最近在研究如何利用爬蟲下載檔案,有次在爬一個 Big5 編碼的網站時,發生一件令我困惑的事。
該網站的回傳 Header 大致如下,使用 Chrome 瀏覽器。
Cache-Control: private
Content-Disposition: attachment;filename=�������.csv
Content-Length: 13
Content-Type: application/octet-stream;charset=Big5
Date: Sun, 12 Aug 2018 18:16:08 GMT
下載回來的檔案名稱是正確的 中文測試.csv,不過 Content-Disposition 看到的亂碼 �������.csv 無法解回中文,因此我就很好奇瀏覽器是如何解碼的。
接著想到可以用 Fiddler 攔截封包,看看有什麼線索,Fiddler 的 Headers 視窗和瀏覽器看到的一樣,不過 Hexview 就不同了,檔名變成了 �������.csv。
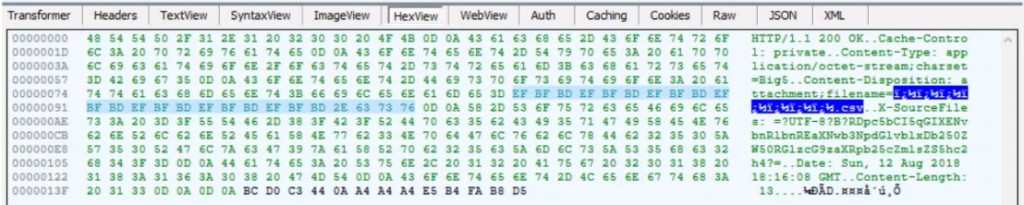
看到這個我又更困惑了,這應該是另一種編碼,不過試了好久也是解不回來。
且這時發現 Requset 經過 Fiddler 後,從瀏覽器下載回來的檔案名稱變成了亂碼 �������.csv,關掉 Fiddler 後又正常。

到這裡我已經徹底混亂了...,換用 HttpWebRequest 來看吧...,看到的是 ¤¤¤å´ú¸Õ.csv,我的老天鵝,試了三種方法,結果都不一樣...
attachment;filename=¤¤¤å´ú¸Õ.csv
不過我感覺這個比較接近答案了,只要知道 Header 是用什麼解碼的,就能還原回去,Google 後發現原來 Http Header 內容必需以 ISO-8859-1 編碼,馬上試一下,果然被我猜對了,正確解回來了。
var fileName = "¤¤¤å´ú¸Õ.csv";
//先以 ISO-8859-1 解碼回 Big5 編碼的位元組陣列
var bytes = Encoding.GetEncoding("ISO-8859-1").GetByte(fileName);
//再用 Big5 編碼取出字串
var str = Encoding.GetEncoding("Big5").GetString(bytes);
//中文測試.csv
不過還是無法解釋 Fiddler 看到的,由上面得出的結果,我猜測 HexView 看到的應該也是經過 ISO-8859-1 解碼過的文字,那就將所有編碼的結果列出來看看。
var fileName = "�������.csv";
//先以 ISO-8859-1 編碼
var bytes = Encoding.GetEncoding("ISO-8859-1").GetByte(fileName);
//測試所有編碼
var builder = new StringBuilder();
foreach(var ei in Encoding.GetEncodings())
{
builder.AppendFormat("xxx => {0} : {1} \r\n",
ei.Name, ei.GetEncoding().GetString(bytes));
}
//另存文字檔
File.WriteAllText($"{AppDomain.CurrentDomain.BaseDirectory}test.txt", builder.ToString());
在文字檔內看到了熟悉的符號 �������.csv,看到這個符號我就知道原因了,Big5 編碼的檔案名稱被 Fiddler 用 UTF-8 解碼,然後又再用 UTF-8 編碼一次,HexView 顯示時再用 ISO-8859-1 解碼,所以才會看到 �������.csv。
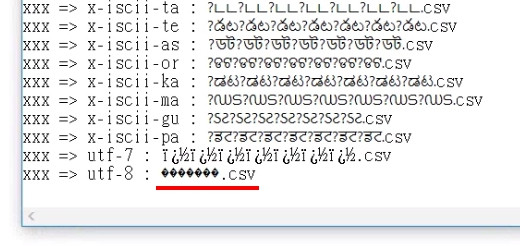
證實一下。
var fileName = "中文測試.csv";
//將檔案名稱以 Big5 編碼
var big5Bytes = Encoding.GetEncoding("Big5").GetBytes(fileName;
//將 Big5 編碼用 UTF-8 解碼
var utf8 = Encoding.GetEncoding("UTF-8").GetString(big5Bytes);
//再以 UTF-8 編碼一次
var utf8Bytes = Encoding.GetEncoding("UTF-8").GetBytes(utf8);
//以 ISO-8859-1 解碼
var str = Encoding.GetEncoding("ISO-8859-1").GetStrin(utf8Bytes);
//�������.csv
這樣就能解釋為什麼 Requset 經過 Fiddler 後,檔案名稱就會變成亂碼,因為 Fiddler 用 UTF-8 錯誤解碼,然後再編碼一次傳給 Chrome,不過這個動作只發生在 Header,Body 內容不受影響,我也不知道 Fiddler 為什麼要這樣做 ...

接著我就有個疑問,瀏覽器如何判斷 Content-Disposition 要用 Big5 解碼呢,是依據 Content-Type 嗎,因此我把 Content-Type 換成 UTF-8 看看。
Content-Type: application/octet-stream;charset=utf-8
結果還是正確的中文,所以和 Content-Type 無關,瀏覽器應該有其他的判斷方式,現在各家瀏覽器在處理 Content-Disposition 都有各自的做法,並沒有依照標準實作。
我測試了四種瀏覽器:
中文測試.csv
中文測試.csv
¤¤¤å´ú¸Õ.csv
中文測試.csv
沒想到 IE11 正確 Edge 竟然亂碼,不過這也能說明只有 Edge 遵循標準。
public class file : IHttpHandler
{
public void ProcessRequest(HttpContext context)
{
context.Response.ContentEncoding = Encoding.GetEncoding("Big5");
context.Response.HeaderEncoding = Encoding.GetEncoding("Big5");
context.Response.ContentType =
"application/octet-stream;charset=Big5";
var data = "標題\n中文測試";
context.Response.Write(data);
context.Response.AddHeader("Content-Disposition",
"attachment;filename=中文測試.csv");
}
public bool IsReusable
{
get
{
return false;
}
}
}
var request = (HttpWebRequest)HttpWebRequest.Create(
"http://localhost:1651/file.ashx");
//測試時設定 Proxy 到 Fiddler 上
//request.Proxy = new WebProxy("127.0.0.1", 8888);
var response = (HttpWebResponse)request.GetResponse();
//取得 Content-Disposition
var disposition = response.Headers["Content-Disposition"];
var fileName = disposition.Split('=')[1];
//將 filename 以 ISO-8859-1 編碼
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(fileName);
//再以 Big5 解碼
var result = Encoding.GetEncoding("Big5").GetString(bytes);
//另存檔案
using (var fs = new FileStream(
$"{AppDomain.CurrentDomain.BaseDirectory}{result}",
FileMode.Create, FileAccess.Write))
{
using (var stream = response.GetResponseStream())
{
stream.CopyTo(fs);
}
}
最後覺得被 Fiddler 害得好慘,一開始測試 HttpWebRequest 時,因為有設 Proxy 到 Fiddler 上,所以看到的結果和瀏覽器一樣,完全不知道 Fiddler 已經從中做了手腳,後來試到很晚,滿腦子都是編碼解碼超級混亂,只好放棄去睡覺,睡醒後頭腦比較清楚才找出原因,這篇雖然內容不多不過前後花了不少時間,感謝大家觀看。

正確處理下載文檔時HTTP頭的編碼問題(Content-Disposition)
下载文件设置header的filename要用ISO8859-1编码的原因
Fiddler2中文乱码问题
 小碼農米爾
小碼農米爾


