前面幾天都是在介紹Mesos的資源分配的部份,今天要來介紹使用Apache Spark執行在Mesos的平台上。
Apache Spark是什麼?
Apache Spark主要可以用在關於Big Data上的處理資料、運算資料、分析資料…等等的功能,它的優點是在In Memory的存放資料,而且在每個階段可以有效的做資料共用,如果對Apache Spark有興趣可以到它們的官網查看相關的文件資料。
Apache Spark可以在哪些平台上執行?
Apache Spark可以執行在很多的平台上如:在本機執行、Standalone、Yarn、Mesos…等等所以可以在很多的平台上執行,我們今天主要是使用Mesos的平台來執行Spark分散運算。
安裝前準備:
1、啟動Mesos Master,可以參考Day3
2、啟動Mesos Slave,可以參考Day3
3、每台的Mesos Slave都需要下載Apache Spark的執行程式
下載指令如下:
# wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.1-bin-hadoop2.7.tgz -P /opt
下載完之後要把壓縮檔的程式解壓縮,指令如下:
# cd /opt && tar zxvf /opt/spark-2.0.1-bin-hadoop2.7.tgz
執行Apache Spark程式:
在其中一台mesos slave上執行以下的指令,如下:
[root@mesos-slave1 ~]# cd /opt/spark-2.0.1-bin-hadoop2.7/bin
[root@mesos-slave1 bin]# ./spark-submit --class org.apache.spark.examples.SparkPi --master mesos://192.168.182.132:5050 ../examples/jars/spark-examples_2.11-2.0.1.jar 20000
spark-submit後面的class是spark提供執行pi的example,然後需要指定mesos master的IP位址加上PORT,20000是spark pi要求需要傳入的參數數字遇大執行遇久
執行的結果如下:
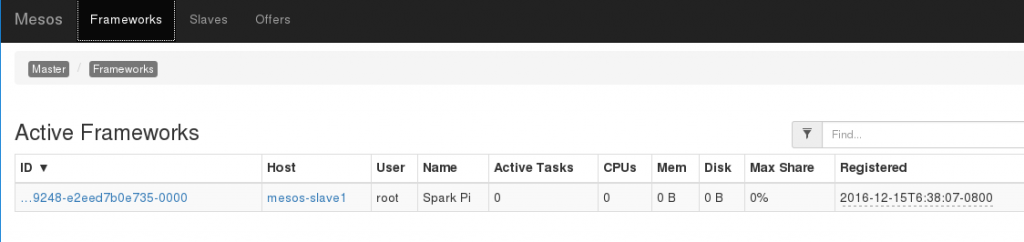
之後在執行的ternimal上可以看到計算結果:
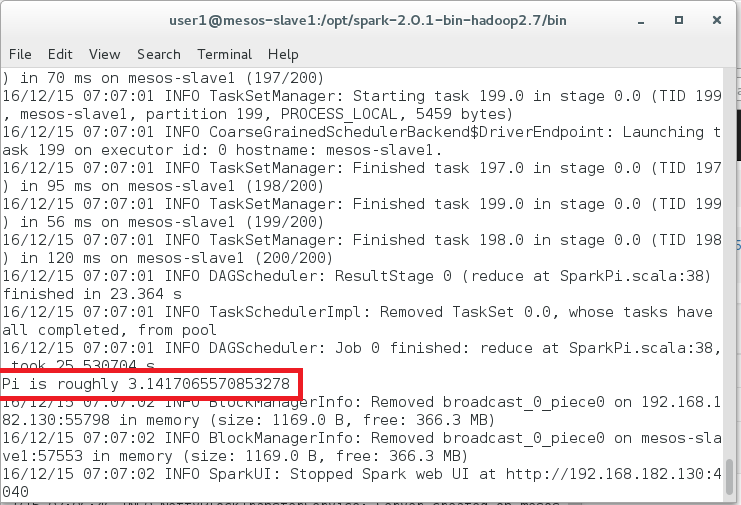
以上是使用在Mesos平台上執行Spark的方式之一,明天還會再介紹其它的執行方式,以及這兩種方法之間的差異。
參考資料:
Apache Spark:http://spark.apache.org/docs/latest/running-on-mesos.html


