今天要介紹另外一種在Mesos上執行Spark的方式,在介紹之前先來看一下這兩種執行方式差異的地方。
它們主要的差異的地方有以下兩點:
1.昨天的執行方式是在Spark啟動之後Framework才會啟動起來,今天要介紹的方式是Framework先啟動起來,等待spark-submit連線進來
2.SparkDriver執行的位置不一樣如下圖

昨天我們執行的方式如上圖spark driver會直接在spark-submit執行的那台主機上所以它的deploy mode是local,而今天我們要執行的方式如下圖:

sparkDriver會執行在Mesos Cluster上,所以它的deploy mode是cluster。主要是透過spark-mesos-dispatch server的方式去執行,以下就是實際操作的方法:
啟動mesos cluster dispatcher指令如下:
# cd spark-2.0.1-bin-hadoop2.7/sbin
# ./start-mesos-dispatcher.sh --master mesos://192.168.182.132:5050
執行了spark-mesos-dispatch,spark的framework也就被啟動起來了,可以在Mesos WebUI看到如下圖:
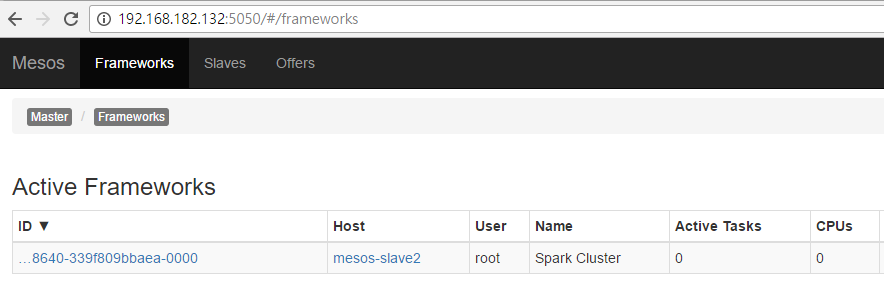
看到上面的圖之後,就表示spark的Framework已經執行在Mesos上了,接下來就可以執行spark在mesos平台上了。
執行spark-submit指令如下:
# cd spark-2.0.1-bin-hadoop2.7/bin
# ./spark-submit –deploy-mode cluster –class org.apache.spark.examples.SparkPi –master mesos://192.168.182.133:7077 ../examples/jars/spark-examples_2.11-2.0.1.jar 1000
執行如下:
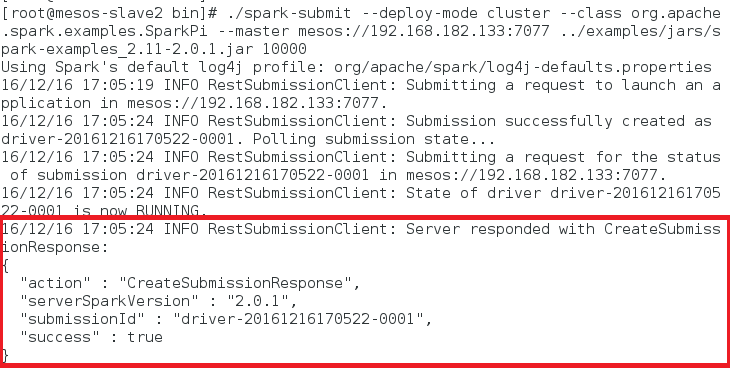
看到上圖就成功送出了job到mesos上執行了
這二天已經簡單的介紹如何在mesos上執行spark,它的deploy-mode方式有二種local mode和cluster mode,在下spark-submit要注意deploy-mode如果下錯是無法執行的。
如果想要更深的了解相關細節可以參考它的官網
參考資料:
Apache Spark:http://spark.apache.org/docs/latest/running-on-mesos.html


