Hadoop有三種安裝模式:
其中獨立模式(Standalone)與偽分佈模式(Pseudo-Distributed)只需要一台host即可,多機安裝模式(Fully-Distributed)則需要多個host來達到分散(Distributed)的效果,接下來這篇文章會介紹這三種安裝方法。
基本上Hadoop預設的模式就是Standalone,只要完成事前準備步驟1-5即可使用。Standalone僅供測試與體驗用途,若要執行大量運算或是儲存大量資料有可能就會撐不住啦。
讓我們來測試一下Standalone是否可以正常運作。
hadoop version
#回傳結果:
Hadoop 2.8.2
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 66c47f2a01ad9637879e95f80c41f798373828fb
Compiled by jdu on 2017-10-19T20:39Z
Compiled with protoc 2.5.0
From source with checksum dce55e5afe30c210816b39b631a53b1d
This command was run using /home/stana/hadoop-2.8.2/share/hadoop/common/hadoop-common-2.8.2.jar
cd ~
mkdir input
cp $HADOOP_HOME/etc/hadoop/*.xml input
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.2.jar grep input output 'dfs[a-z.]+'
透過上面的指令,會把$HADOOP_HOME/etc/hadoop/*.xml路徑下所有.xml的檔案複製到~/input內,並使用hadoop-mapreduce-examples-2.8.2.jar執行MapReduce Job,會把~/input內所有檔案有關 dfs 開頭的字串撈出來。
#觀察執行結果:
cat output/*
可以看到符合條件的字串內容:
1 dfsadmin
Standalone的File System會直接使用本機的檔案系統,而非分散式的HDFS,這一點要特別注意。
如果已經做好事前準備,完成解壓縮Hadoop tar檔案,接著就可以開始進行偽分佈安教步驟。
sudo vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
加入JAVA_HOME設定,{path of your jdk7}為本機JAVA_HOME路徑:
# set to the root of your Java installation
export JAVA_HOME={path of your jdk7}
sudo vi $HADOOP_HOME/etc/hadoop/core-site.xml
file://):
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
sudo vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
sudo vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
sudo vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
sudo ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
sudo cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
sudo chmod 0600 ~/.ssh/authorized_keys
hdfs namenode -format
cd $HADOOP_HOME/sbin
./start-dfs.sh
http://localhost:50070連線至Web UI,畫面如下: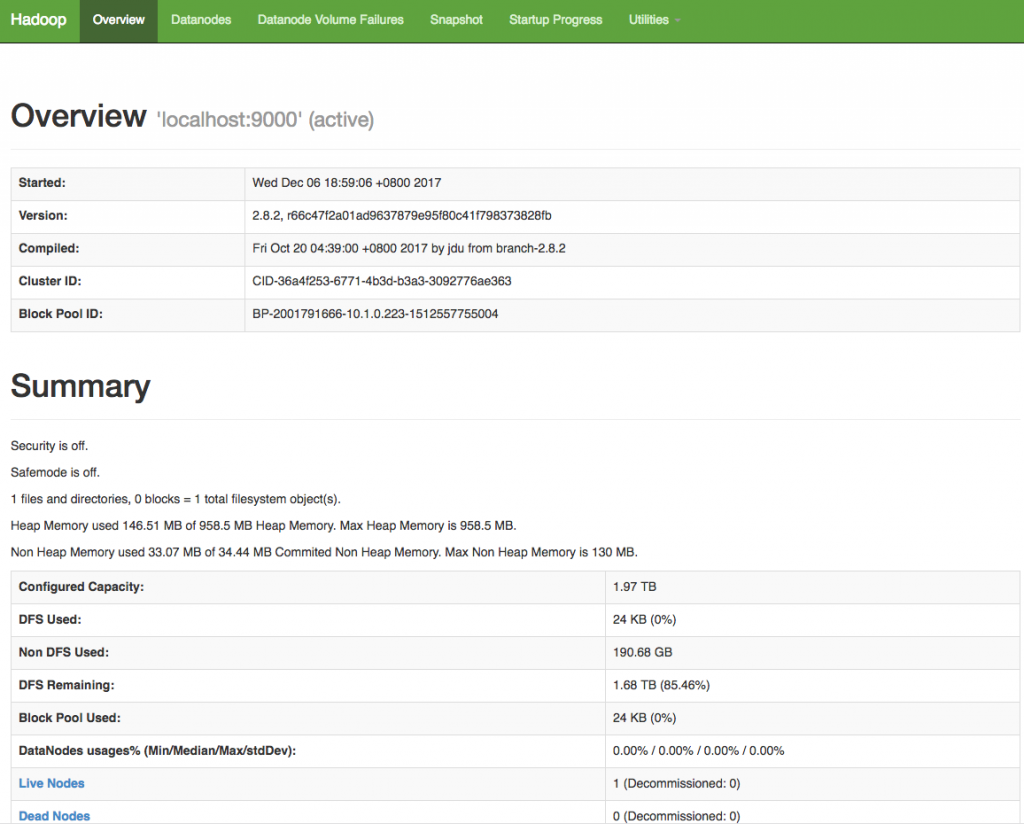
cd $HADOOP_HOME/sbin
./start-yarn.sh
http://localhost:8088連線至Web UI,畫面如下: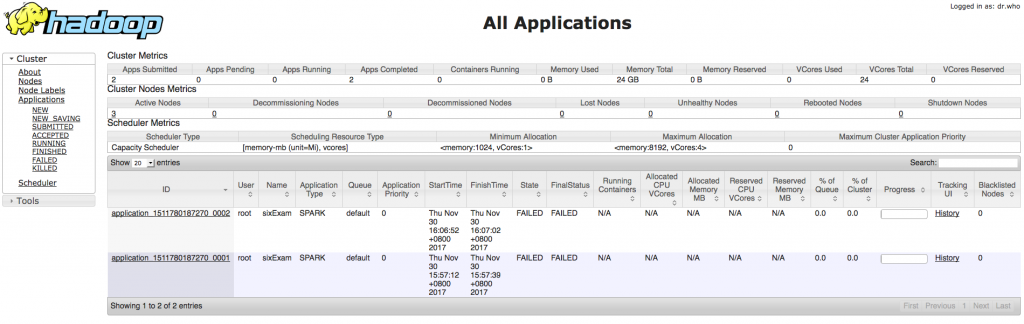
cd $HADOOP_HOME/sbin
./stop-dfs.sh
cd $HADOOP_HOME/sbin
./stop-yarn.sh
基本上與偽分佈模式 (Pseudo-Distributed)的安裝方法幾乎一模ㄧ樣,只需要多設定幾個檔案即可。強烈建議要啟動hadoop service的所有機器一定要設定免密碼ssh,否則輸入密碼就非常頭大!
下列的步驟需要在每一台hadoop cluster的機器上設定:
sudo vi $HADOOP_HOME/etc/hadoop/core-site.xml
{hostname}修改為主機名稱,指定本機為HDFS的路徑(在偽分佈為:hdfs://localhost:9000):
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://{hostname}:9000</value>
</property>
</configuration>
sudo vi $HADOOP_HOME/etc/hadoop/slaves
server-a1
server-a2
server-a3
/etc/hosts或是架設DNS,將hadoop cluster內所有機器的hostname與ip加入此檔案。設定完畢後,多機安裝模式 (Fully-Distributed)啟動與停止的指令都與偽分佈模式 (Pseudo-Distributed)相同。啟動成功後,你就已經有一個真正的分散式儲存與運算的平台了!
下一篇要來介紹Hadoop平台上的指令!
hi 大大: 我照day4 步驟做 偽分佈模式出現以下錯誤:
alex@alex-VirtualBox:/opt/hadoop/sbin$ ./start-dfs.sh
Starting namenodes on [localhost]
localhost: Load key "/home/alex/.ssh/id_rsa": Permission denied
localhost: alex@localhost: Permission denied (publickey,password).
Starting datanodes
localhost: Load key "/home/alex/.ssh/id_rsa": Permission denied
localhost: alex@localhost: Permission denied (publickey,password).
Starting secondary namenodes [alex-VirtualBox]
alex-VirtualBox: Load key "/home/alex/.ssh/id_rsa": Permission denied
alex-VirtualBox: alex@alex-virtualbox: Permission denied (publickey,password).
請問 可能是什麼問題嗎?
麻煩您指導! 謝謝!
Hi,
由錯誤訊息 alex-VirtualBox: Load key "/home/alex/.ssh/id_rsa": Permission denied 看起來像是權限問題, 看您的指令是使用alex這個使用者啟動hdfs, 有可能是alex這個使用者沒有權限可以讀取 /home/alex/.ssh/id_rsa 這個檔案, 檢查一下權限.

作者超佛心!! 純推~


