本系列文章內容同步發佈於這裡,若有任何問題或錯誤,都歡迎直接到 GitHub 上發 PR 修正,或是在這裡留言討論。
前面介紹過 Rails 的 MVC 架構的 V 跟 C,接下來的幾個章節將主要介紹 M。
很多剛開始接觸 Rails 的 MVC 架構的新手,可能會認為 Model 就是資料庫,事實上並不是。請先記住一件很很重要的觀念:
Model 不是資料表(Table),Model 只是疊在資料表上面的一個抽象類別,負責跟實體的資料表溝通。
打個比方,Model 的角色有點類似卡通「哆啦 A 夢」裡有種叫做「翻譯蒟蒻」的道具,我們跟 Model 說人話,Model 會幫我們翻譯成資料庫看得懂的話(SQL),幫我們跟資料庫要資料。
講到 Model 跟資料表的關係,剛開始學習 Rails 的新手常會認為一個 Model 就會對到一個資料表,一個資料表就一定也有一個對應的 Model。在比較單純的專案,Model 跟資料表通常的確是一對一沒錯,但這並不是絕對的。
在 Rails 專案中,Model 的命名是單數(而且必須大寫,因為在 Ruby 的類別名稱必須是大寫),而資料表的命名則是複數(因為可以放很多資料?)、小寫並以底線分隔。
| Model 名稱 | 資料表名稱 |
|---|---|
| User | users |
| Category | categories |
| OrderItem | order_items |
這是 Rails 的預設慣例,通常這些事不用我們特別煩惱,因為在 Rails 的 Model 產生器在幫我們產生 Migration 的時候,都會自動幫我們依照慣例設定表格名稱。但如果一些其它因素要修改,可在 Model 加上 table_name 方法來調整。例如有一個叫做 User 的 Model,但希望對到的資料表名字叫做 accounts:
class User < ActiveRecord::Base
self.table_name = "accounts"
end
只是,在 Rails 中我們會儘量遵守「慣例優於設定」(CoC, Convention over Configuration)的原則,順著預設的慣例做,可以省下不少麻煩。
讓我們看一下這個 Migration 檔的內容:
class CreateUsers < ActiveRecord::Migration[5.0]
def change
create_table :users do |t|
t.string :name
t.string :email
t.string :tel
t.timestamps
end
end
end
大概猜得出來它會有 name、email 以及 tel 三個欄位,執行 Migration 之後,如果使用資料庫檢視工具(我使用的是DB Browser for SQLite)看一下這個資料表的樣子:
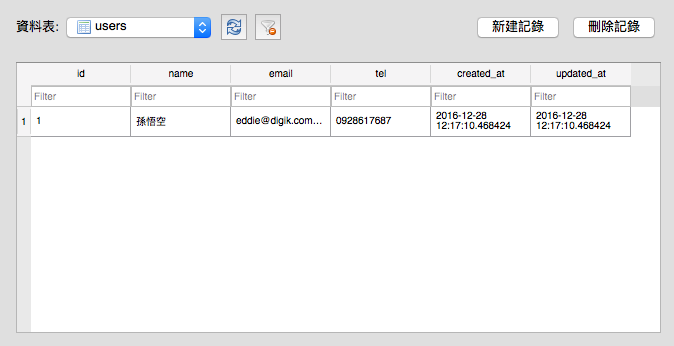
會發現除了上面這三個欄位之外,還多了 id、created_at 跟 updated_at 三個欄位。事實上,在 Migration 檔案中的 t.timestapms ,在經過轉換之後,會產生兩個名為 created_at 跟 updated_at 的時間欄位,分別會在資料「新增」及「更新」的時候,把當下的時間寫進去,完全不需要我們煩惱。
而 id 欄位你在 Migration 沒看到任何資訊,這是 Rails 自動幫每個資料表加的流水編號欄位,這個欄位稱為資料表的主鍵(Primary Key)。
如果你不想要這個主鍵,可以在 Migration 的時候加上 id: false 參數:
class CreateUsers < ActiveRecord::Migration[5.0]
def change
create_table :users, id: false do |t|
t.string :name
t.string :email
t.string :tel
t.timestamps
end
end
end
如此一來 Migration 在轉換的過程就不會自動產生 id 欄位了。慣例上,Rails 的 Model 是用 id 做為主鍵的命名,但也許你接手了某個其它程式語言或框架開發的系統,它的主鍵命名叫 user_id,那也可以修改 Rails 的慣例來符合這個需求:
class User < ActiveRecord::Base
self.primary_key = "user_id"
end
但,如果可以還是儘量不要違反「慣例優於設定」的原則。
ORM 是 Object Relational Mapping 的縮寫,中文翻譯成物件關係對映。我們如果想要存取資料庫裡的內容,以前必需透過資料庫查詢語言(SQL)向資料庫進行查詢,但透過 ORM 的包裝之後,可以讓我們用操作「物件」的方式來操作資料庫。例如如果我想要找出所有 users 資料表裡的資料:
User.all
透過轉換之後會變成:
select * from users`
要新增一筆資料,常見有 new 跟 create 兩種方式。使用 new 方法做出一個 Model 物件後,再執行 save 方法即可把該筆資料存入資料表:
user = Candidate.new(name: "孫悟空", age: 18)
user.save
使用 create 方法也可新增資料,但不需要執行 save 方法即可寫入資料表:
Candidate.create(name: "孫悟空", age: 18)
new 跟 create 的差別,就是 new 方法只是先把物件做出來,尚未存入資料表,而 create 方法則是直接把存入資料表。不管是 new 或 create,在寫入失敗的時候都會回傳一個「內容都是 nil 的 Model 物件」,通常在 Controller 的 Action 裡常會藉此判定資料寫入是否成功:
class PostsController < ApplicationController
# ...[略]...
def create
@post = Post.new(post_params)
if @post.save
redirect_to @post, notice: 'Post was successfully created.'
else
render :new
end
end
end
另外,create 方法有另一個叫做 create! 的兄弟方法(沒錯,就是後面加了驚嘆號版本的),它跟 create 方法一樣會把資料直接寫入資料表,但差別是當寫入發生錯誤時,它會產生例外(Exception)訊息。
從資料表裡讀取資料也是很常見的操作,在讀取的方法就比寫入來得多樣化,有一次讀取一筆的方法,也有一次讀取一整批的方法。
想要取得資料表中的第一筆或最後一筆資料,可使用 first 或 last 方法:
user = Candidate.first # 取得第 1 筆資料
users = Candidate.first(3) # 取出前 3 筆資料並存放在陣列裡
要注意的是,first 本身只會取出 1 筆資料,而 first(3) 雖然是取出前 3 筆資料,但會放在一個陣列裡。Model 預設使用 id 流水編號做為排序,所以如果想要反過來,可以用連續技:
Candidate.order(age: :desc).first # 取出年紀最大的候選人
如果想要找到指定 id 的候選人,可使用 find 或 find_by 方法:
Candidate.find(1)
Candidate.find_by(id: 1)
這兩種方式都可以找到編號是 1 號的候選人。差別是 find_by 方法如果找不到指定 id 的資料,僅會回傳 nil,但 find 方法會直接產生 ActiveRecord::RecordNotFound 的錯誤訊息:
>> Candidate.find_by(id: 9487)
Candidate Load (0.1ms) SELECT "candidates".* FROM "candidates" WHERE "candidates"."id" = ? LIMIT ? [["id", 9487], ["LIMIT", 1]]
=> nil
>> Candidate.find(9487)
Candidate Load (0.2ms) SELECT "candidates".* FROM "candidates" WHERE "candidates"."id" = ? LIMIT ? [["id", 9487], ["LIMIT", 1]]
ActiveRecord::RecordNotFound: Couldn't find Candidate with 'id'=9487
...[略]...
使用 all 方法可取得所有資料,取得資料將存放在陣列裡:
Candidate.all
where 方法則會再加上一些條件做為篩選:
Candidate.where("age > 18", gender: "female")
這樣可取得「女性且大於 18 歲」的候選人。如果要分開兩段寫也是可以:
Candidate.where("age > 18").where(gender: "female")
結果也是一樣的。另外,使用 order 方法可對資料做排序:
Candidate.order(:age) # 按照年齡大小,預設是由小排到大
Candidate.order(age: :desc) # 按照年齡大小,由大排到小
如果想要限制取得筆數,則是使用 limit 方法:
Candidate.order(age: :desc).limit(3)
這樣即可取得「年齡最大的三個候選人」的資料
想要知道總共有多少筆數,可使用 count 方法:
$ rails console
>> Candidate.count
(0.1ms) SELECT COUNT(*) FROM "candidates"
=> 3
如果想要算資料的「總和」或「平均」,很多新手 Rails 工程師想到的可能是「先把全部資料用 all 方法抓出來,然後跑 each 迴圈來計算總和及平均」,但這其實是很笨的方法,不僅速度慢又浪費系統資源。像這種總和或平均值的計算,通常資料庫本身都有直接支援,千萬不要傻傻的抓出來自己轉迴圈算:
$ rails console
>> Candidate.sum(:age)
(0.2ms) SELECT SUM("candidates"."age") FROM "candidates"
=> 44
>> Candidate.average(:age).to_f
(0.1ms) SELECT AVG("candidates"."age") FROM "candidates"
=> 14.6666666666667
使用 sum 或 average 方法就可以請資料庫直接幫我們做計算。
最大值跟最小值也是一樣,千萬不要傻傻的用 all 全部抓出來再跑迴圈或寫什麼排序演算法,直接使用 maximum 或 minimum 方法請資料庫幫你算就好:
$ rails console
>> Candidate.maximum(:age)
(0.2ms) SELECT MAX("candidates"."age") FROM "candidates"
=> 22
>> Candidate.minimum(:age)
(0.2ms) SELECT MIN("candidates"."age") FROM "candidates"
=> 2
更新資料常用的有 save、update、update_attribute 及 update_attributes 方法:
# 先抓出 1 號候選人
candidate = Candidate.find_by(id: 1)
# 使用 save 方法
candidate.name = "剪彩倫"
candidate.save
# 使用 update_attribute 更新單一欄位的值 (注意:方法名字是單數)
candidate.update_attribute(:name, "剪彩倫")
# 使用 update 更新資料,可一次更新多個欄位,且不需要再呼叫 save 方法
candidate.update(name: "剪彩倫", age: 20)
# 使用 update_attributes
candidate.update_attributes(name: "剪彩倫", age: 20)
以上有幾點需要說明一下:
save 方法預設會經過驗證(Validateion,在稍後的章節會介紹)流程,如果驗證失敗將無法寫入。如果想要跳過驗證,可加上 validates: false 參數。update 跟 update_attributes 其實只是名字不一樣,但事實上是一模一樣的內容。update_attribute 方法會跳過驗證(Validation),等於是 save(validate: false) 的效果,在使用的時候要稍微注意一下。另外,也可以直接針對整個資料表下手:
Candidate.update_all(name: "剪彩倫", age: 18)
這樣就可以一口氣把所有候選人的資料的姓名跟年齡都改成一樣的,所以在使用這個方法的時候要特別留意。
刪除資料就相對單純,可以使用 delete 或 destroy 方法:
candidate = Candidate.find_by(id: 1)
# 把這筆資料刪除
candidate.destroy
candidate.delete
destroy 跟 delete 的差別,在於 destroy 方法在執行的時候,會執行完整的回呼(Callback,在稍後的章節會介紹),但 delete 方法僅直接執行 SQL 的 delete from ... 語法,不會觸發任何回呼。
除了把資料抓出來再進行刪除外,也可直接從資料表來下手:
# 刪除編號是 1 號的資料
Candidate.destroy(1)
Candidate.delete(1)
# 刪除所有未成年的候選人
Candidate.destroy_all("age < 18")
像是 where、order、limit 這些方法通常可以串在一起使用,可以寫出這樣的語法:
Candidate.where("age > 18").where(gender: "female").limit(2).order(age: :desc)
不需要擔心連續兩次的 where 方法或是這樣一直連下去會造成多次的查詢,事實上 Rails 在處理這行語法的時候,是先整行語法解讀完才向資料庫進行查詢。
偶爾會看到新手 Rails 工程師會這樣寫:
class CandidatesController < ApplicationController
# ...[略]...
def index
@candidates = Candidate.all.where("age > 18")
end
end
或是:
class CandidatesController < ApplicationController
# ...[略]...
def index
@candidates = Candidate.all.order(age: :desc)
end
end
大家可能認為要先 all 把全部抓出來再來 where 或 order,事實上這邊的 Candidate.all.where(...) 或是 Candidate.all.order(...) 的 all 都是多餘的,因為 where 或 order 本身都可以回傳 ActiveRecord::Relation 的物件,你可以把 all 方法當做「當沒有其它方法組合的時候」才在用的方法。
上面大概看過了 Model 的 CRUD 操作,例如,我想要找出「現在可以上架販售的商品」,條件是「is_available 欄位標記為 true 的資料」,可能會在 Controller 這麼寫:
class ProductsController < ApplicationController
# ...[略]...
def index
@products = Product.where(is_available: true)
end
# ...[略]...
end
這樣寫其實沒什麼問題,但如果 where 的條件越來越長,Controller 的程式碼就越來越不容易維護。而且所謂的「現在可以上架販售的商品」,如果哪一天老闆要求說要再加上「售價至少要大於 0 元」的限制,那全站所有地方都需要跟著修改,相當不方便。
通常我們會把這種所謂的「商業邏輯」儘量的包到 Model 裡(「現在可以上架販售的商品」就是一種商業邏輯),除了可增加程式碼的可讀性,也可以在各個地方重複使用。
在 Rails 的 Model 有提供一種稱之 scope 的寫法可以讓你完成這件事:
class Product < ActiveRecord::Base
scope :available, -> { where(is_available: true) }
scope :price_over, ->(p) { where(["price > ?", p]) }
end
上面這段範例,定義了 2 個 scope,其實說穿了就是把查詢條件包起來,並且給它一個好記的名字,其中第 2 個 scope 還可以接收參數。定義 scope 之後,原來的這行:
@products = Product.where(is_available: true)
就可以改寫成這樣:
@products = Product.available
不只在 Controller 的程式碼變乾淨了,而且如果哪天老闆改條件說「除了標記成已上線之外,售價還必須大於 0 元」才能販售,你只要把原來 available 的 scope 做一點點修改:
class Product < ApplicationRecord
scope :available, -> { price_over(0).where(is_available: true) }
scope :price_over, ->(p) { where(["price > ?", p]) }
end
這樣就行了。是的,你沒看錯,scope 本身也是可以連在 scope 裡一起用的。
如果你前面在物件導向程式設計那邊還有印象的話,Product.available 的寫法就跟 Ruby 的類別方法沒兩樣,事實上也真的可以這樣寫,效果是一樣的:
class Product < ApplicationRecord
scope :price_over, ->(p) { where(["price > ?", p]) }
def self.available
where(is_available: true)
end
end
通常如果是簡單的條件,我個人會偏好把它放在 scope 裡,如果是比較複雜的條件,則會建議放在類別方法裡(其實要放 scope 也是可以)。
Rails 的 Model 還有提供 default_scope 的方法,可以幫所有的查詢都預設套上這個條件:
class Product < ActiveRecord::Base
default_scope { order('id DESC') }
scope :available, -> { where(is_available: true) }
end
這樣一來,不管你想不想,所有的查詢都會冠上 order 排序,讓我們到 rails console 底下試試看:
$ rails console
>> Product.all
Product Load (1.0ms) SELECT "products".* FROM "products" ORDER BY "products"."id" DESC
>> Product.available
Product Load (0.2ms) SELECT "products".* FROM "products" WHERE "products"."is_available" = ? ORDER BY "products"."id" DESC [["is_available", true]]
>> Product.order(:title)
Product Load (0.2ms) SELECT "products".* FROM "products" ORDER BY "products"."id" DESC, "products"."title" ASC
你可以看到像 Product.all 或 Product.available 明明都沒有加上 order 排序,但翻譯出來的 SQL 查詢都有 ORDER BY 字樣,甚至在最後一個例子想要試著看看能不能用 order 來蓋掉預設的排序,發現也是沒有效果的。
要取消預設的 scope,必須使用 unscope 方法:
$ rails console
>> Product.unscope(:order)
Product Load (0.2ms) SELECT "products".* FROM "products"
>> Product.unscope(:order).order(:title)
Product Load (0.3ms) SELECT "products".* FROM "products" ORDER BY "products"."title" ASC
這樣才能把預設的 scope 的效果移除。
本系列文章內容同步發佈於這裡,若有任何問題或錯誤,都歡迎直接到 GitHub 上發 PR 修正,或是在這裡留言討論。



 iThome鐵人賽
iThome鐵人賽