前面有介紹Hive的安裝方式,想必大家也了解並且知道怎麼使用Hive SQL來對HDFS進行查詢。
Hive可以是作為一個Client工具,而且同時只能讓一個使用者進行操作,如果要讓多個使用者同時使用呢?那就多安裝幾台嗎?
但是Hive Client無法讓應用程式透過JDBC的方式,接受應用程式的request。那這種應用場景該如何在Hive上面使用呢?
Hive 提供了一種service讓使用者可以透過JDBC driver,接收應用程式發出的SQL語法請求(request)並且回傳對HDFS查詢後的結果給應用程式,這個service就稱之為HiveServer。
HiveServer是基於Apache Thrift專案所建置出來的一個服務,所以也稱之為Thrift server,支援多種語言透過JDBC呼叫使用,包含:C++、Java、Node與Ruby。
後來為了解決HiveServer 無法處理多個使用者同時查詢的問題(即使修改原始碼也無法解決),進而發展出了新一代的HiveServer,同樣是以Thrift server為基礎所建置出來的服務。
為了避免造成混亂,原有的HiveServer就被稱為HiveServer1或是Thrift server,而新一代的HiveServer就稱之為HiveServer2。
HiverServer2於 hive 0.11.0版本推出,並且建議使用者使用。而在 hive 1.0.0版本,則正式移除HiveServer1。
若使用者剛開始使用Hive,強烈建議開始使用HiveServer2,除了可讓多人同時使用外,也會有社群的持續支援維護原始碼,還可以透過HiveServer2才有的Web UI來監控狀態。
接下來要介紹如何設定並啟動HiveServer2,假設已經下載並設定好HIVE_HOME與PATH等環境變數。
如果只想快速體驗HiveServer2,不用額外的設定即可透過下列指令啟動:
hive --service hiveserver2
或是透過-H、--help來查看可用的指令
hive --service hiveserver2 -H
Starting HiveServer2
usage: hiveserver2
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hiveconf 常用的設定有:
hive.server2.thrift.min.worker.threads: 最低可連線的數量,預設是5個連線數。
hive.server2.thrift.max.worker.threads: 最多可連線的數量,預設500個連線數。
hive.server2.thrift.port : HiveServer2所使用的TCP port號碼,預設是10000.
hive.server2.thrift.bind.host : HiveServer2所使用的TCP host name,預設是localhost
上列設定黨除了在啟動HiveServer2時直接使用,也可以寫入hive-site.xml檔案內。
可以查看Apache Hive官網文件查看更多的參數說明。
如果需要使用HiveServer2的Web UI,需要將下列的設定加入hive-site.xml,或是啟動時加在 --hiveconf 指令內:
成功啟動後,可以在瀏覽器網址列輸入:http://{hive.server2.webui.host}:{hive.server2.webui.port}後,即可看到下列的畫面:
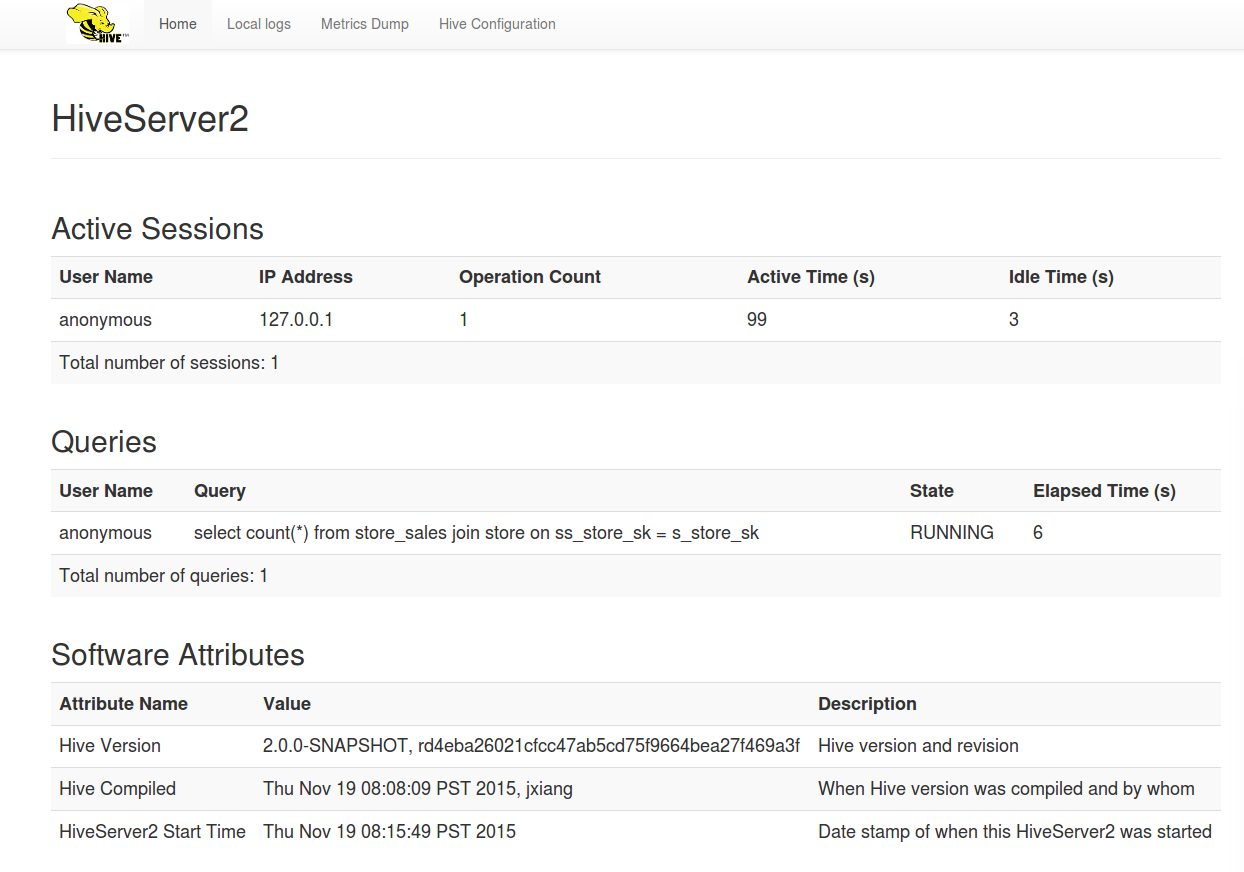
看完了Hive Server的介紹後,應該對Hive Server有更近一步的了解。接下來要來看Apache Hive如何透過當紅炸子雞- Apache Spark執行Hive SQL。


