昨天帶領蟲蟲進入了章節頁面,今天真的要給他爬好爬滿了,把每本小說的文字爬下來並各存在一個檔案裡,再來繼續我們的爬蟲之旅吧~
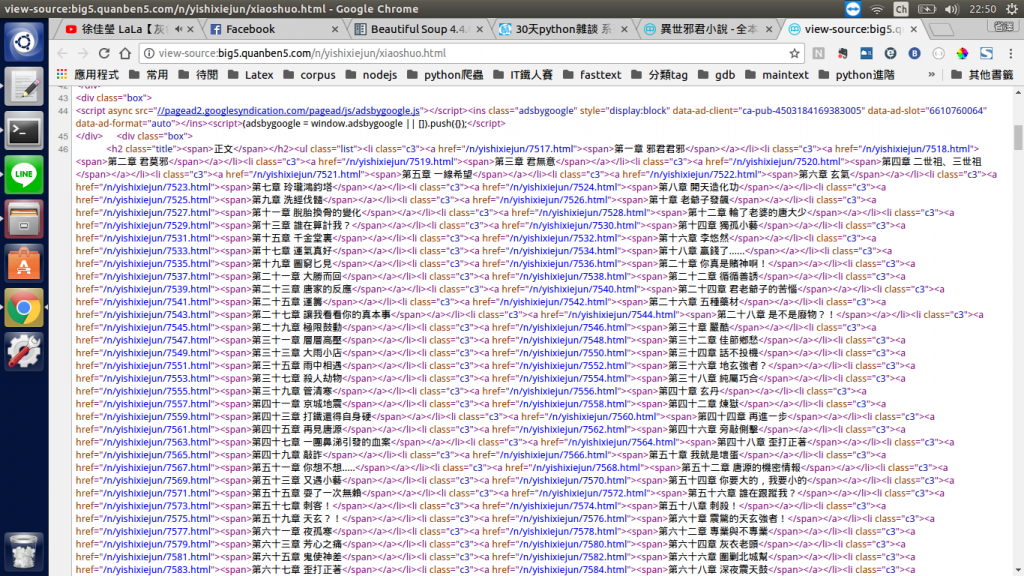
所有章節的連結都位於<li class="c3">的<a>標籤裏面,終於要得到我們想要的小說內容了。
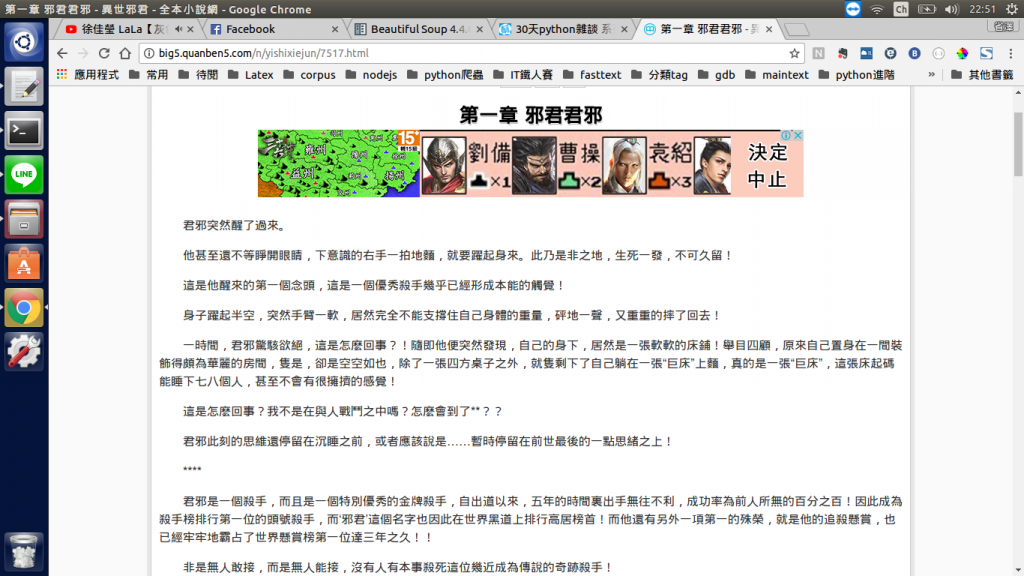
內容頁面get!
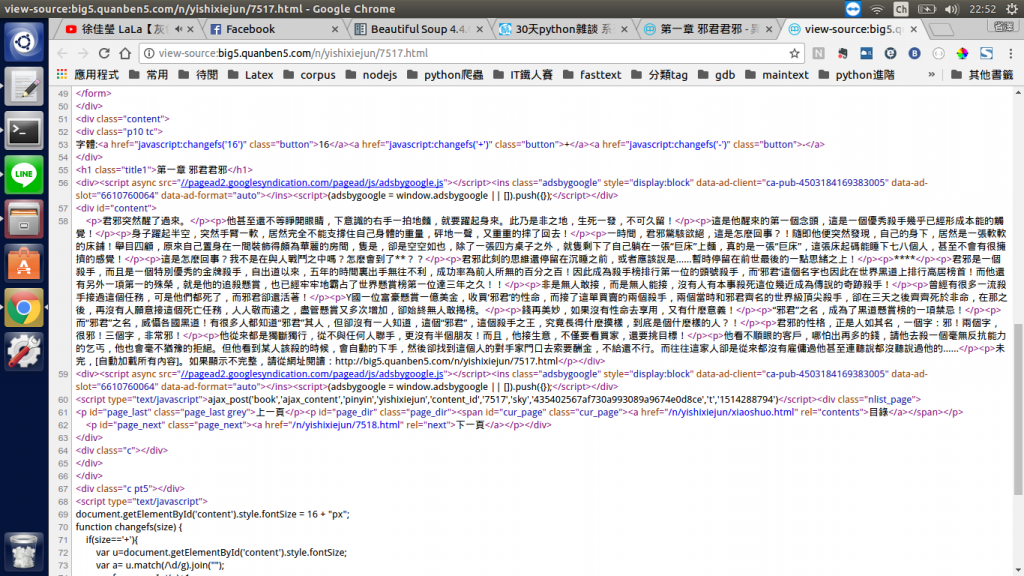
擷取<div id="content">裏面的<p>標籤文字後,就剩下儲存的議題了。
import requests
from bs4 import BeautifulSoup
import re
import os
main_url = 'http://big5.quanben5.com/'
cat_url = 'category/'
for cat_id in range(1,19): # 點進每個類別連結的for迴圈
url = main_url + cat_url + str(cat_id) + '.html'
res = requests.get(url) # 取得其中一個類別頁面的html code
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
all_page_num = soup.select('.cur_page')[0].string # 取得顯示頁數的神祕石板(ex.'1 / 716')
all_page_num = int(all_page_num.split('/')[1]) # 取得總頁數(ex.'1 / 716' -> '716')
for page_id in range(1,all_page_num+1): # 點進其中一個類別後,點進每個頁數的for迴圈
url = main_url + cat_url + str(cat_id) + '_' + str(page_id) + '.html'
res = requests.get(url) # 取得取得其中一個頁數的html code
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
for title in soup.select('.pic_txt_list'): # 尋找小說傳送點的外衣
res = requests.get(main_url + str(title.select('a')[0]['href']) + 'xiaoshuo.html') # 結尾加上"xiaoshuo.html"繞過小說傳送點到章節頁面之間的中間頁面
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
for chapter in soup.select('li.c3'): # 取得所有章節連結
chap_index = chapter.select('a')[0]['href']
res = requests.get(main_url + chap_index) # 進入內容頁面
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
for content in soup.select('div#content > p'): # 取得<div id='content'>的<p>的內容
print(content.string)
input('以顯示小說內容,請按Enter以繼續')
以上的code可以顯示每一本小說每一章節的內容。
加入儲存功能後的code:
crawler.py:
import requests
from bs4 import BeautifulSoup
import re
import os
from os.path import isdir
main_url = 'http://big5.quanben5.com/'
cat_url = 'category/'
dir_name = 'quanben5-trad/'
if not isdir(dir_name):
os.mkdir(dir_name) # 確保quanben5-trad/這個資料夾在當前目錄中
for cat_id in range(1,19): # 點進每個類別連結的for迴圈
url = main_url + cat_url + str(cat_id) + '.html'
res = requests.get(url) # 取得其中一個類別頁面的html code
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
all_page_num = soup.select('.cur_page')[0].string # 取得顯示頁數的神祕石板(ex.'1 / 716')
all_page_num = int(all_page_num.split('/')[1]) # 取得總頁數(ex.'1 / 716' -> '716')
for page_id in range(1,all_page_num+1): # 點進其中一個類別後,點進每個頁數的for迴圈
url = main_url + cat_url + str(cat_id) + '_' + str(page_id) + '.html'
res = requests.get(url) # 取得取得其中一個頁數的html code
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
for title in soup.select('.pic_txt_list'): # 尋找小說傳送點的外衣
res = requests.get(main_url + str(title.select('a')[0]['href']) + 'xiaoshuo.html') # 結尾加上"xiaoshuo.html"繞過小說傳送點到章節頁面之間的中間頁面
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
novel_name = 'quanben5-trad/' + soup.select("h1")[0].string
novel_file = open(novel_name,'wt') # 以小說名來命名一個檔案
for chapter in soup.select('li.c3'): # 取得所有章節連結
chap_index = chapter.select('a')[0]['href']
res = requests.get(main_url + chap_index) # 進入內容頁面
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
for content in soup.select('div#content > p'): # 取得<div id='content'>的<p>的內容
novel_file.write(content.string+'\n')
novel_file.close()
input(novel_name+'內容已抓完,請按Enter以繼續')
code看起來落落長很難懂?我也覺得很難懂XD(很可能是我自己寫太差了),如果只想知道這code的重點的讀者們,只需留意一件事,這個小說網站就像是個龐大的樹狀圖,這顆樹的結構大概是醬:入口網站->類別頁面->頁數頁面->小說章節目錄->章節內容,有5層,而蟲蟲若是往深處多爬一層,就要多加一層for迴圈,所以泥看看,這code的確是5層for迴圈呢!
而yield的好處呢,就是把這些code攤平化,把每一層for迴圈都轉成一個generator function,每一個generator都是資料管線的其中一個部份,只要這些generator都把自己的output傳給下一層generator的input就行了,這真是太神奇了,我們來看看到底這個code怎麼寫吧!
crawler2.py:
import requests
from bs4 import BeautifulSoup
import re
import os
from os.path import isdir
def in_entry(main_url,cat_url): # 進入入口網站採取的行為
for cat_id in range(1,19):
cat_url = main_url + cat_url + str(cat_id) + '.html'
# print(cat_url)
# input()
yield cat_url
def in_cat(cat_url_gen): # 進入類別頁面所採取的行為
for cat_url in cat_url_gen:
res = requests.get(cat_url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
all_page_num = soup.select('.cur_page')[0].string
all_page_num = int(all_page_num.split('/')[1])
for page_id in range(1,all_page_num+1):
page_url = cat_url.rstrip('.html') + '_' + str(page_id) + '.html'
# print(page_url)
# input()
yield page_url
def in_page(page_url_gen,main_url): # 進入頁數頁面所採取的行為
for page_url in page_url_gen:
res = requests.get(page_url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
for title in soup.select('.pic_txt_list'):
chpList_url = main_url + str(title.select('a')[0]['href']) + 'xiaoshuo.html'
# print(chpList_url)
# input()
yield chpList_url
def in_chpList(chpList_url_gen,dir_name,main_url): # 進入小說章節目錄所採取的行為
for chpList_url in chpList_url_gen:
res = requests.get(chpList_url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
novel_name = soup.select("h1")[0].string
novel_file = open(dir_name+novel_name,'wt')
for chapter in soup.select('li.c3'):
chap_index = chapter.select('a')[0]['href']
content_url = main_url + chap_index
# print(content_url, novel_file)
# input()
yield content_url, novel_file
novel_file.close()
input(novel_name+'內容已抓完,請按Enter以繼續')
def in_content(content_url_gen): # 進入其中一個章節的內容頁面所採取的行為
for content_url, novel_file in content_url_gen:
res = requests.get(content_url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
for content in soup.select('div#content > p'):
# print(content.string, novel_file)
# input()
novel_file.write(content.string+'\n')
yield content.string
main_url = 'http://big5.quanben5.com/'
cat_url = 'category/'
dir_name = 'quanben5-trad/'
if not isdir(dir_name):
os.mkdir(dir_name)
cat_url_generator = in_entry(main_url,cat_url)
page_url_generator = in_cat(cat_url_generator)
chpList_url_generator = in_page(page_url_generator,main_url)
content_url_generator = in_chpList(chpList_url_generator,dir_name,main_url)
content_generator = in_content(content_url_generator)
for content in content_generator:
pass
以上就是能夠達成相同功能的generator實現方式了,什麼?code看起來好像沒有變短的樣子,我沒有說過他會變短阿哈哈,但可讀性絕對是變高了,撇除掉函式定義的部份,真正的功能執行也就只有最下面的幾行程式:
cat_url_generator = in_entry(main_url,cat_url)
page_url_generator = in_cat(cat_url_generator)
chpList_url_generator = in_page(page_url_generator,main_url)
content_url_generator = in_chpList(chpList_url_generator,dir_name,main_url)
content_generator = in_content(content_url_generator)
for content in content_generator:
pass
來試著解讀一下這個code的意思,首先資料管線分成了5個部份:
第1部份,也就是in_entry指的是當我得到入口網站的url(也就是參數中的main_url),我要做什麼事,就爬蟲的邏輯進入了入口網站,接下來就是要尋找類別頁面的url,找出了url之後就傳給管線的下一部份,也可以說in_entry他要做的就是產生第2部份所需要的cat_url,所以cat_url_generator = in_entry(main_url,cat_url)這不只是把in_entry的回傳值指定給cat_url_generator而已,從文字上來理解,這個指令也是在為in_entry取一個更好的名字,就是cat_url_generator,因為他確實是cat_url的產生器。
第2部份的in_cat(cat_url_generator),意思就是我接收了cat_url_generator作為參數,那我就可以像他索求一些我所需要的cat_url來做事,而得到了cat_url相當於我可以進入類別頁面的連結,那我要做什麼事呢,就是產生頁數頁面的url,所以才將他回傳給page_url_generator,也是在為in_cat取一個更好的名字:page_url_generator。
其餘部份也是類似邏輯,當然在管線的輸送過程中可能也需要在途中多添加一些東西,比如說in_page,因為實務上的需要再把main_url傳進去會顯的比較方便,所以參數會多了一個main_url。
最後的for迴圈是什麼意思呢?因為前面的指令只是說我把管線接起來而已,記得前幾天說過,generator是很懶惰的,必須要用__next__去催他他才會做事,所以這個for迴圈只是要叫content_generator做事而已,然後content_generator會去催他上一部份的管線content_url_generator做事,然後這樣依序催促上一個管線,最後全部的管線都動起來了,仔細領悟一下這段code吧,我覺得這真是太美了。
優點值得一提再提,資料管線的好處就是你可以明確知道管線的哪一部份需要做什麼動作,他需要輸入什麼,需要輸出什麼都可以獨立的在函數中修改,不像for迴圈堆疊一樣要更改還要尋找是在哪一層迴圈裡,非常容易維護,重點是他可以分離,比如說你只是想知道網站中有什麼章節目錄頁面,就只要用for迴圈來對chpList_url_generator做迭代就行了,後面的兩個部份可以直接拆掉。


