。
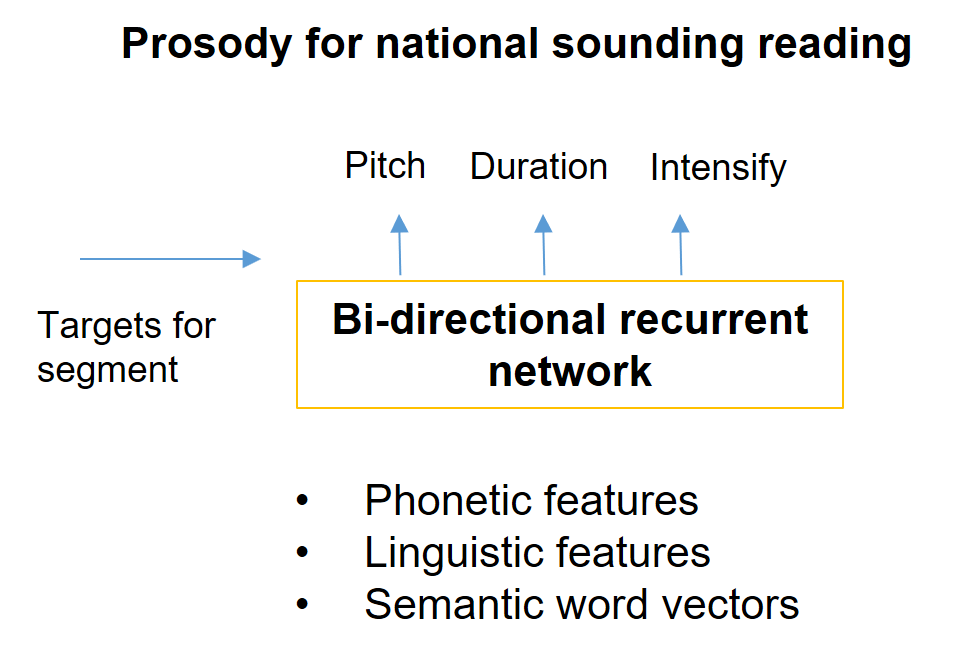
建立這個資料程式庫要高度細緻,並且需保證整個資料程式庫裡片段的一致性。另外一個重要環節是演算法方面,如何選擇最佳片段串列結合在一起形成最終的波形。一開始就要用清楚目標函數為何,來確保得到最適的"雙連音片段"以及如何從龐大的資料庫蒐集到此片段。比如說把這些片段標籤上屬性,分別是音高(Pitch)長度(duration)和密度(intensity)我們也要用RNN為這些特徵找到目標值。

(本文為擷取TechNews雞尾酒派對部分和雙連音來為大家做分享,請詳以下資料來源)
資料來源: TechNews, Association of Technology and Innovation



 iThome鐵人賽
iThome鐵人賽