前一篇文章有提到,無論 blob 物件與 tree 物件,這些都算是物件,這些物件都會儲存在一個所謂的「物件儲存區」 (object storage) 之中,而這個「物件儲存區」預設就在「儲存庫」的 objects 目錄下,如下圖示:

然而 Git 儲存庫中的每一個「物件」,都是以「檔案內容」進行 SHA1 雜湊運算出一個 hash 值,並用這個 hash 值當作物件的名稱 (檔名)。我們以 8a6b275638f3cf164395e65066a1132bb36b7896 為例,Git 會先拿前兩個字元(8a)當作目錄,然後把剩下的 hash 值當成檔名 (6b275638f3cf164395e65066a1132bb36b7896),這些物件的實體目錄與檔案也都會放在 .git\objects 目錄下,如下圖示:

在這些「物件資料庫」裡面,又包含了 4 種物件類型,分別是:
Git 會將每一個版本中的檔案建立一個對應的 blob 物件,一樣的,該 blob 物件的檔名就是用上述的方式計算出來的,從這些 blob 檔案,你看不出跟版本有任何關係,你必須透過 tree 物件 (資料夾的快照) 與 commit 物件 (每一個版本的快照) 才能關聯出這些 blob 與版本的關係。
所有的物件都會以 zlib 演算法進行壓縮,不但可以有效的提升檔案存取效率,在日後進行封裝(pack)的時候也可以利用差異壓縮(delta compression)演算法來節省空間。他會自動找出相似的 blobs,並自動計算出 blob 之間的變化差異,再將這些差異儲存在一個名為 *packfile* 的檔案中,這樣就可以大幅節省磁碟空間的耗用)。通常 *packfile* 會置於 .git\objects\pack 目錄下,如下圖示:

上述這四種物件之間的關係,可參考以下圖示:
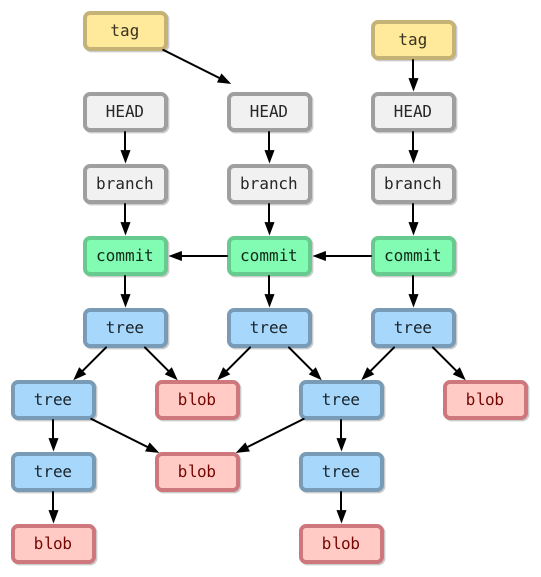
然而,光是觀看文字與圖示,或許還是難以看出這幾種物件類型之間的關係,沒關係,筆者特別錄製了一段教學影片,試圖用 git 指令的方式解釋 Git 的物件結構與產生物件的過程,也讓各位更清楚的了解到底 Git 如何產生與管理這些檔案。
以下是我錄製的教學影片,透過影片的解說,應該更能夠了解 Git 資料結構中的物件資料庫與物件之間的關係 (記得切換至 HD 模式或全螢幕觀看):
影片網址: https://www.youtube.com/watch?v=PZbSRy_ow0U
你應該可以漸漸了解 Git 的「物件」設計是如此的漂亮,我們在第一篇文章曾經提到幾個 Git 重要的設計,我們重新列出幾點與「物件」特性有關的設計來看看:
* 有效率的處理大型專案
Git 裡的「物件」十分重要,其特性也十分重要,雖然我們在操作 Git 指令的過程中通常不太需要直接接觸這些檔案,不過了解這些物件的存在,也確實有助於讓你更加理解 Git 的運作模式,與 Git 獨到的設計概念。
* Git Internals - Git Objects
* Pro Git Book
* Git Magic - 繁體中文版
* Git (software) - Wikipedia, the free encyclopedia
想請問一下,重新封裝(repacking)時,會是將所有內容重新封裝?還是只將尚未封裝的內容再封裝成一個 pack 呢?
想說如果是後者,是否有可能太頻繁的封裝反而造成不好的效果呢?
補充剛剛用 git gc 測試了,會是前者的結果。
他將所有內容最後重新封裝成單一 pack。
(原本有約 10 個 pack,也全部合在一起了)
自動封裝,應該是只會將新的內容封裝,而不會動到舊的 pack
因為在使用 git gc 前,我的專案中有非常多 packgit gc 後才將舊的 pack 也合併。整理如下
自動封裝:將鬆散物件封裝成 pack,並刪除被封裝的物件git gc:將鬆散物件封裝,再將可以合併的 pack 合併
(BTW, GPT 也是這樣說的XD)
也可以設定自動封裝要在什麼條件下進行合併 pack,
可對 gc.autoPackLimit 進行設定 pack 的數量上限


