
調查花了 20 分鐘,寫報告又花了 1 小時。最痛的不是查問題,是把查到的東西整理成報告。
以下這份 RCA 報告,是我用 AI 產出的。
背景:Device Service 的註冊 API 每天冒出 3-6 筆 500 錯誤,持續一週以上。
你先看報告。看完再說它怎麼來的。
這段回答:一眼看完,發生了什麼事?
| 項目 | 內容 |
|---|---|
| 服務 | Device Service — POST /device-service/v1/devices |
| 問題 | 註冊 API 持續出現零星 500 錯誤 |
| 根因 | Stored Procedure 的 Upsert 邏輯用錯欄位,導致 DB 寫入衝突 |
| 影響 | 每日 3-6 筆 500 錯誤(錯誤率 0.0001%),僅影響自動化批次系統 |
| 狀態 | 🟡 監控中,已確認根因,待 RD 修復 |
這段回答:事情的經過,從頭到尾。
| 時間 | 事件 |
|---|---|
| 持續 7 天以上 | Device Service 每天穩定出現 3-6 筆 500 錯誤(非突發,是常態) |
| Day 1 11:50 | Grafana Dashboard 觀察到 500 spike(2 筆) |
| Day 1 14:53 | SRE 啟動調查 |
| ↳ OpenSearch Access Log:確認每日 3-6 筆 500,錯誤率 0.0001% | |
| ↳ OpenSearch App Log:發現 DB duplicate key error | |
↳ 錯誤訊息:Cannot insert duplicate key row with unique index 'UK_hardware_id_valid' |
|
| Day 1 15:30 | 原始碼調查:確認 Stored Procedure Device_Upsert 的 IF EXISTS 使用錯誤欄位 |
↳ 根因確認:SP 用 record_id(流水號)判斷,應該用 hardware_id(設備唯一碼) |
這段回答:問題的根本原因是什麼?
一句話:Stored Procedure Device_Upsert 的 IF EXISTS 使用 record_id(每次請求都會產生新的流水號)判斷設備是否存在,而非使用 hardware_id(設備唯一碼),導致 Upsert 邏輯永遠走 INSERT 路徑。
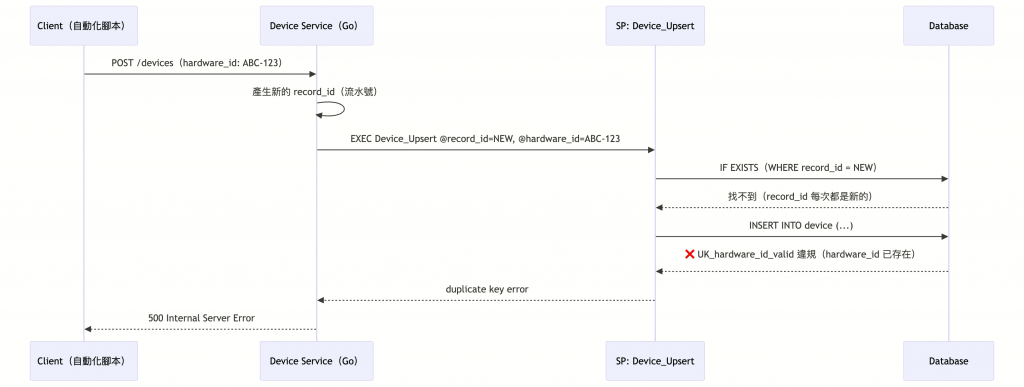
sequenceDiagram
participant Client as Client(自動化腳本)
participant Go as Device Service(Go)
participant SP as SP: Device_Upsert
participant DB as Database
Client->>Go: POST /devices(hardware_id: ABC-123)
Go->>Go: 產生新的 record_id(流水號)
Go->>SP: EXEC Device_Upsert @record_id=NEW, @hardware_id=ABC-123
SP->>DB: IF EXISTS(WHERE record_id = NEW)
DB-->>SP: 找不到(record_id 每次都是新的)
SP->>DB: INSERT INTO device (...)
DB-->>SP: ❌ UK_hardware_id_valid 違規(hardware_id 已存在)
SP-->>Go: duplicate key error
Go-->>Client: 500 Internal Server Error
簡單說:
record_id:流水號,每次請求都是新的
hardware_id:設備指紋,同一台設備永遠相同
SP 用 record_id 判斷 → 永遠找不到 → 永遠 INSERT → 撞到 unique constraint。
-- ❌ 問題:用 record_id(每次都是新的流水號)判斷
IF EXISTS (
SELECT 1 FROM [dbo].[device]
WHERE [record_id] = @record_id -- ← 應該用 hardware_id
AND [is_valid] = 1
)
BEGIN
UPDATE ... -- 永遠走不到這裡
END
ELSE
BEGIN
INSERT INTO [dbo].[device] (...) -- 💥 撞到 unique constraint
VALUES (...)
END
Table Schema:
-- 主鍵是 record_id
CONSTRAINT [PK_device] PRIMARY KEY CLUSTERED (record_id ASC)
-- 但 Unique Index 是 hardware_id + is_valid
CREATE UNIQUE NONCLUSTERED INDEX UK_hardware_id_valid
ON dbo.device (hardware_id, is_valid)
PK 和 Unique Index 用的是不同欄位。IF EXISTS 查 PK,但 constraint 卡的是另一個。
這段回答:嚴不嚴重?目前怎麼應對?
| 指標 | 數值 |
|---|---|
| 每日錯誤數 | 3-6 筆(錯誤率 0.0001%) |
| 持續時間 | 7 天以上(常態性,非突發) |
| 受影響對象 | 自動化批次系統(非終端用戶,不影響設備功能) |
| 目前狀態 | 🟡 監控中,待 RD 安排修復 |
方案 A:修正 IF EXISTS 判斷欄位(推薦)
-- ✅ 改用 hardware_id 判斷
IF EXISTS (
SELECT 1 FROM [dbo].[device] WITH(UPDLOCK, ROWLOCK)
WHERE [hardware_id] = @hardware_id
AND [is_valid] = 1
)
BEGIN
UPDATE ... -- 設備已存在 → 更新
END
ELSE
BEGIN
INSERT INTO [dbo].[device] (...) -- 新設備 → 新增
VALUES (...)
END
方案 B:改用 MERGE(原子操作)
用 SQL MERGE 語法一步完成 Upsert,避免 IF EXISTS 的競爭條件。
方案 C:應用層處理
在 Go 層捕捉 duplicate key error,改回傳 409 Conflict 而非 500,改善錯誤語義。
這段回答:接下來要做什麼?這次學到什麼?
| # | Action Item | Owner | Priority |
|---|---|---|---|
| 1 | 修正 SP Device_Upsert 的 IF EXISTS,改用 hardware_id 判斷(方案 A 或 B) |
RD Team | Medium |
| 2 | 檢查其他 SP 是否有類似的欄位誤用問題 | RD Team | Low |
| 3 | 考慮應用層對 duplicate key error 回傳 409 而非 500 | RD Team | Low |
(報告結束)
調查過程:
三個步驟,同一個對話,20 分鐘。
調查完,一句話:「根據剛才的調查,幫我產出一份 RCA 報告。」
2 分鐘後,你剛才看到的報告就出來了。
AI 已經有完整的調查上下文。不用重新解釋,直接整理成結構化報告。
產出後我花 5-10 分鐘 review — 確認事實、因果鏈、措辭。
從零寫:1-2 小時。Review + 微調:5-10 分鐘。
工具再好,報告的品質最終取決於你的思維。
三個原則。
「SP 用錯欄位」— 很容易寫成「開發者用錯了」。
但 Action items 該指向流程改善,不是指向個人。
AI 在這點有天然優勢:它不帶情緒,只描述事實和因果。
報告的讀者可能是老闆、其他團隊、三個月後的新人。
AI 產出的報告天然帶有「解釋性」— 它不會假設讀者知道所有背景。
這反而是人寫報告容易忽略的。我們太熟自己的系統,會不自覺跳過解釋。
三個月後類似問題又出現。你搜 Confluence,找到這份報告。
因果鏈、程式碼、修復方案,全部都在。不用重新調查。
這也呼應了 #04 — Confluence MCP 搜到的歷史,就是之前有人認真寫的報告。
這篇教你怎麼把查到的東西,變成一份報告。
整個流程的時間對比:
| 階段 | Before | After |
|---|---|---|
| 搜歷史 | 10 min | 1 min |
| 查監控 | 10-15 min | 2-3 min |
| 查 Log | 20-30 min | 5 min |
| 分析根因 | 30-60 min | 5-10 min |
| 建 Ticket | 30 min | 2 min |
| 寫報告 | 60-120 min | 5-10 min |
| 總計 | ~3-4 hr | ~25 min |
上一篇缺了「寫報告」這一行。
現在補上了。
從調查到報告,完整了。
下一篇,我們要聊一個你可能已經發現的問題:
同樣的工具,問 AI 的方式不同,結果差很多。
怎麼問對問題?怎麼讓 AI 真正理解你的維運需求?
下一篇聊 Prompt 工程。
 打雜的花園鰻
打雜的花園鰻
