囉唆一下:前方有爬蟲干擾,離題注意,煩瑣注意,還要記得先用pip安裝一下bs4,並建議讀者們可以同時比對圖片引導與最下面的爬蟲code,這樣應該會看的比較懂XD
yield完美展現了人類的劣根性,平時懶惰不做事,必須要有人催促才會吐出一點成果出來,一群yield就更是如此了,你必須扮演最上層的老闆,老闆催促經理,經理催促主管,主管催促員工,就像是一個管線一樣,但通常人在急迫的時間壓力中會展現出異常的高效率,這種管線結構大幅精簡了某些功能多餘的時間與記憶體,以下我將要解說的第四個優點:data processing pipline,會實作兩個功能相同的爬蟲程式,一個是用暴力堆疊for迴圈的對照組,一個是有效運用yield的實驗組,讓各位讀者比較看看,人類劣根性帶來的莫大好處(?
但既然講到爬蟲,就要先介紹一下常用的python爬蟲庫來充一下字數了XD,今天實作爬蟲會用到的兩個library一個是requests,一個是BeautifulSoup,requests負責作為發送request和接收resopnse的接口,而BeautifulSoup的角色是用來解析網頁原始碼的標籤元素,在這裡我就稍微講解一下等等會用到的函數功能好了:
res = request.get():
這個function負責傳送GET method的request,在參數設置中,第一個參數為url,另外還有常用一個具名參數params接受一個dict對象,作為在GET method中傳遞數據的一個媒介。
而其回傳值為一個resopnse物件,這個物件代表的是從遠端server傳回來的response,若這個GET method用意是要造訪一個網頁,則這個網頁的html原始碼會存在res.text裏面。
soup = BeautifulSoup(res.text,'lxml')
這是BeautifulSoup的一個初始化方法,其傳入的第一個參數為目標網頁的原始碼,最後的回傳值soup為一個解析原始碼後所得到的soup對象,我們可以從這個對象的一些屬性或方法取得網頁元素的內容,第二個參數設定的是BeautifulSoup使用的parser。
soup.select()
得到了一個soup對象後,我們可以對其select方法傳入我們想要得到的元素的特徵字串,比如說我想得到這個網頁裡所有元素,那我就要傳入"a",如果我想要拿到所有id='example'的網頁元素,那就要傳入"#example",若是class='example',那就要傳入".example"。
這個方法會回傳一個由網頁元素對象構成的list,當然這些網頁元素對象也有一些屬性和方法可以獲取更為細節的特性。
我們這次要爬的網站是一個中文小說網http://big5.quanben5.com/ ,目標是把所有小說內容都爬下來,在做這個網站爬蟲之前呢,我們要先觀察的是要如何從入口網站逐步深入到每個小說的章節並把他抓下來,但今天的目標就先到小說的章節頁面好了。
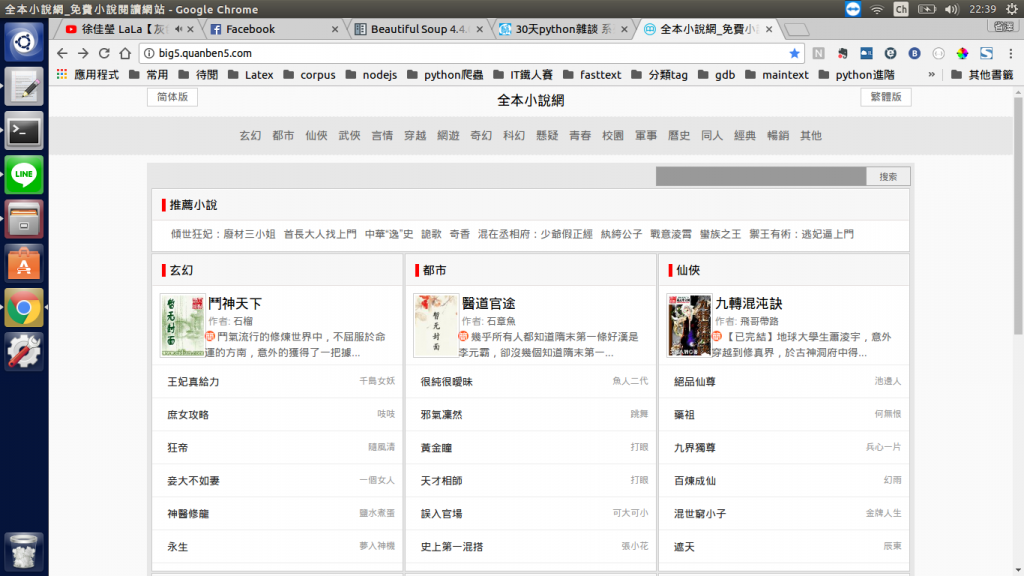
這是小說網站的首頁,首先爬蟲最重要的行為就是'爬',而爬蟲要從一個網頁爬到另一個網頁就是點選連結,那我們第一個課題就是要想點選什麼連結才能爬盡所有角落,在這首頁我看到的可行方案就是網頁上面那行:"玄幻 都市 仙俠 武俠..."等等的類別標籤,一個小說一定有一個類別,那麼這些連結一定可以帶領爬蟲爬進各個隱密的角落,爬起來爬起來,全部都給我爬起來!
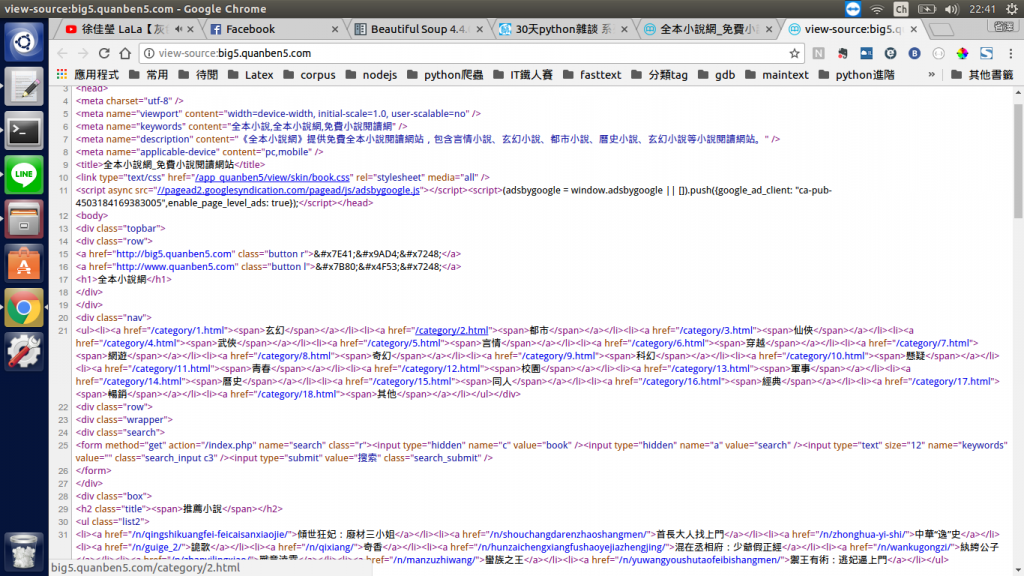
看看首頁的原始碼,我們要如何點進這些類別連結呢?發現<div class="nav">裏面的所有<a>標籤都對應著一個類別連結,其對應的路徑分別是"/category/1.html","/category/2.html",....,"/category/18.html",太棒了,只要做一個range(1,19),依序將各個路徑加進url的結尾,就能模擬點進每個類別的動作了。
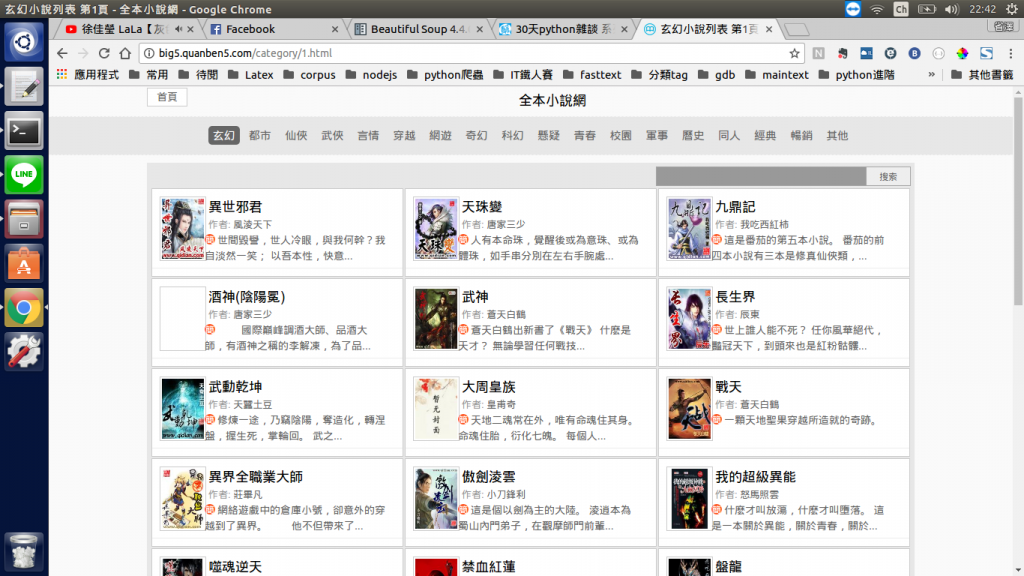
假設我們先點進玄幻類別的連結,接下來就是要把所有小說一個一個掏光光,那我要如何點擊一個小說連結呢?
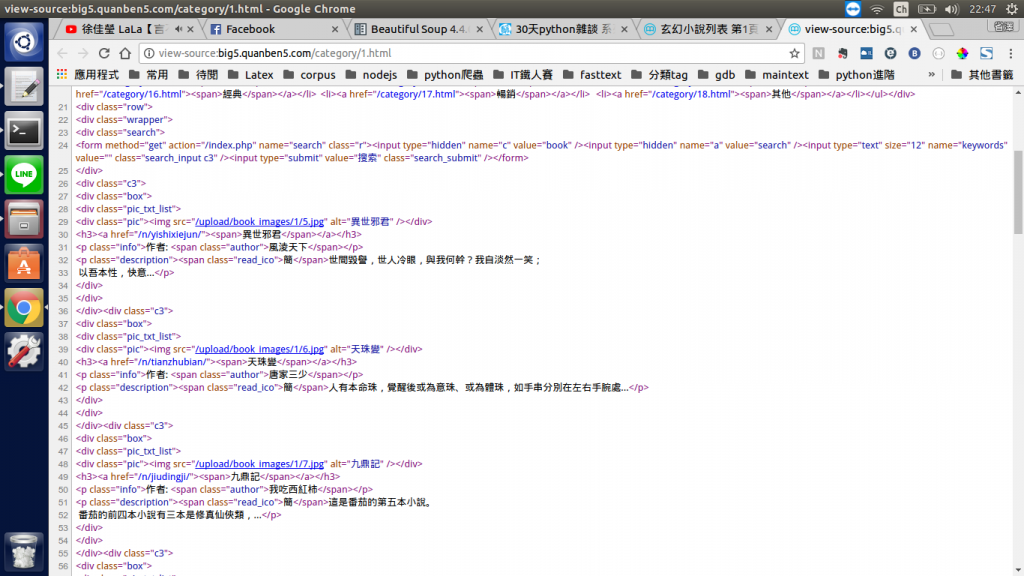
看見了嗎,我們把玄幻類別裡的第一本小說'異世邪君'的標題找到了,而他正好就是一個<a>標籤,是進入小說的一個傳送點!但當然不是所有/標籤都是傳送點,觀察整個原始碼後,發現傳送點外面都裹著<div class="pic_txt_list">的外衣,現在我們已經可以掌握進入每個小說的路徑了。
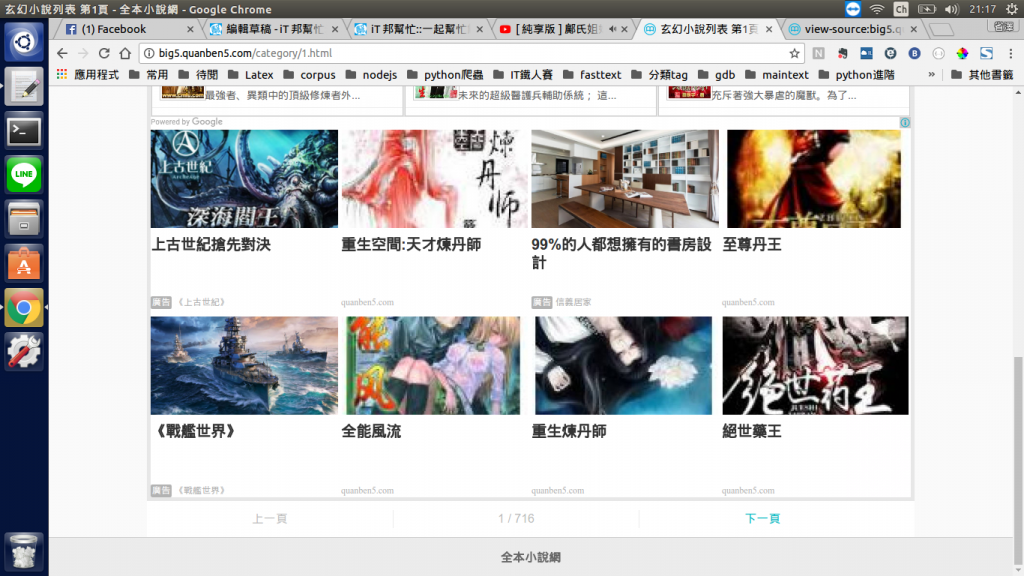
掌握了進入小說的方法,我們還要留意,並不是所有玄幻小說都擠在一個網頁裡,所以滑到最下面,會有一個顯示頁數的神祕石板(位於原始碼的<span class="cur_page">裡),上面寫著"1/716",得知了所有玄幻小說在列表中共有716頁,那要如何切換頁數呢?
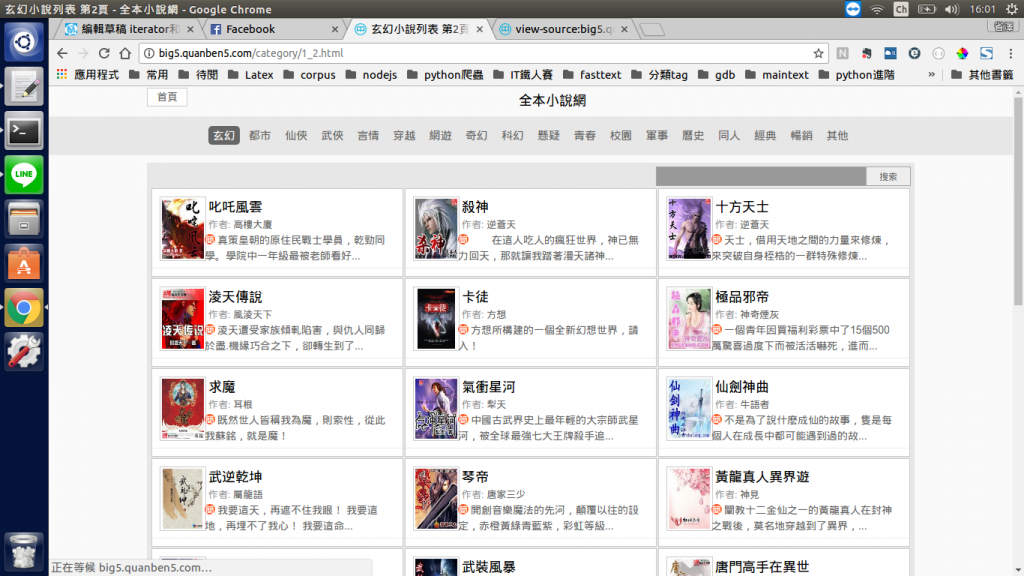
這個簡單,先點擊這個網頁的下一頁,然後看看url結尾是不是"1_2.html"呢,這表示這麼頁面顯示的是類別一(玄幻)第二頁的內容,因此我們只要在程式中寫一個range(1,717),逐次更換網頁的結尾就能換頁。
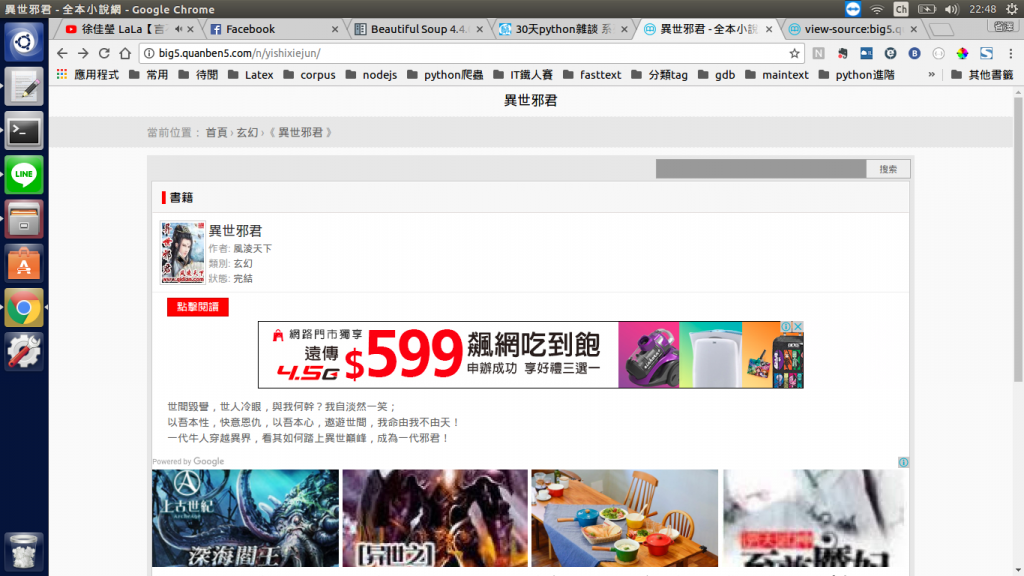
這是進入小說'異世邪君'後顯示的頁面,在我們得到章節頁面前,還需讓我們的蟲蟲按下點擊閱讀的按鈕。
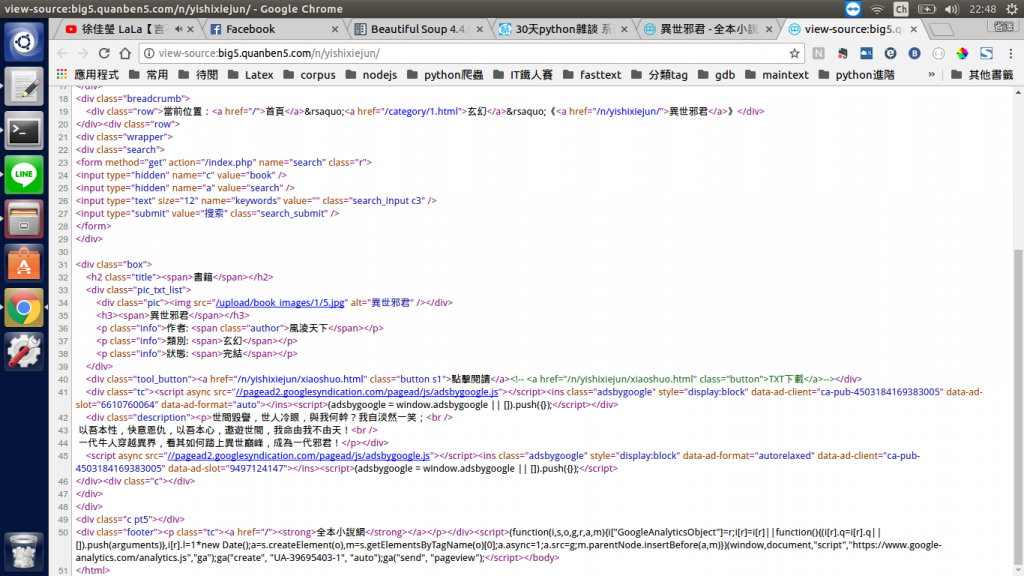
點擊閱讀的按鈕位於原始碼的/裏面。但仔細觀察這個按鈕所引導的連結,只不過把當下的網頁的url加進一個"xiaoshuo.html"作為結尾罷了,引此我們不用真的模擬點進去的動作,只要再進入傳送點時,後面再加上"xiaoshuo.html"就可以繞過這個中介頁面了。
太棒了,進入章節頁面了,灑花花灑花花!
接下來就是最重要的爬蟲實現:
crawler.py:
import requests
from bs4 import BeautifulSoup
import re
import os
main_url = 'http://big5.quanben5.com/'
cat_url = 'category/'
for cat_num in range(1,19): # 點進每個類別連結的for迴圈
url = main_url + cat_url + str(cat_num) + '.html'
res = requests.get(url) # 取得其中一個類別頁面的html code
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
all_page_num = soup.select('.cur_page')[0].string # 取得顯示頁數的神祕石板(ex.'1 / 716')
all_page_num = int(all_page_num.split('/')[1]) # 取得總頁數(ex.'1 / 716' -> '716')
for page in range(1,all_page_num+1): # 點進其中一個類別後,點進每個頁數的for迴圈
url = main_url + cat_url + str(cat) + '_' + str(page) + '.html'
res = requests.get(url) # 取得取得其中一個頁數的html code
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
for title in soup.select('.pic_txt_list'): # 尋找小說傳送點的外衣
res = requests.get(main_url + str(title.select('a')[0]['href']) + 'xiaoshuo.html') # 結尾加上"xiaoshuo.html"繞過小說傳送點到章節頁面之間的中間頁面
res.encoding = 'utf-8'
print(res.text)
input("已顯示章節目錄,按下Enter以繼續")
目前這個程式可以顯示這個網站裡所有小說的章節目錄,大家可以試著跑跑看。


