北市內科地區,上下班時間的塞車問題,是台北市一大交通的困擾.並也屢屢成為政治炒作與選舉的熱門議題.
使用大眾運輸系統,是多方提出的方案之一.
但是否可藉由數據的搜集與整理,可觀察得知目前相關公車路線在尖峰時間的瓶頸,藉此更了解方案的可行性.
專案主題:交通與觀光
區域:臺北市內湖區(可適用台北市與新北市)
使用的資料集:臺北市公車路線圖
本專案發想自2017年新竹黑客松活動簡介,進行專案實作.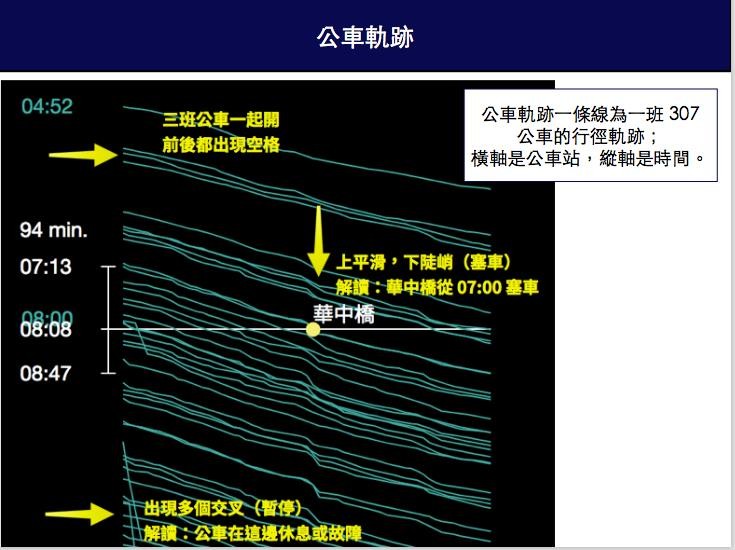
以下開始實做
#本專案使用的套件
library(ggplot2) #繪圖用
library(jsonlite) #處理資料用
library(lubridate) #處理時間格式用
欲達成上圖的圖表結果,先試做一下所需的資料表範本.
#資料應該要有公車/站牌/記錄時間,小作幾筆資料測試先
bus<-c("X","X","X","X","X","X","Y","Y","Y","Y","Y","Y")
busstop<-c("A","A","B","C","D","E","A","A","B","C","D","E")
time<-c("2018/1/5 08:58","2018/1/5 08:59","2018/1/5 09:01","2018/1/5 09:02","2018/1/5 09:05","2018/1/5 09:15","2018/1/5 08:40","2018/1/5 08:55","2018/1/5 09:02","2018/1/5 09:03","2018/1/5 09:05","2018/1/5 09:15")
df1<-data.frame(bus,busstop,time)
# 畫圖囉!X軸定義為站牌 Y軸定義為到站時間 線圖為公車
my.plot1 <- ggplot(df1, aes(busstop,time, group = bus)) +
geom_line(aes(colour = bus), linetype = 2)
my.plot1
df1格式如下: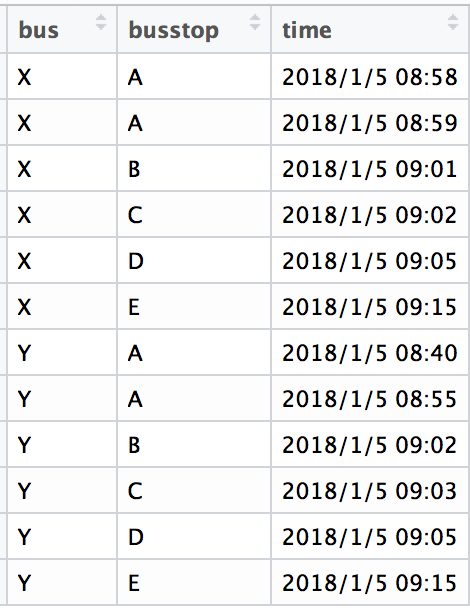
嗯!這個範本小有模樣!可開始下個步驟囉
(公車X與公車Y各自有線圖 Y軸部分 時間是自下而上的遞增)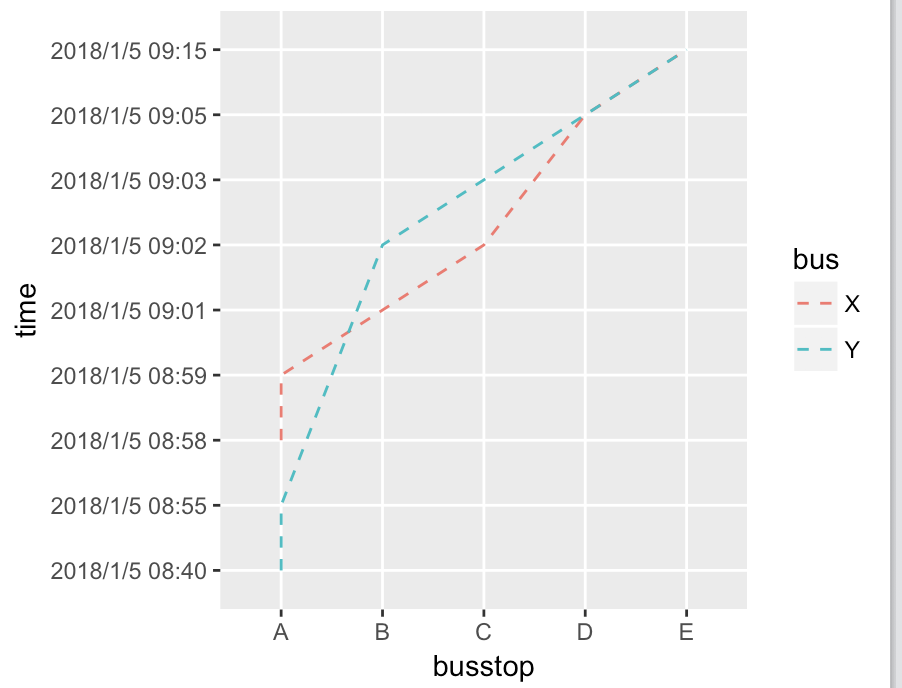
經查公車相關的公開資料,彙整在公車動態資訊(總索引),觀察結果,所需內容分別為:
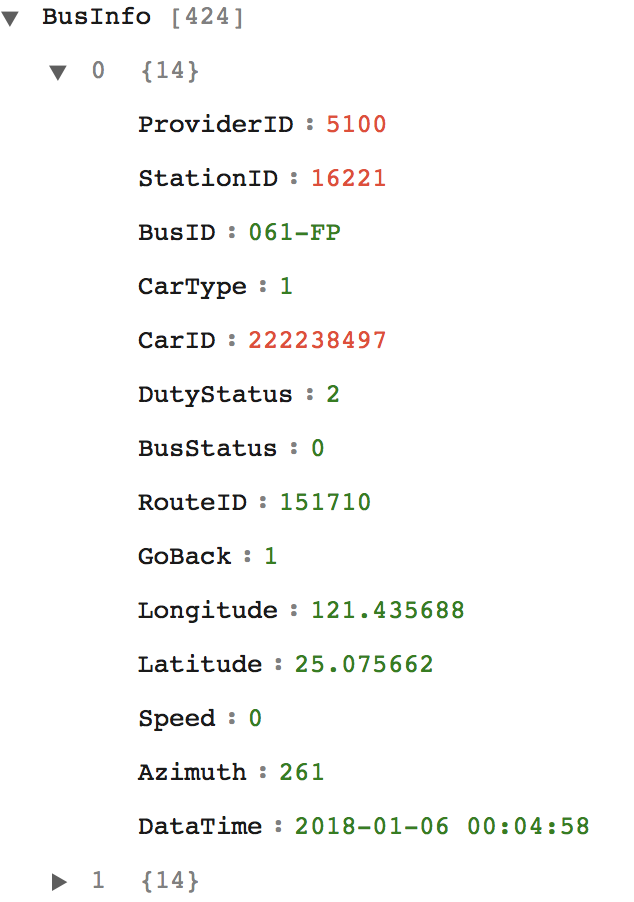
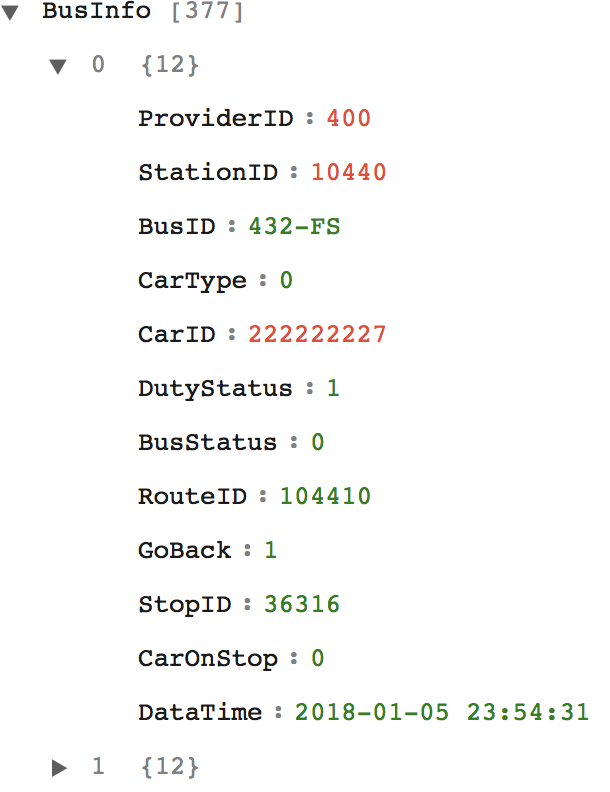
由於該車機資料,是透過服務觸發後,並無歷史資料可以大量取得.
僅能靠定時的觸發服務,並自行搜集整理而得.
這部分要注意的是專案目的在觀察帶狀性的時間下,公車在各站牌之間移動的動態,僅有一兩個無關係的資料檔,數據過少是無法說明本次專題目的的!
##lubridate套件所提供的好用日期格式套用Stamp功能,省去轉檔.
sf<-stamp("20171231235959")
sf(Sys.time()) #可以測試一下或使用sf(now())
#
for (i in 1:3) {
#給定車機資料提供url
url<-"https://tcgbusfs.blob.core.windows.net/blobbus/GetBusEvent.gz"
#每次所產生的檔名,用觸發時間時分秒來當作檔名,以茲識別.如需指定路徑,請自行調整
gfile<-paste0(sf(now()),".gz")
#開始下載url對應的資料,並存為gfile,下載方式為binary(wb)
download.file(url,gfile, mode = "wb")
#直接套用jsonlite 套件,讀出對應的資料(透過gzfile直接讀取檔名為gfile的.gz)
dlist<-fromJSON(gzfile(gfile))
#直接取用該list第二層名為BusInfo的list,放入名為data的dataframe
data<-data.frame(dlist[["BusInfo"]])
#資料的append累積
if (i==1){
df<-data
}else{
df <- rbind(df, data)
}
#設定為每分鐘抓一份資料
Sys.sleep(60)
}#迴圈結束
前述的程式,開啟後預計將執行三個60秒的時間,並將資料累計起來.
這部分應該可改由Batch資料先將壓縮檔下載至固定目錄,之後再行以迴圈的方式讀完所有資料.
可以準備畫圖了!
#向307致敬: 因全台北公車多,資料龐大,僅篩選以一條路線代表
df307<-filter(df,df$RouteID=="108640")
#沿用先前發想的圖 套用資料
my.plotA <- ggplot(df307, aes(StopID,DataTime, group = BusID)) +
geom_line(aes(colour = BusID), linetype = 2)
my.plotA
可以看見三分鐘左右的同一路線,多台公車在不同站牌的狀況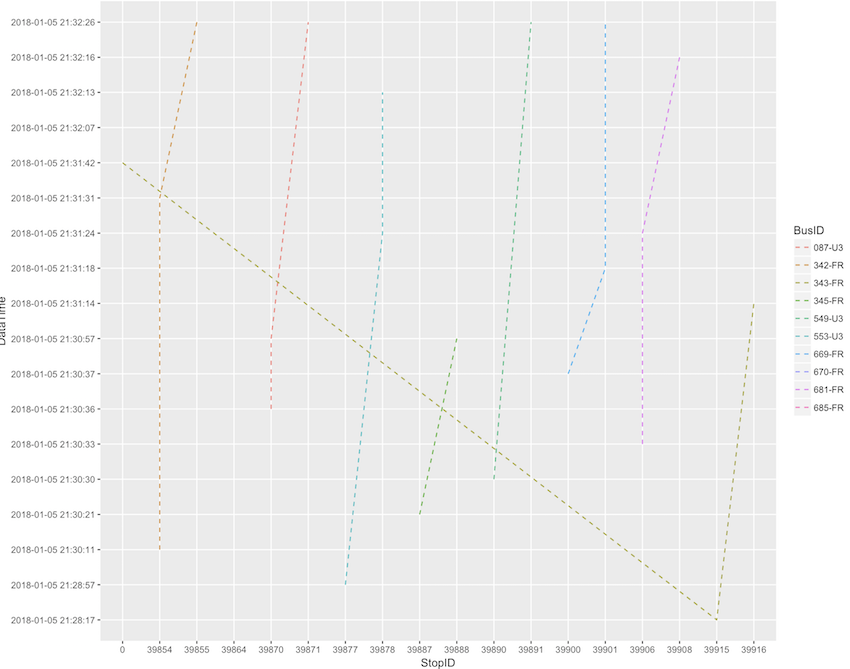
df307看一下資料內容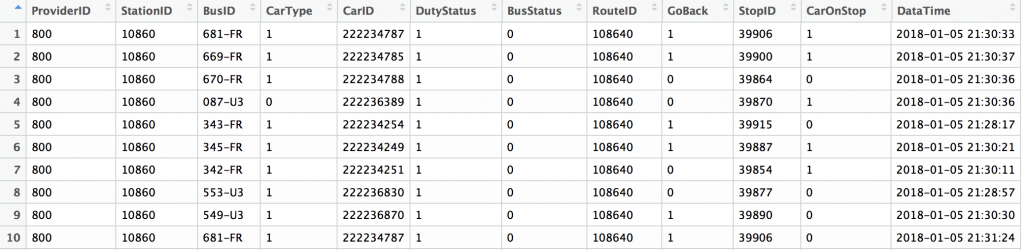



 iThome鐵人賽
iThome鐵人賽