延續AI NEXT大會揭密Alexa是怎麼練成的Topic
這次的主題是聲學模型的部分
跟各位介紹一下,語音辨識系統框架主要包含四大部分->分別是 1.訊號處理 2. 聲學模型 3. 解碼器 4. 後端處理

首先,Alexa會對麥克風蒐集來的聲音,進行一些訊號處理,將訊號轉換到頻域,從每10毫秒語音提出一個特徵向量,提供給後面的聲學模型。聲學模型負責把聲訊分類成不同的音素。接下來就是解碼器,可以得出概率最高的 一串詞串,最後一步是後端處理,就是將單詞組合而成容易讀取的字檔。
在這過程當中,都會用到機器學習和深度學習的部分。
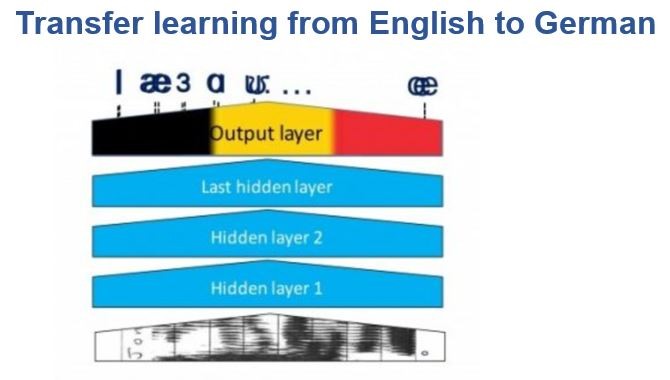
聲學模型為一個分類器,底部是匯入資訊,隱藏層將向量轉化到最後一層裡的音素概率,這是一個典型的神經網路。
Alexa是一個美式英語的語音辨識系統,所以會匯出美式英文中的各個音素。在Echo初發表時,Amazon錄製了幾千小時的美式英語語音來訓練神經網路模型。
2016/9發行德語版Echo,如果從頭來過一遍用幾千個小時德語語音來訓練,成本相當高。所以這個神經網路模型很棒的地方,就是可以透過”遷移學習”,保持原有網路其他層不變,只把最後一層換成德語。
兩種不同的語言,音素很多不一樣,但仍然有很多相同的部分,所以,可以只使用少量的德語的訓練資料,在稍作改變的模型上最終可以得到不錯的結果。

(本文為擷取TechNews聲學模型部分來為大家做分享,請詳以下資料來源)
資料來源: TechNews, Association of Technology and Innovation


