接下來會帶到Hive的應用實做,如果想要把Script紀錄起來,
就可以用Hue Beeswax(Hive UI),還可以用介面寫UDF,蠻方便了。
這次也是使用同樣的資料集...(沒梗XD)
Hive可以先把它當成趴字串的一個引擎,例如有一個用逗號來分隔的CSV檔,
你可以對那個檔案執行SQL的指令。
建立與匯入
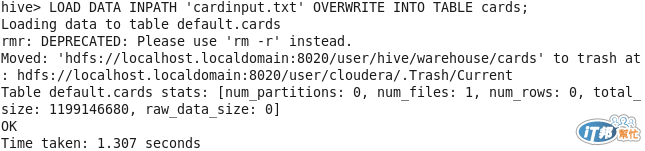
首先我先建立一個Table,Hive在建立的時候,要指定這個Table有幾個欄位,用什麼來做分隔。
再將上次的資料集匯入這個Table。
CREATE TABLE cards (kinds STRING,number STRING) ROW FORMAT DELIMITEDS TERMINATED BY ' ';
LOAD DATA INPATH 'cardinput.txt' OVERWRITE INTO TABLE cards;
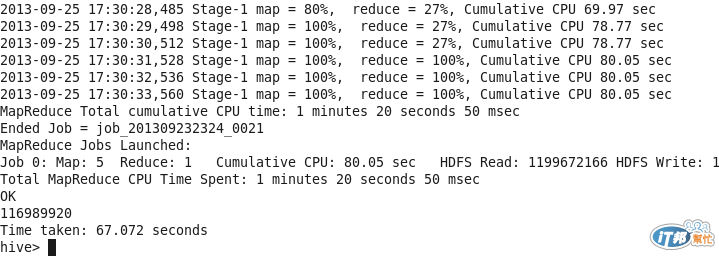
運算測試
因為還沒切partition,所以可以看到沒有做分隔。為了來看Hive在運算的結果,
我直接下Count(*)來看結果。
select count(*) from cards;
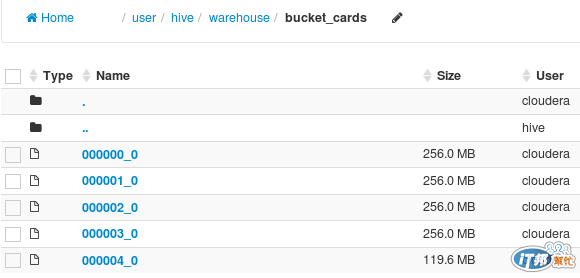
Bucket&Partition
Hive也可以在塞資料的時候進行檔案分割,有bucket與partition。
bucket和partition的效果不太一樣,前者可以幫助檔案做平均分散,可讓I/O平均分散運作,partition則是讓資料量變少。
來看看如果用bucket 來存放這些資料,會有什麼差異?
CREATE TABLE bucket_cards (kinds STRING, number STRING) CLUSTERED BY (kinds) into 4 buckets;
//接著倒入剛才的原始資料
INSERT OVERWRITE TABLE bucket_cards SELECT * from cards;
來看看倒入HDFS的內容為何?