嗨,大家好,今天要介紹的是關於透過Python完成Spark-Streaming,基本的Spark概念和MQTT這邊可能不會多做解釋,就當作大家已經有基本的RDD與MQTT概念囉。
關於Discretized Streams, A Quick Example, Transformations on DStreams的部分,基本上都是從官方的文件翻譯過來的,需要看細節都可以從Spark Document找到:
Spark Streaming 是Spark API的一個擴充能夠即時資料串流處理,從不同來源取得資料後利用不同RDD函式轉換資料格式或計算,最後將資料儲存到資料庫等地方,方便後續做機器學習演算法等等,如下圖:

Spark Streaming和spark不同的是,它提供了一種高級的抽象類別Discretized Stream或稱Dstream,它代表一個連續的資料串流。DStream能夠藉由不同來源取得輸入的資料。DStream的內部是由序列的RDD組成。
什麼是DStreams?是由Spark Streaming提供的基本抽象類別,表現了一個連續的資料串流,它能夠透過transform從接收來源輸入資料或處理產生的資料串流。一個DStream表示一個一系列連續的RDDs,RDD是Spark中不可變的抽象類別,分散式數據庫。
在DStream中每個RDD中間有一定的間隔,每個RDD內包含了資料,如圖: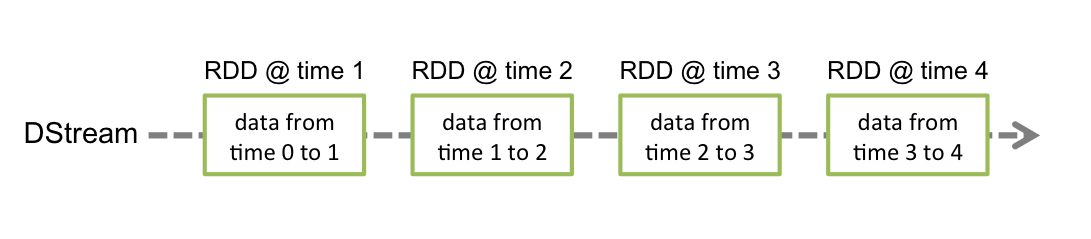
在DStream上應用的任何操作(translates)都會轉換為在基礎RDD的操作,例如WordCount將串流每一行的字轉換的例子中,將flatMap的操作應用於DStream行中的每個RDD,以生成字串的DStream,如圖: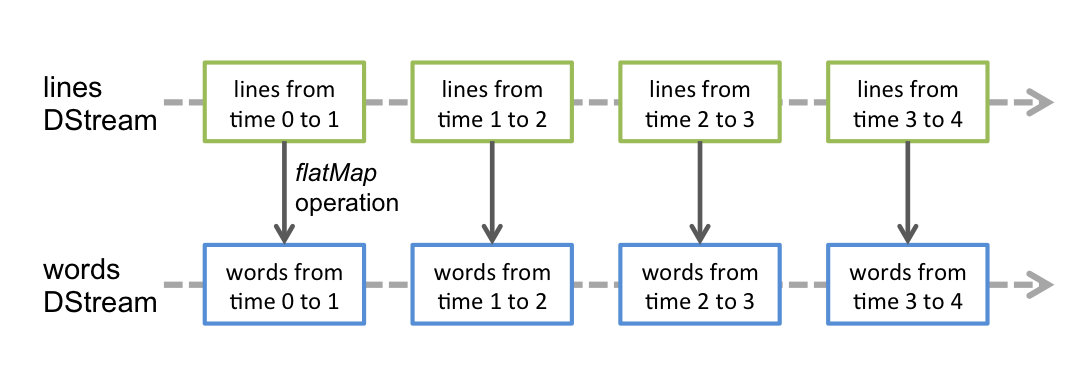
這些基礎RDD transformations由Spark engine計算,DStream操作隱藏了大部分的細節,並為開發人員提供了更高級的API以方便使用。
在進入如何編寫Spark Streaming程式的細節前,我們來看一個簡單的例子,程式從監聽TCP Socket的資料伺服器取得文字資料,計算文字包含的單字數:
StreamingContext,這是所有Streaming功能的進入點。from pyspark import SparkContext
from pyspark.streaming import StreamingContext
(local)的批次處理間隔為1秒(以秒為單位分割資料串)的StreamingContext。sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 1)
StreamingContext,能夠創建一個DStream,它代表從TCP來源(主機位址localhost,port為9999)取得的資料。lines = ssc.socketTextStream("localhost", 9999)
lines變數是一個DStream,表示即將獲得的資料串流。這個DStream的每條紀錄都代表一行文字,並利用split來將資料做切割變成單字。flatMap是一個一對多的DStream操作,把DStream的每條紀錄都生成多個新紀錄來創建成新的DStream。在這個例子中,每行文字都被切分成了多個單字,我們把切割出的單字串流用words這個DStream表示。words = lines.flatMap(lambda line: line.split(" "))
words這個DStream被一對一轉換操作成了一個新的DStream,由(word,1)對(pair)組成。接著,就可以用這個新的DStream計算每批次資料的單字頻率。最後,用wordCounts.print()印出每秒計算的單字頻率。pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
wordCounts.pprint()
Spark Streaming只是準備它要執行的計算,實際上並沒有真正的執行,要真正的計算必須要調用Action函數。ssc.start()
ssc.awaitTermination()
nc -lk 9999
./bin/spark-submit examples/src/main/python/streaming/network_wordcount.py localhost 9999
和RDDs很類似,transformations允許資料從輸入DStream被修改。DStream支援很多可用的建立在一般Spark RDD的transformations,可以到Spark官方文件Transformations on DStreams查看細節。
終於要介紹Spark如何訂閱接收MQTT broker發佈的資料,這裡會主要著重Spark程式碼的講解,而不是MQTT介紹,就當作你已經有了MQTT的概念了。
當然,如果需要稍微暸解MQTT概念以及安裝broker的話,可以看我之前的文章有提到:Flask上使用 MQTT!
和前面的介紹一樣,我們需要引入些需要用到的函式庫(包含SparkContext,mqtt等等):
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from mqtt import MQTTUtils
sys用來接收系統的參數,下面程式碼中,我們判斷是否接收剛好三個參數分別為pyspark.py, <broker url>, <MQTT Topic>
if len(sys.argv) != 3:
print >> sys.stderr, "Usage: pyspark.py <broker url> <topic>"
exit(-1)
brokerUrl ='tcp://'+sys.argv[1]
topic = sys.argv[2]
SparkContext前面介紹過的功能這裡就不多作介紹了。sc = SparkContext(appName="PythonStreamingMQTT")
ssc = StreamingContext(sc, 1)
lines為MQTT接收到資料後創建的RDD,參數包含StreamingContext, brokerUrl, Mqtt topic。lines = MQTTUtils.createStream(ssc, brokerUrl, topic)
mqtt_get_str = lines.map(lambda word:'get world from topic'+topic+" : "+word)
mqtt_get_str.pprint()
ssc.start()
ssc.awaitTermination()
spark-submit PythonStreamingMQTT.py localhost:1883 mytopic
mosquitto_pub -t mytopic -m hello_spark -h localhost
hello_spark。當然你可以一直發佈訊息,Spark將會一直接收。
謝謝大家的觀看,還是Spark新手,有誤的話請大家不吝嗇給予指教!
 plusone
plusone
