上一篇介紹到雙邊濾波的效能比OpenCV差了四倍之多,然而是因為OpenCV使用了迴圈的平行運算,因此今日筆記做個簡單的平行運算用法,這裡主要使用自己想法解釋,對理論有興趣可前往微軟或網上有豐富的介紹。
這裡使用雙指標double做走訪動作,大小1000 * 1000運行500次,而運行時間如下圖,需要約30秒。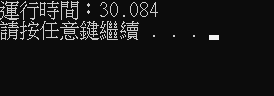
int main()
{
size_t size = 1000;
double** values = new double*[size];
double start = 0.0;
double end = 0.0;
for (size_t index = 0; index < size; index++)
{
values[index] = new double[size];
}
start = clock();
for (size_t time = 0; time < 500; time++)
{
for (size_t row = 0; row < size; row++)
{
for (size_t col = 0; col < size; col++)
{
values[row][col] = (row * col - sin(row) + cos(col)) * exp(row / (col + 1));
}
}
}
end = clock();
cout << "運行時間:" << (end - start) / CLOCKS_PER_SEC << endl;
for (size_t index = 0; index < size; index++)
{
delete[] values[index];
values[index] = nullptr;
}
delete[] values;
values = nullptr;
}
平行運算主要是分配給其他處理器去做處理,而微軟提供了一個函式庫ppl,Intel提供了一個函式庫tbb,這邊主要使用ppl來做介紹。詳細使用可去爬文,這邊直接使用簡單實例了解。
1.引入函式庫。
#include <ppl.h>
2.呼叫函數parallel_for(起始, 結尾, lambda運算式)。
concurrency::parallel_for(0, 500, [&](const int& time) {
for (size_t row = 0; row < size; row++)
{
for (size_t col = 0; col < size; col++)
{
values[row][col] = (row * col - sin(row) + cos(col)) * exp(row / (col + 1));
}
}
cout << time << " ";
});
這邊先加入cout << time << " ";為了先讓我們先理解它每個完成的時間點,如下圖,可以看到每個結束時間不是依序的,有的甚至在" "還沒輸出時另一個已經輸出完成點,而這就是它快速的原因。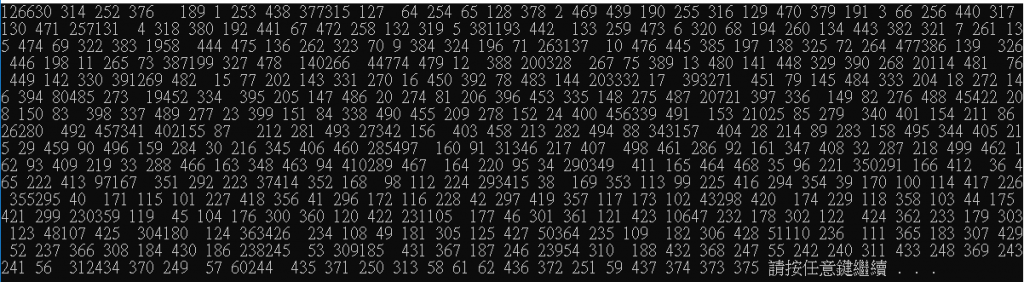
下圖為兩者速度比較,可以看到平行運算所花的時間比一般迴圈來的快許多,這也就能解釋為何昨日介紹的雙邊濾波速度慢的原因了。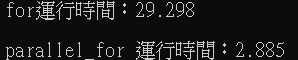
使用400x400大小指標陣列,sigma均為30,濾版大小21x21,模擬運行50次,結果如下圖,只需要2.4s,與昨日相比快了3~4倍,但為了要讓C#使用dll我們將專案性質轉為支援clr,而在clr是不允行include與線程(thread)相關的函式庫。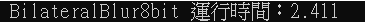
int main()
{
C_UINT32 width = 400;
C_UINT32 height = 400;
C_FLOAT spaceSigma = 30.0f;
C_FLOAT colorSigma = 30.0f;
C_UINT32 size = 21;
C_UCHAE* src = new C_UCHAE[width * height];
UCHAE* pur = new UCHAE[width * height];
Library lib;
double start = 0.0;
double end = 0.0;
start = clock();
for (size_t index = 0; index < 50; index++)
{
lib.BilateralBlur8bit(src, pur, width, height, spaceSigma, colorSigma, size);
}
end = clock();
cout << " BilateralBlur8bit 運行時間:" << (end - start) / CLOCKS_PER_SEC << endl;
delete[] src;
delete[] pur;
}
在C#也有平行做法,以下模擬5000x5000運行500次運算,一般速度約40s,Parallel速度約8s,但在計算量小的時候,使用Parallel反而會增加負擔,這點必須切記。
System.Diagnostics.Stopwatch stopwatch = new System.Diagnostics.Stopwatch();
const int size = 5000;
string result = "";
stopwatch.Reset();
stopwatch.Start();
for (int time = 0; time < 500; time++)
{
for (int row = 0; row < size; row++)
{
for (int col = 0; col < size; col++)
{
int value = row * col;
value = value - row * col;
value = row * col;
}
}
}
result = stopwatch.Elapsed.TotalMilliseconds.ToString();
stopwatch.Reset();
stopwatch.Start();
Parallel.For (0, 500, (int index) => {
for (int row = 0; row < size; row++)
{
for (int col = 0; col < size; col++)
{
int value = row * col;
value = value - row * col;
value = row * col;
}
}
});
result = stopwatch.Elapsed.TotalMilliseconds.ToString();
雖然很可惜無法用在C#呼叫C++上面,但也學到了一個新的平行函數,而在C#使用平行函數的成本比C++來的大,若對計算有要求其實可以不用clr做法,方法一可以寫C++介面,方法二寫C++ Win32應用程式使用C#呼叫,我想這也是可行方法之一,但切記關於多線程若沒有使用lock則會隨意地執行。
而在平行還有許多函數可以使用有興趣可以自行去微軟教學網站學習,若有問題或文章有誤歡迎留言和指導謝謝。
[1]https://msdn.microsoft.com/zh-tw/library/dd504906.aspx
[2]https://docs.microsoft.com/zh-tw/dotnet/standard/parallel-programming/how-to-write-a-simple-parallel-for-loop
 Kevin
Kevin
