這邊我們用 relational MySQL Database 的 World Dataset 來做範例
https://relational.fit.cvut.cz/dataset/CCS
SELECT Time,
(CASE
WHEN Time < '12:00:00' THEN 'AM'
ELSE 'PM'
END) as TimeRange,
ProductID,GasStationID FROM ccs.transactions_1k
除了本來的消費時間,我們這邊另外把時間多歸類成一個上下午的欄位,
query 出的資料如下: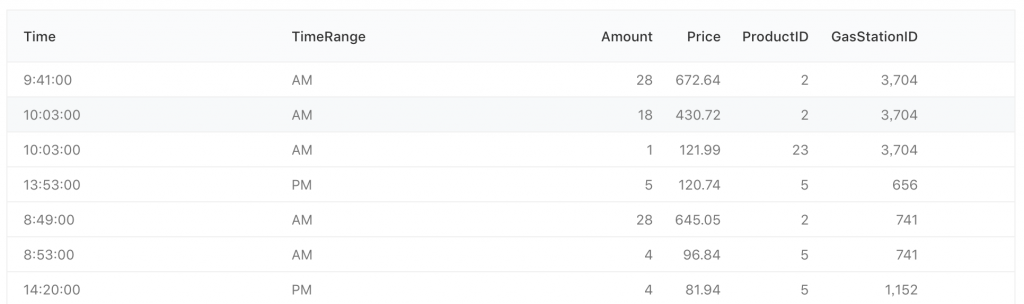
大概可以看到 交易時間上下午都有可能,同樣的商品在不同時間也被購買了好幾次,而地點也有可能發生在不同的加油站,但直接從表格 Table 看資料看不太出來所以然,而這種關係又似乎不太適用於前面介紹的各種圖表。
這時 Pivot Table 樞紐分析表,就可以讓我們很容易可以「透視」這些資料:
假設我們想看商品 ProductID 跟購買時間 TimeRange 的關係,
在 Pivot Table 的圖表就分別把此兩欄放到 左方或上方欄位,
就可以很清楚看到 兩欄位的關係,在上午或下午 某個商品被購買了幾次:
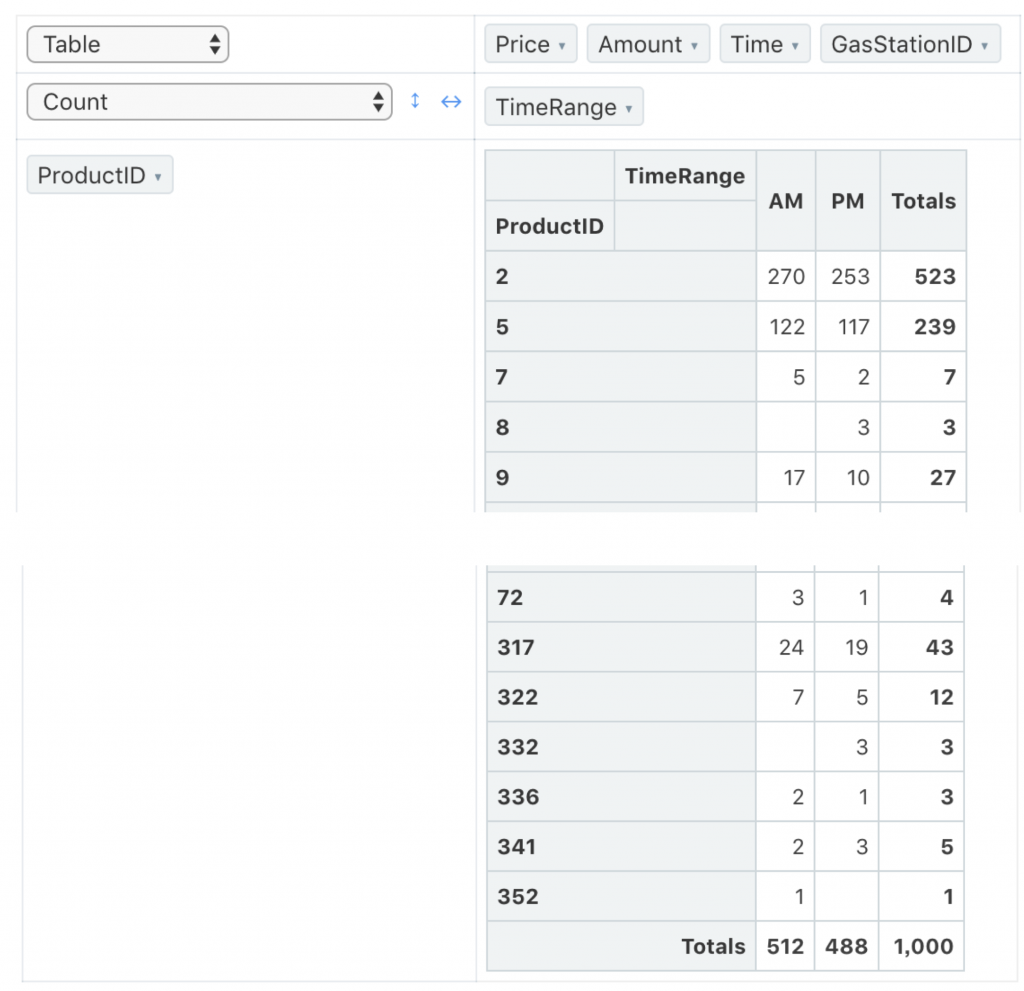
一定會想說,這種結果用 SQL 語法也可以做到
SELECT ProductID,
(CASE
WHEN Time < '12:00:00' THEN 'AM'
ELSE 'PM'
END) as TimeRange, Count(TransactionID)
FROM ccs.transactions_1k
GROUP BY TimeRange,ProductID
ORDER BY ProductID,TimeRange
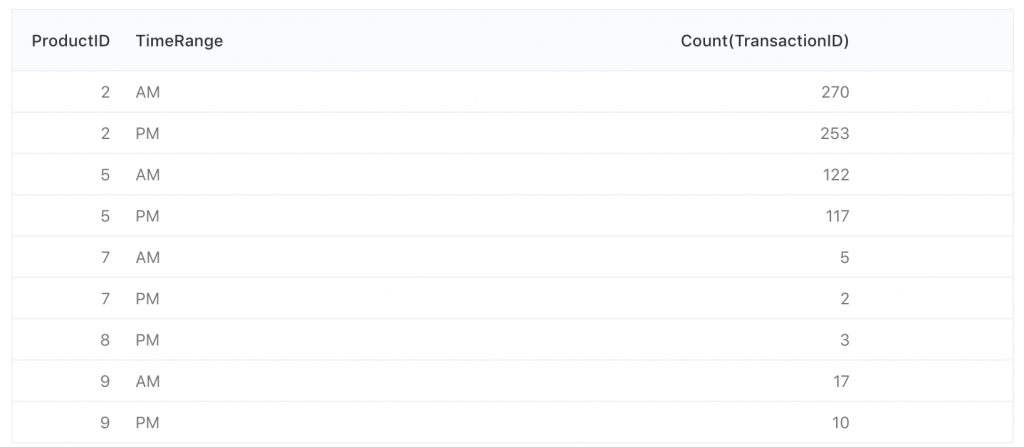
但差別就是因為 SQL 的 GROUP BY 結果是
每一個不同的資料會放一列,就無法很清楚的整合
在 Pivot Table 除了可以用「轉換」過的表格,來透視這些資料,
同時每一列、每一欄的最後還有總和的欄位,
而且還提供了比起 SQL 語法更多元的統計值類別與功能:
最左上角是可選何種樣式的表格
635<1696但卻有更大的圖式)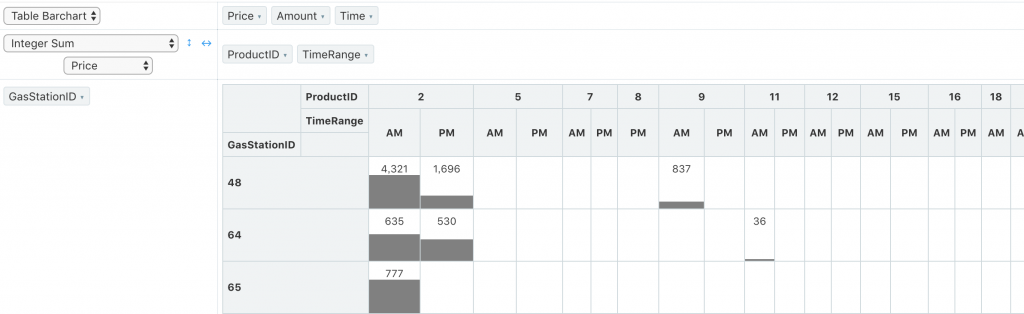
Average, Median, Sample Variance, Sample Standard Deviation, Minimum, Maximum, First, Last 就如同字面上所說是常見的統計值,針對幾個比較好用也特殊的選項做介紹:
列出所有,所以表格會很大)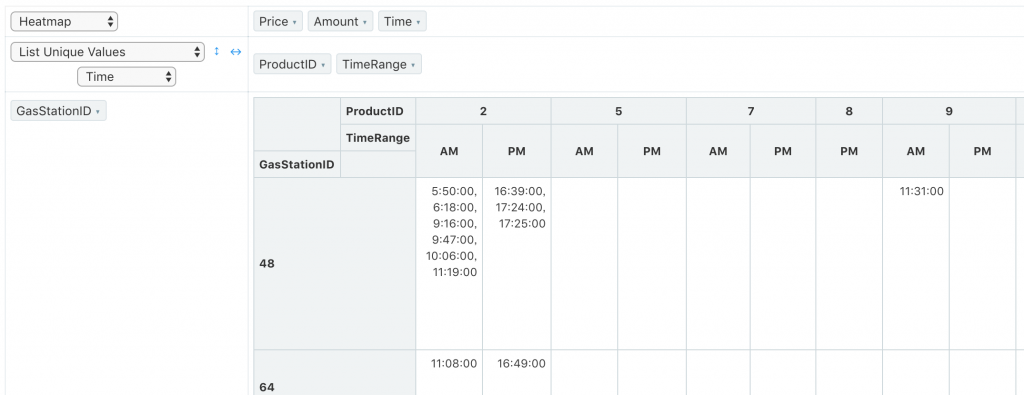
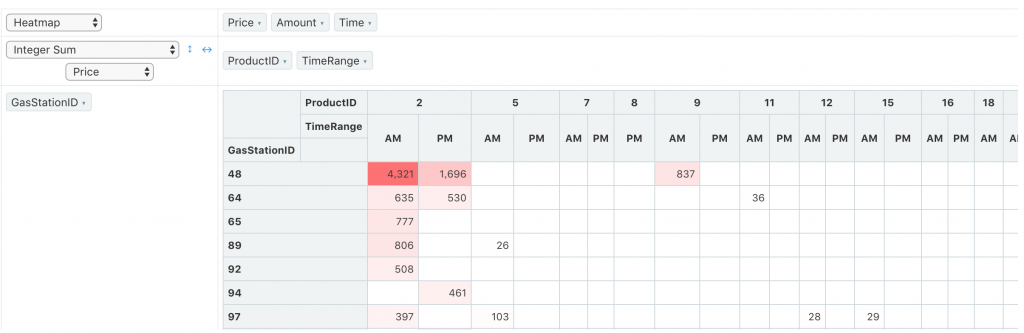
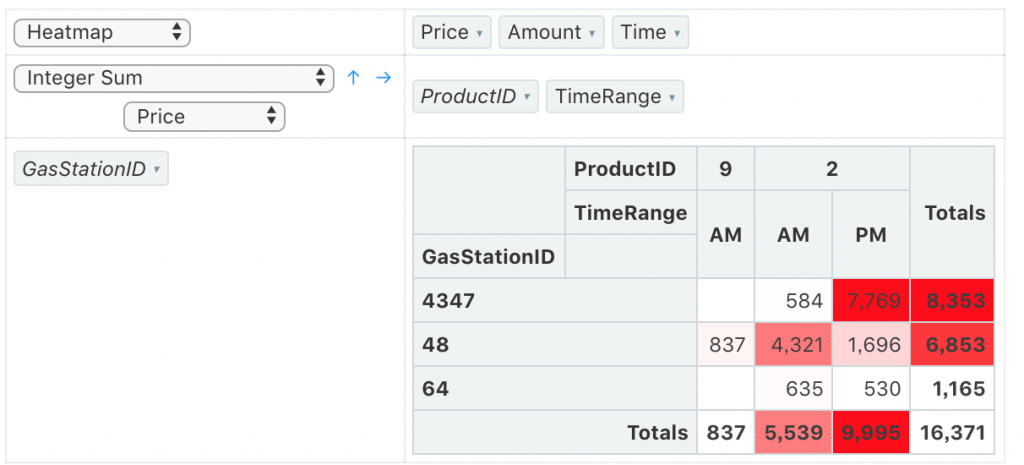
在 Redash 的 Pivot Table 圖表,就算資料內容是整數,
直接用Sum還是會出現兩位為 0 的小數點,
用Integer Sum資料就很乾淨
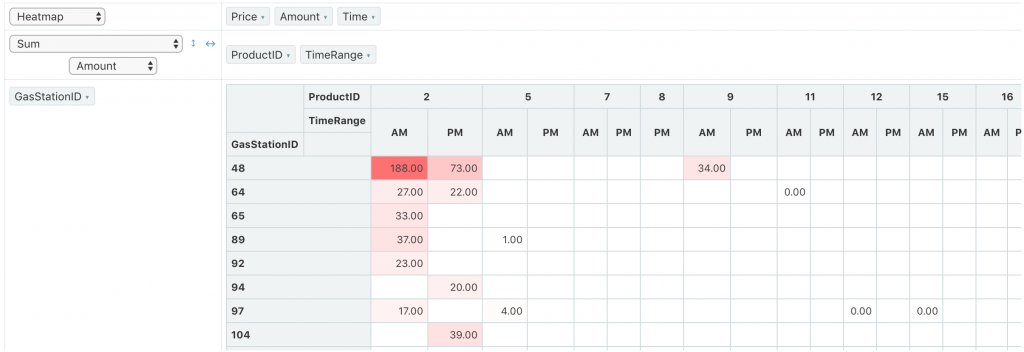
而以下這三個統計值,礙於時間關係,還沒有很清楚實際的運作方式
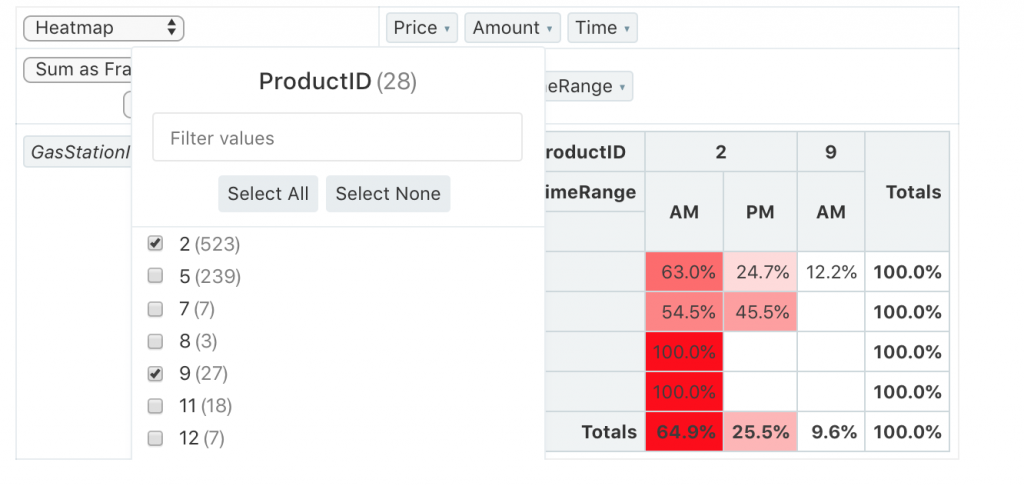
可以選擇只要該列或該欄的哪些資料做透視
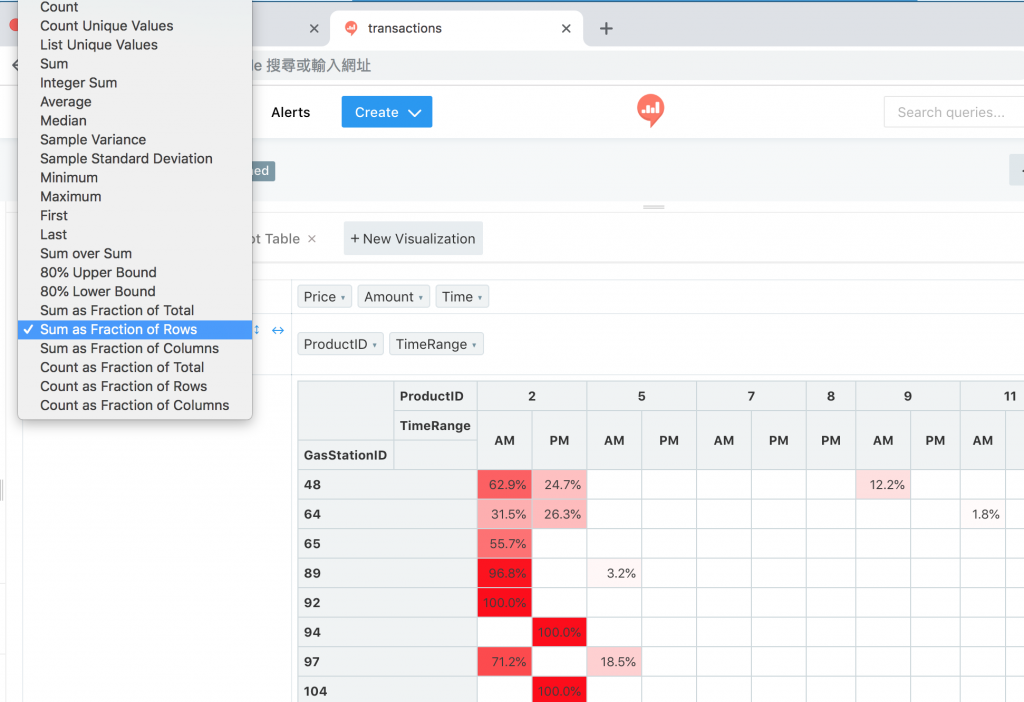
注意像是佔比等統計值,會只計算篩選後的佔比,而不是以未篩選前的原值當分母
在「統計值」的功能旁有兩個藍色箭頭圖示,分別代表欄、列要依何種方式排序:
預設是以該軸的大小,而點擊一下、兩下分別代表由小到大、由大到小的排序方式,點三下則是歸回預設;而排序參考會以那列「最右方」「最下方」的總值(Totals)來做排序條件
在旅遊電商的使用經驗,訂單的資料是各部門最容易使用的資料:
思考的面向會有
會看的統計值不外乎以下在各面向的總數、平均、占比
這些都會把它拉成一張包含所有資訊的統一大表,
然後建立一個範例 Pivot Table 圖表讓大家參考,
讓所有想看不同面向統計值的同事們自行操作。
在以前,往往更改一個維度的資料,
eg. 想看各旅遊地區的訂單總金額、占比就會一組 query,
如果之後需求再加上同時搭配各時間點,就還是得要技術人員出馬,
而往往需求只會增加不會減少的 0rz
用以上方式配合 Pivot Table,的確在公司的流程中,
減少了不少這些來回增加探索需求與改動的時間過程,
讓我更能專注開發在更有價值的專案!
ps. 文章同步發表於 Medium


 iThome鐵人賽
iThome鐵人賽