
K過『自動語音識別』(Automatic Speech Recognition)後,原想對聲音的研讀要告一段落,沒想到柳暗花明又一村,又看到 Machine Learning 應用到音樂領域也是非常熱門,所以,我們這一篇就來討論『音樂資訊檢索』(Music Information Retrieval,MIR),說明在先,我對音樂一竅不通,如有謬誤,還請海涵。
『音樂資訊檢索』(Music Information Retrieval,MIR)應用相當廣,而且都很實際,『What is Music Information Retrieval?』列舉下列應用:
fingerprinting(音訊指紋)
cover song detection(口水歌偵測)
genre recognition(曲風辨識)
transcription(轉錄)
recommendation(推薦)
symbolic melodic similarity(相似性比對)
mood(音樂情緒)
source separation(音源分離)
instrument recognition(樂器辨識)
pitch tracking(音高追蹤),可參閱Audio Signal Processing and Recognition (音訊處理與辨識)
tempo estimation(節奏)
score alignment(給分)
song structure/form(歌曲結構)
beat tracking(音樂節拍辨識)
key detection(音階偵測)
query by humming(哼唱選歌)
本來完全看不懂,剛好搜尋到台大MIR實驗室的招生簡章,一比對,大部分都懂了:
- 哼唱選歌(query by singing/humming, QBSH):由哼唱來辨識所唱的歌。
- 口水歌偵測(cover song identification):抽取主旋律來進行辨識,達成口水歌偵測的任務。(口水歌的範例:傳統的「望春風」以及陶吉吉搖滾版的「望春風」,或是張惠妹和孫燕姿的「原來你什麼都不要」。)
- 音訊指紋比對(audio fingerprinting):又稱為原曲選歌,亦即如何以被雜訊污染後的原曲音樂聲來辨識此首歌曲。
- 歌聲評分:如何讓電腦根據節拍、音調、咬字、音色、抖音等,來對你的歌聲進行評分,如同日本的「關八比賽」一般。
- 歌詞與音樂同步化:自動由audio music產生同步變色的歌詞。
- 音樂節拍辨識(beat tracking):由一段音樂來自動抓到此音樂的拍點。
- 音樂曲風分類(music genre classification):如何辨識一段音訊音樂(audio music)的曲風(例如交響樂、鄉村樂、重金屬、饒舌、搖滾、迪斯可等)。
- 音樂情緒辨識(music mood classification):如何辨識一段音訊音樂所要表達的情緒,例如快樂、憂愁、亢奮、勵志等不同情緒類別。
- 音訊音樂的主旋律抽取(audio melody extraction):如何自動從複音音訊音樂(polyphonic audio music)中,自動抓出人聲的主旋律。
- 敲擊選歌:如何由一個人敲擊節拍(或拍手)的方式來辨識所敲擊的歌。
- 遊戲應用:音樂敲擊遊戲、打鼓練習遊戲。
以 Neural Network 可著力的地方還真不少,以上列舉的幾乎都是分類(Classification)與辨識(Prediction),正是 Neural Network 的長處,而且在世界流傳的音樂數量又多不可數,訓練資料也容易取得。
之前我們介紹過語音如何轉化為MFCC特徵向量,再由程式來處理。基本上,音樂也是一種語音,也是可以相同的方式處理,但是,音樂還有三個特徵要考慮:
透過上面三個特徵組合,我們就可以進一步辨識節拍、曲風(genre,搖滾、爵士、古典...)、情緒(mood,快歌、慢歌、抒情...)等等。
Neural Network 最簡單的作法,其實與『自動語音識別』(Automatic Speech Recognition)大同小異,只要將辨識對象由單字類別改為曲風或情緒類別,每個歌曲取一小段轉成MFCC特徵向量,以CNN或RNN進行訓練,就完成了。但是,為了針對音樂的特徵作更細緻的辨識,就有各種變形的CNN/RNN演算法出現,例如 CRNN(convolutional recurrent neural network),它是作曲風的辨識,請看下圖,與不同的CNN模型作比較。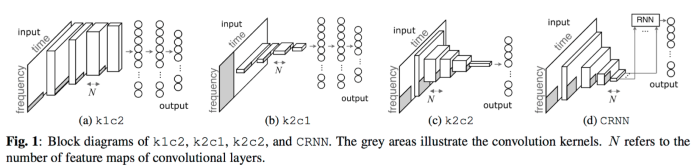
圖. CRNN 與不同的 CNN 模型作比較,圖片來源:Convolutional Recurrent Neural Networks for Music Classification
照例我們舉一範例說明,上述的CRNN係以TensorFlow撰寫,較不易講解,所以,我找了一個比較簡單的範例來說明,程式來源為 https://github.com/Hguimaraes/gtzan.keras ,它主要是使用CNN模型辨識曲風,模型如下,是標準的多層式模型:
def cnn_melspect_1D(input_shape):
kernel_size = 3
#activation_func = LeakyReLU()
activation_func = Activation('relu')
inputs = Input(input_shape)
# Convolutional block_1
conv1 = Conv1D(32, kernel_size)(inputs)
act1 = activation_func(conv1)
bn1 = BatchNormalization()(act1)
pool1 = MaxPooling1D(pool_size=2, strides=2)(bn1)
# Convolutional block_2
conv2 = Conv1D(64, kernel_size)(pool1)
act2 = activation_func(conv2)
bn2 = BatchNormalization()(act2)
pool2 = MaxPooling1D(pool_size=2, strides=2)(bn2)
# Convolutional block_3
conv3 = Conv1D(128, kernel_size)(pool2)
act3 = activation_func(conv3)
bn3 = BatchNormalization()(act3)
# Global Layers
gmaxpl = GlobalMaxPooling1D()(bn3)
gmeanpl = GlobalAveragePooling1D()(bn3)
mergedlayer = concatenate([gmaxpl, gmeanpl], axis=1)
# Regular MLP
dense1 = Dense(512,
kernel_initializer='glorot_normal',
bias_initializer='glorot_normal')(mergedlayer)
actmlp = activation_func(dense1)
reg = Dropout(0.5)(actmlp)
dense2 = Dense(512,
kernel_initializer='glorot_normal',
bias_initializer='glorot_normal')(reg)
actmlp = activation_func(dense2)
reg = Dropout(0.5)(actmlp)
dense2 = Dense(10, activation='softmax')(reg)
model = Model(inputs=[inputs], outputs=[dense2])
return model
其他部分與『自動語音識別』(Automatic Speech Recognition)的範例均相同,只是撰寫語法不同而已,就不再介紹。
必須下載GTZAN資料集,範例提供較小的資料集,你也可以下載完整的GTZAN資料集,下載的檔案解壓縮後放在一目錄下,修改 params.ini 的內容,例如下面的內容:
[FILE_READ]
TYPE = AUDIO_FILES
GTZAN_FOLDER = D:/0_DataMining/Audio/MIR/Samples/0_Music Genre classification on GTZAN dataset using CNN/gtzan.keras-master/dataset/genres/
#../dataset/GTZAN/
SAVE_MODEL = ../models/gtzan_hguimaraes.h5
SAVE_NPY = False
...
執行下列指令即可:
python train.py
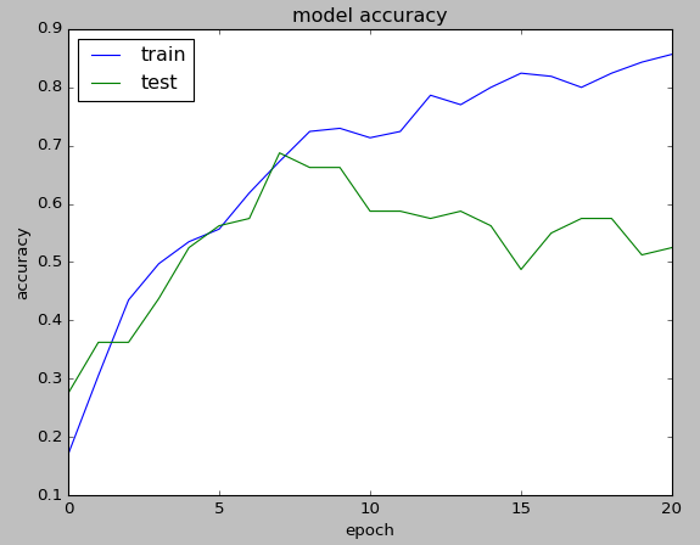
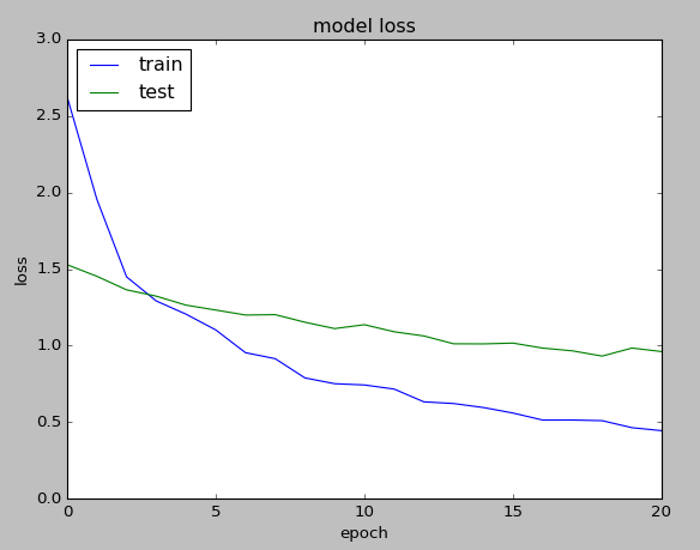
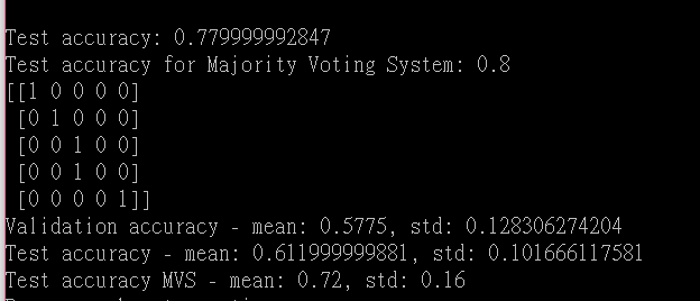
以上的範例可以延伸到MIR的其他應用,可以花點時間想想,另外,筆者看電視常看到『A藝人模仿B藝人的音色唱歌』,很有娛樂效果,突發奇想,如果能比照之前討論的『畫風轉換』,將『A藝人的音色套到B藝人的歌曲』,是不是可行呢?沒想到老外也已有類似的作法,請參閱這一篇『Timbre modification using deep learning』,65頁, 。
。


 iThome鐵人賽
iThome鐵人賽