可以參考改過的範例:example011.html 這個範例套用了新的修改,而且為了比較明顯看出問題,把圖形的框線加回去。另外,用方向鍵就可以跳到上一張下一張投影片,比較方便。
先看一下昨天的第一頁:
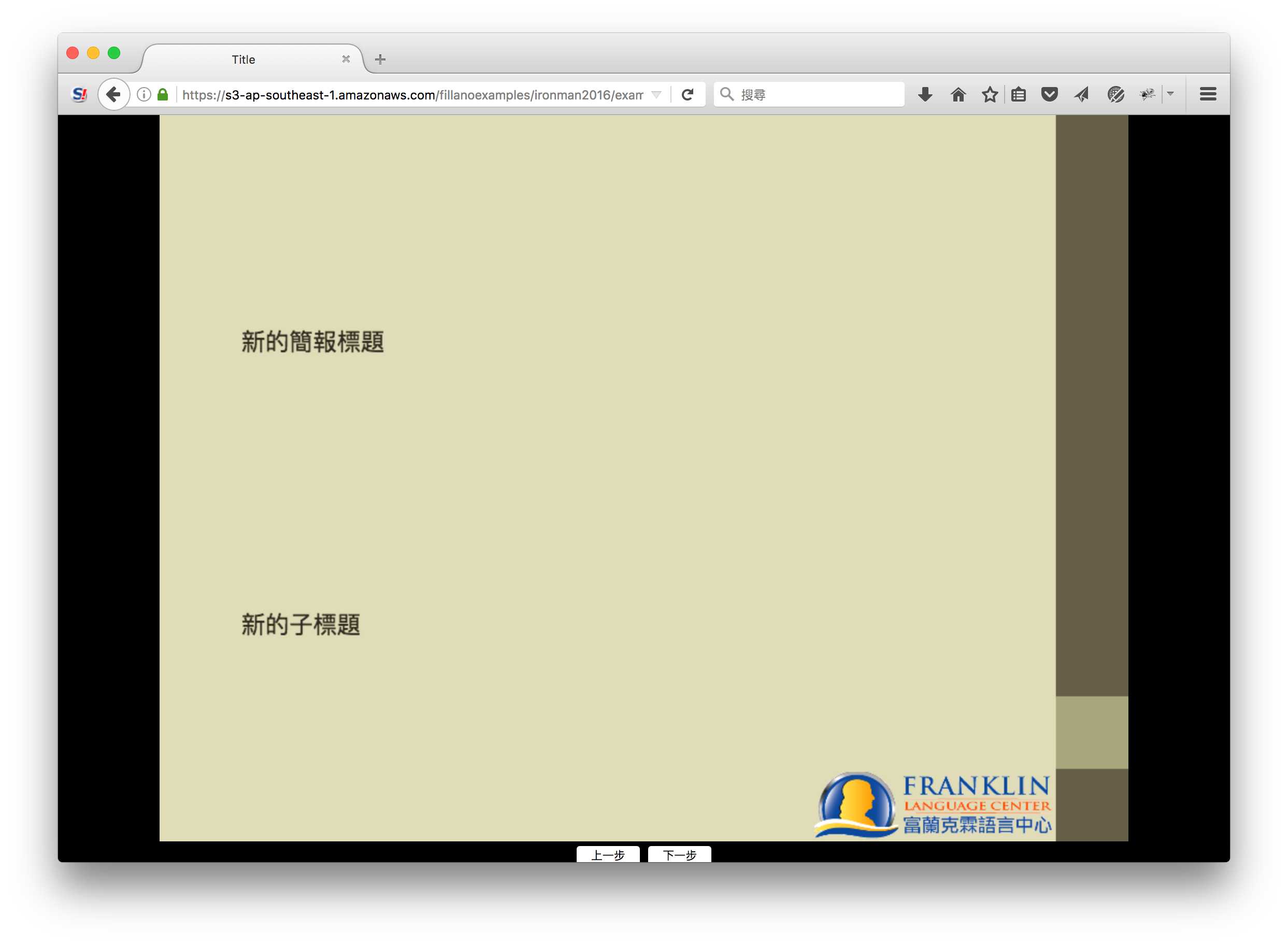
文字大小的問題,主要是因為剖析的問題,導致字型大小被設為「預設」樣式的字型大小設定,就是18point。
目前程式裡面有一個明顯錯誤:
function slideMasterParser(obj, entry, relations, defTextStyle, theme) {
let ret = {};
obj.$$
.filter(z => z['#name'] === 'p:clrMap')
.forEach(a => {
ret.colorMap = a.$;
});
obj.$$
.filter(z => z['#name'] === 'p:txStyles')
.forEach(a => {
ret.txStyles = {};
a.$$.forEach(b => {
switch(b['#name']) {
case 'p:titleStyle':
ret.txStyles.titleStyle = textParagraphPropertiesParser(defTextStyle, b, theme.colorScheme, ret.colorMap);
break;
case 'p:bodyStyle':
ret.txStyles.bodyStyle = textParagraphPropertiesParser(defTextStyle, b, theme.colorScheme, ret.colorMap);
break;
case 'p:otherStyle':
ret.txStyles.otherStyle = textParagraphPropertiesParser(defTextStyle, b, theme.colorScheme, ret.colorMap);
break
}
});
})
obj.$$.forEach(a => {
switch(a['#name']) {
case 'p:sldLayoutIdLst':
ret.slideLayoutIdList = a.$$.reduce((pre, cur) => {
let rid = cur.$['r:id'];
let target = relations[rid];
pre.push({id: cur.$.id, rid: rid, target: target});
return pre;
}, []);
break;
case 'p:cSld':
ret.commonSlideData = masterSlideDataParser(a, ret.txStyles, relations, theme.colorScheme, ret.colorMap);
break;
}
});
return ret;
}
這裡處理的應該是文字列表樣式,而不是段落屬性,不應該呼叫textParagraphPropertiesParser()...所以改一改程式,呼叫listStyleParser()就好了。
改過以後看起來正常一點:
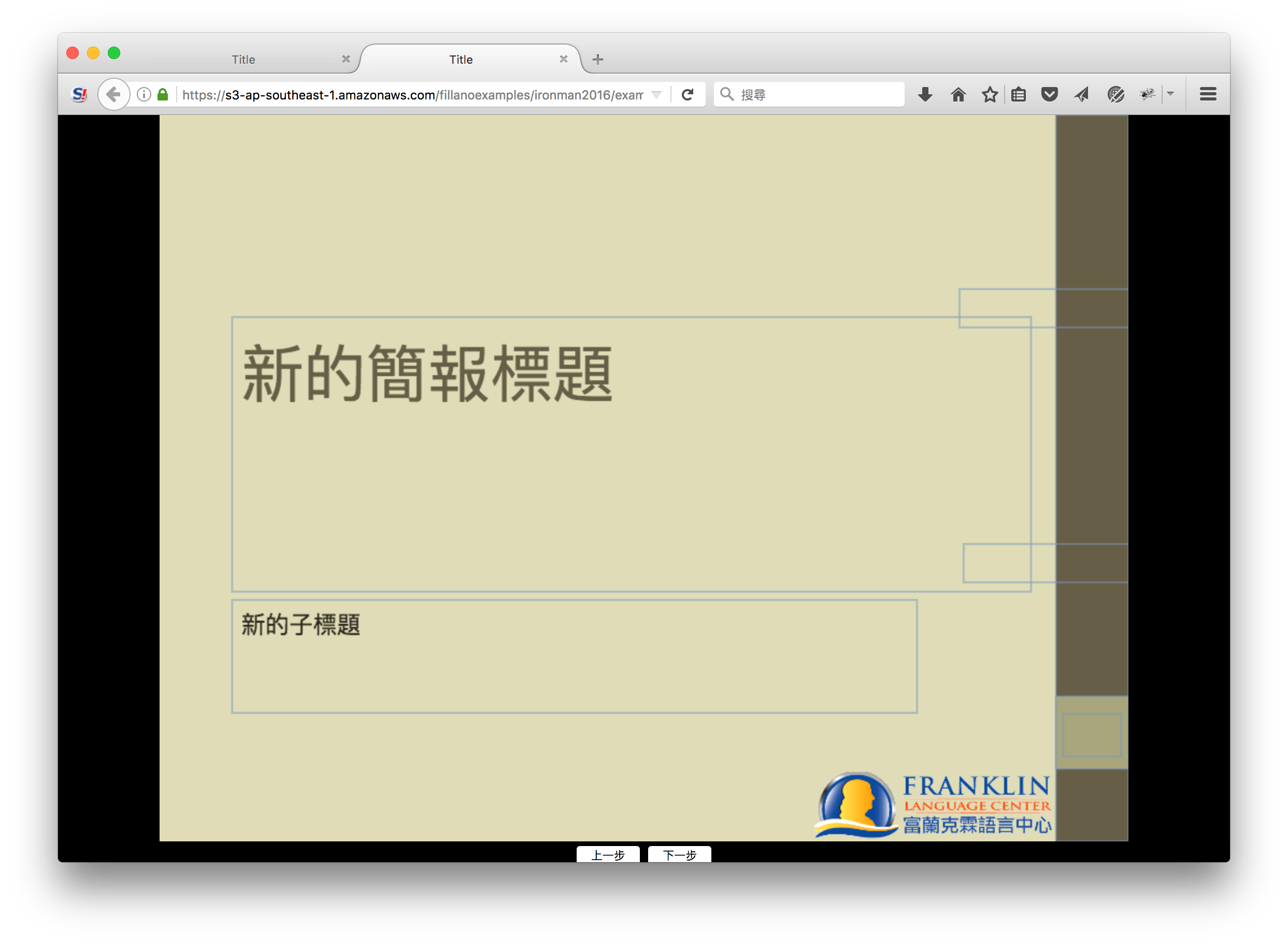
不過還是有問題,目前字型大小是slideMaster1.xml中定義的titleStyle的46 point,正確的大小應該是slideLayout1.xml中定義的66 point。
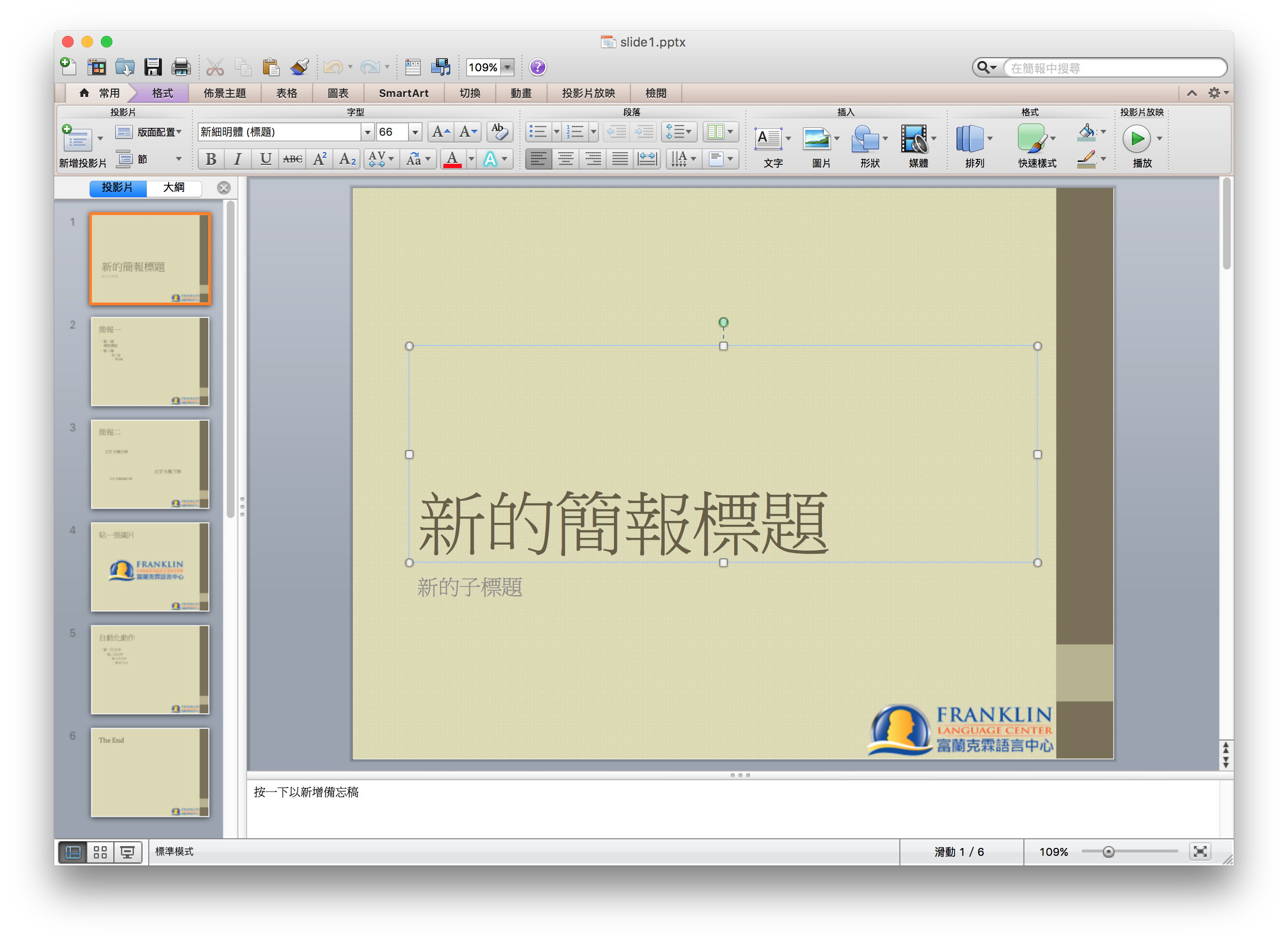
這個問題,就先擱著,後面繼續改XD
從pointpoint的畫面對照其實也可以看得出來,就是正確的標題,應該要對齊圖形的下方。這個屬性是txBody底下的bodyPr中的anchor設定:
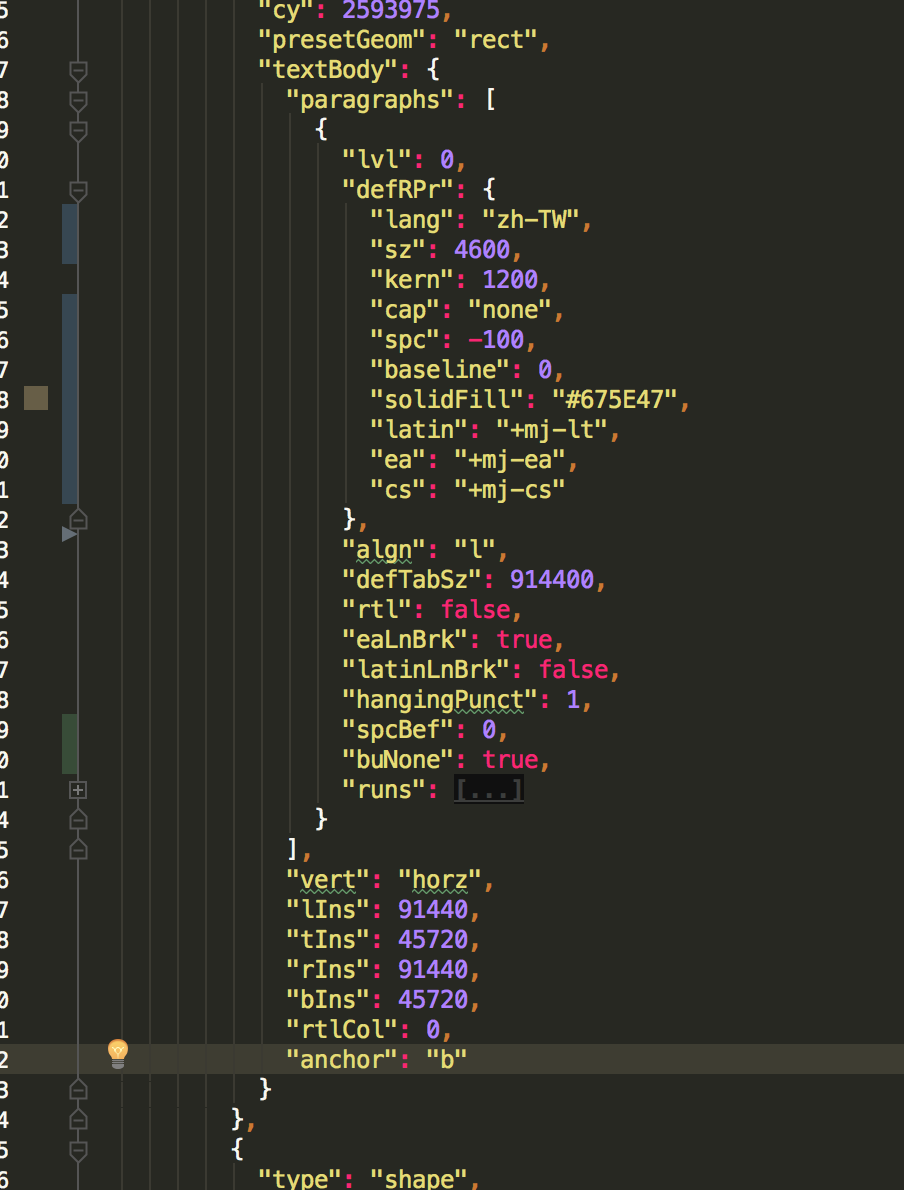
'b'代表對齊下方。子標題也有anchor屬性,內容是't',代表對齊圖形上方。
不過要調整這個稍微複雜,因為繪製文字的邏輯要更有彈性...放到之後再改吧
我原先假設投影片與母片、版面配置的圖形,是透過圖形的id屬性來做匹配,但是看了例子,很明顯不是這樣:
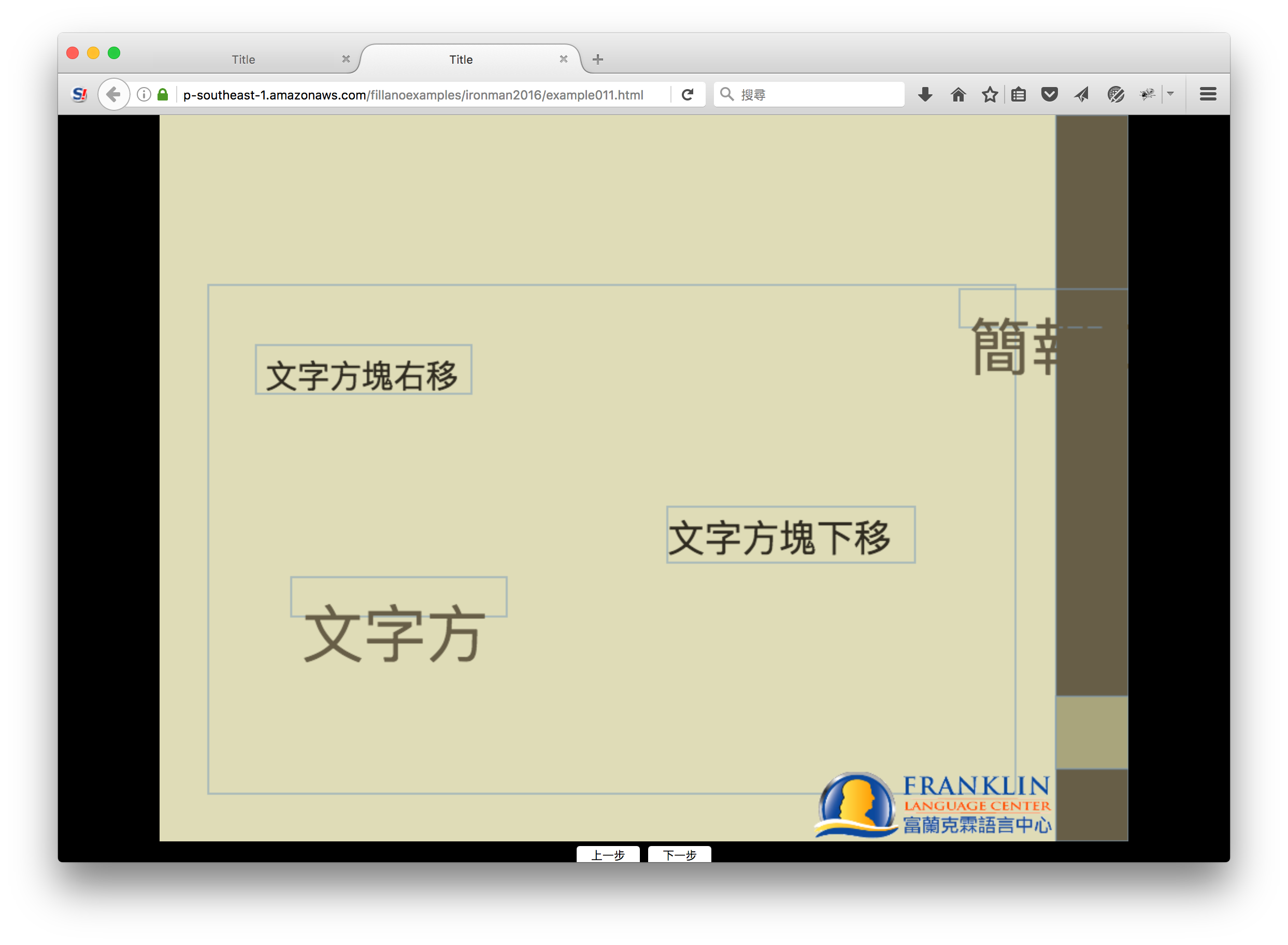
這張投影片的「標題」,被放到母片中「日期」欄位使用的圖形位置去了。另外一張也類似:
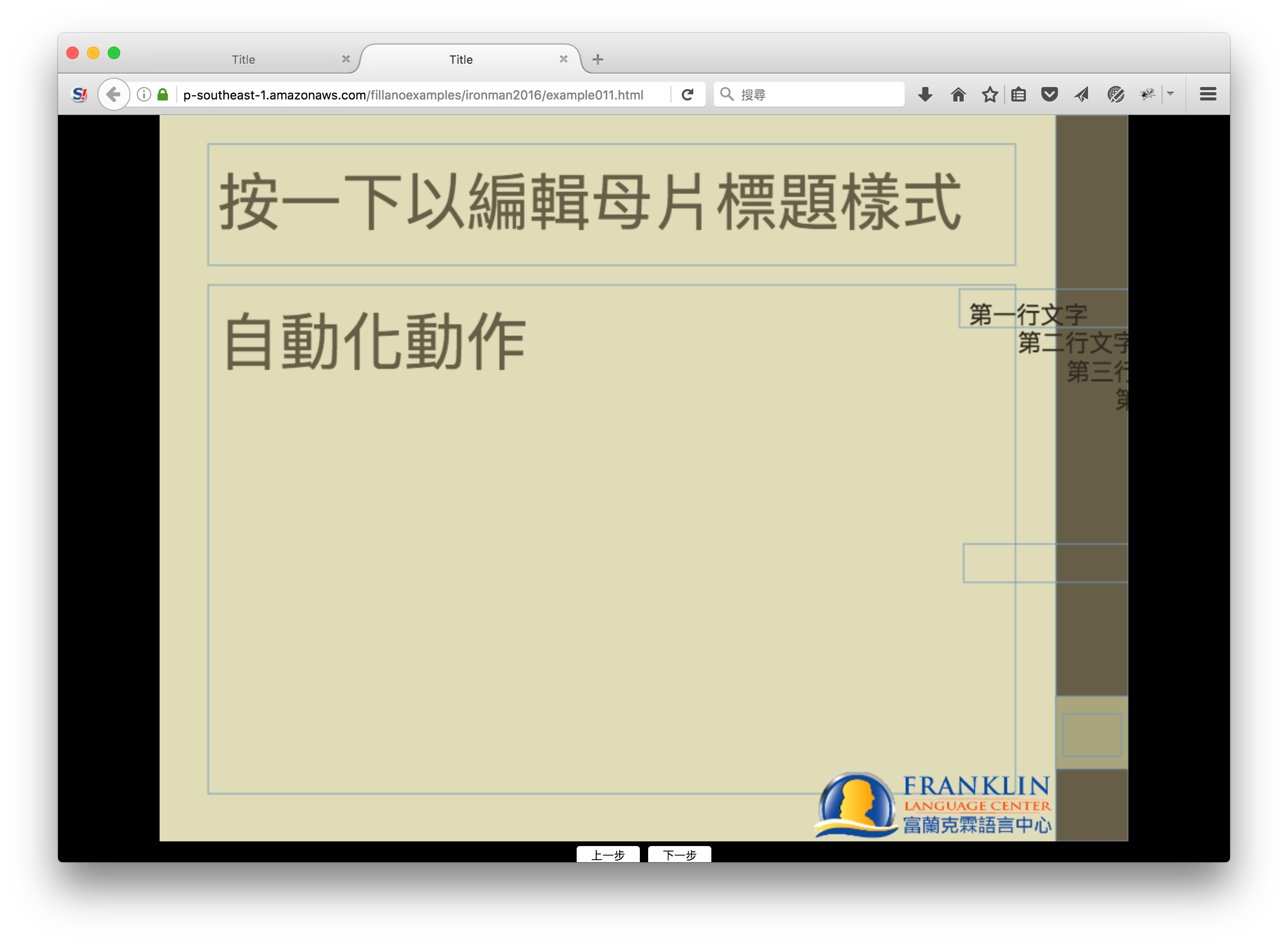
除了內容文字被擺到日期欄位,還把版面配置的圖形跟他的文字複製上去了。本來應該是要匹配這個,然後把文字覆蓋過去的...
找了一下資料,發現這個網站有一些office openxml中使用place holders的說明,還蠻清楚的:PresentationML Slides - Overview
關鍵在於,母片、版面配置以及投影片,不是靠圖形的id屬性匹配的,而是圖形的p:nvPr(非可視屬性)中的p:ph(place holder)中的type及idx。
之後會需要調整剖析的程式:
大概還需要做這些調整...調整過再檢查一下資料是否更正確的被抓出來。


