上一篇文章已經把 check 功能實作出來,並且可以正常運作取得最新的版本。
但是因為還沒有實作 in 的部分,所以仍然沒辦法讓工作正常運行起來。
初期的準備基本上跟 check 完全一樣,我們會從 STDIN 得到一個包含 source 和 version 物件的 JSON 字串。
#!/usr/bin/env ruby
require 'net/http'
require 'json'
input = JSON.parse(STDIN.gets)
source = input["source"] || {}
version = input["version"] || {"version" => "0.0"}
major, minior = version["version"].split(".")
這次不同的是 Concourse 在執行 in 的時候,會帶入一個參數給我們。這個參數會是一個路徑,像是 /tmp/1f963da5 之類的值,代表我們要將從資源上存取下來的檔案放到哪個目錄。
dest = ARGV[0]
接下來基本上跟 check 的做法一樣,呼叫我們的 API 伺服器將資料存取出來。
uri = URI(source["uri"] + '/v1/monsters')
uri.query = URI.encode_www_form({major: major, minior: minior})
res = Net::HTTP.get_response(uri)
monsters = JSON.parse(res.body)
這邊我們假設最後生成的是一個有怪物資料的 CSV 檔(其實也可以透過伺服器生成)我們要將 JSON 資料轉換成 CSV 格式並且存到這次要使用的目錄中,命名成 monsters.csv 這個檔名。
output = []
monsters.each do |monster|
output << monster.join(",")
end
monster_db_file = File.join(dest, "monsters.csv")
File.write(monster_db_file, output.join("\n\r"))
雖然完成了寫入檔案的動作,但是 Concourse 仍不知道結果為何,所以我們還是需要對 STDOUT 輸出一些資訊讓 Concourse 了且情況。
雖然執行的狀態碼不等於零也會出現錯誤,但是這邊可以提供一些額外資訊。
像是這個範例就會回傳怪物數量的統計。
result = {
"version" => version,
"metadata" => [
{"name" => "count", "value" => monsters.size.to_s}
]
}
STDOUT.puts result.to_json
完整的程式碼如下。
#!/usr/bin/env ruby
require 'net/http'
require 'json'
input = JSON.parse(STDIN.gets)
source = input["source"] || {}
version = input["version"] || {"version" => "0.0"}
major, minior = version["version"].split(".")
dest = ARGV[0]
uri = URI(source["uri"] + '/v1/monsters')
uri.query = URI.encode_www_form({major: major, minior: minior})
res = Net::HTTP.get_response(uri)
monsters = JSON.parse(res.body)
output = []
monsters.each do |monster|
output << monster.join(",")
end
monster_db_file = File.join(dest, "monsters.csv")
File.write(monster_db_file, output.join("\n\r"))
result = {
"version" => version,
"metadata" => [
{"name" => "count", "value" => monsters.size.to_s}
]
}
STDOUT.puts result.to_json
既然已經將 in 實作好了,我們就可以透過修改 Hello Wolrd 使用的範例來測試。
resource_types:
- name: game-db
type: docker-image
source:
repository: elct9620/concourse-example-custom-resource
tag: latest
resources:
- name: monster-db
type: game-db
source:
uri: http://version-server.example.com
jobs:
- name: monster
plan:
- get: monster-db
trigger: true
- task: load
config:
platform: linux
image_resource:
type: docker-image
source: {repository: ubuntu}
inputs:
- name: monster-db
run:
path: cat
args: ["monster-db/monsters.csv"]
上述將 Hello World 範例的 time 替換成自訂的 game-db 類型,並且將執行指令改為 cat monsters.csv 將我們生成的資料輸出。
設定完成 Pipeline 之後,就可以看到像這樣的畫面。
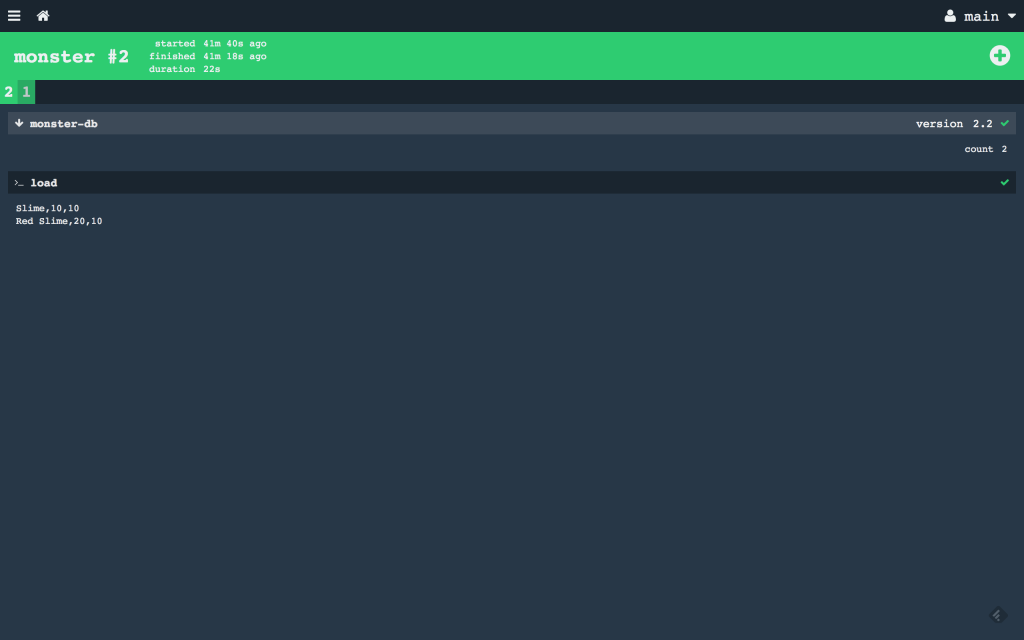
到這個階段,就剩下 out 的部分需要實作。下一篇會介紹 out 的實作部分。


