補上昨天說的,有了這個東西就可以花更多時間在特徵工程(多爬資料,多瞭解股市的知識),花更少時間試模型。
這邊自定義一個function加入Pipeline可以算出最佳累積天數跟模型的參數
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['figure.figsize'] = (15, 15)
plt.rcParams['font.sans-serif']='DFKai-SB'
plt.rcParams['axes.unicode_minus'] = False
from mongo import MongoDatabase
import pandas as pd
with MongoDatabase('stock_day') as conn:
stock = conn.export_df({'code':'2330','date':{'$gte':'2018/02/27','$lte':'2018/11/12'}})
stock['date']=pd.to_datetime(stock['date'])
stock=stock.sort_values('date').set_index('date')
data=stock.select_dtypes(include=['int64','float64'])
data.columns
Index(['成交股數', '成交金額', '開盤價', '最高價', '最低價', '收盤價', '漲跌價差', '成交筆數', '三大法人買賣超','外資自營商買賣超', '外資自營商買進', '外資自營商賣出', '外陸資買賣超', '外陸資買進', '外陸資賣出', '投信買賣超','投信買進', '投信賣出', '自營商買賣超', '自營商買賣超避險', '自營商買進', '自營商買進避險', '自營商賣出','自營商賣出避險', '融券今日餘額', '融券前日餘額', '融券現金償還', '融券買進', '融券賣出', '融券限額','融資今日餘額', '融資前日餘額', '融資現金償還', '融資買進', '融資賣出', '融資限額', '資券互抵', '借券今日可限額','借券前日餘額', '借券當日調整', '借券當日賣出', '借券當日還券', '借券當日餘額'], dtype='object')
預測5天後的收盤價,切7訓練3測試
y=data[['收盤價']].shift(-5)[:-5]
X=data[:-5]
offset = int(X.shape[0] * 0.7)
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
from sklearn.base import BaseEstimator, TransformerMixin
class RollingWindow(BaseEstimator, TransformerMixin):
def __init__(self, window=4):
self.window = window
def transform(self, X, y=None):
for col in X.columns:
X=pd.merge(X, X[col].rolling(window=self.window,min_periods=1).agg(['sum','std','mean','max','min','median','kurt','skew']),on='date',suffixes=('','_'+col) )
X=X.fillna(0)
return X
def fit(self, X, y=None):
return self
交叉驗證記得要改成用TimeSeriesSplit,自動嘗試出最佳參數
import warnings
from sklearn.exceptions import DataConversionWarning
warnings.filterwarnings("ignore", category=DataConversionWarning)
from sklearn.pipeline import Pipeline
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import TimeSeriesSplit, GridSearchCV
my_cv = TimeSeriesSplit(n_splits=4).split(X_train)
pipeline=Pipeline([
('Rolling',RollingWindow() ),
('GBR',GradientBoostingRegressor() ),
])
param={
'Rolling__window':[7,8,9],
'GBR__n_estimators': [100,150,200],
'GBR__max_depth': [4,5]
}
clf = GridSearchCV(pipeline, param, cv=my_cv)
clf.fit(X_train, y_train)
GridSearchCV(cv=<generator object TimeSeriesSplit.split at 0x0000023CC2BCA888>,
error_score='raise',
estimator=Pipeline(memory=None,
steps=[('Rolling', RollingWindow(window=4)), ('GBR', GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.1, loss='ls', max_depth=3, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None,...s=100, presort='auto', random_state=None,
subsample=1.0, verbose=0, warm_start=False))]),
fit_params=None, iid=True, n_jobs=1,
param_grid={'Rolling__window': [7, 8, 9], 'GBR__n_estimators': [100, 150, 200], 'GBR__max_depth': [4, 5]},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
clf.best_estimator_.get_params()
{'memory': None,
'steps': [('Rolling', RollingWindow(window=7)),
('GBR',
GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.1, loss='ls', max_depth=5, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=150, presort='auto', random_state=None,
subsample=1.0, verbose=0, warm_start=False))],
'Rolling': RollingWindow(window=7),
'GBR': GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.1, loss='ls', max_depth=5, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=150, presort='auto', random_state=None,
subsample=1.0, verbose=0, warm_start=False),
'Rolling__window': 7,
'GBR__alpha': 0.9,
'GBR__criterion': 'friedman_mse',
'GBR__init': None,
'GBR__learning_rate': 0.1,
'GBR__loss': 'ls',
'GBR__max_depth': 5,
'GBR__max_features': None,
'GBR__max_leaf_nodes': None,
'GBR__min_impurity_decrease': 0.0,
'GBR__min_impurity_split': None,
'GBR__min_samples_leaf': 1,
'GBR__min_samples_split': 2,
'GBR__min_weight_fraction_leaf': 0.0,
'GBR__n_estimators': 150,
'GBR__presort': 'auto',
'GBR__random_state': None,
'GBR__subsample': 1.0,
'GBR__verbose': 0,
'GBR__warm_start': False}
from sklearn.metrics import mean_absolute_error,mean_squared_error,\
explained_variance_score,mean_squared_log_error,r2_score,median_absolute_error
def regression_evaluation(y_test, y_pred):
print("Mean squared error: %.2f"% mean_squared_error(y_test, y_pred))
print("Mean absolute error: %.2f"% mean_absolute_error(y_test, y_pred))
print("Mean squared log error: %.2f"% mean_squared_log_error(y_test, y_pred))
print("R^2: %.2f"% r2_score(y_test, y_pred))
print("Median absolute error: %.2f"% median_absolute_error(y_test, y_pred))
print("Explained variance score: %.2f"% explained_variance_score(y_test, y_pred))
y_pred = clf.predict(X_test)
regression_evaluation(y_test, y_pred)
Mean squared error: 161.81
Mean absolute error: 11.01
Mean squared log error: 0.00
R^2: 0.22
Median absolute error: 11.71
Explained variance score: 0.29
def plot_predict(y,predict_list,y_test, y_pred,code):
data=pd.DataFrame()
data[y_pred]=predict_list
data[y_test]=y['收盤價'].tolist()
data['date']=y.index
data=data.set_index('date')
data[[y_test,y_pred]].plot(title=code,figsize=(20,10))
plot_predict(y,clf.predict(X),'5天後收盤價', '預測收盤價','2330')
一樣在test上的預測很不準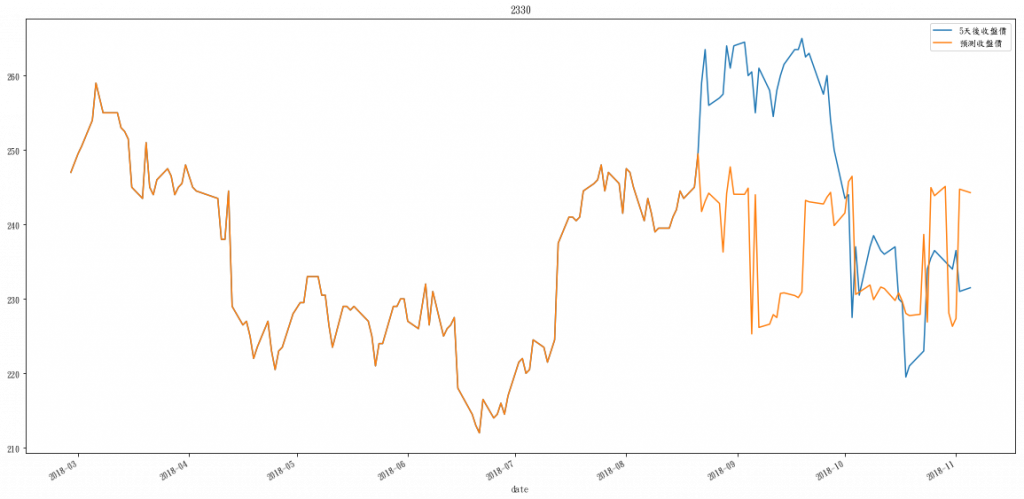
def plot_feature_importances(clf,X):
feature_importance = clf.feature_importances_
feature_importance = 100.0 * (feature_importance / feature_importance.max())
sorted_idx = np.argsort(feature_importance)
pos = np.arange(40) + .5
plt.figure(figsize=(10,30))
plt.barh(pos, feature_importance[sorted_idx[-40:]], align='center')
plt.yticks(pos, X.columns[sorted_idx[-40:]])
plt.xlabel('Relative Importance')
plt.title('Feature Importance')
plt.show()
X_feature=clf.best_estimator_.steps[0][1].transform(X)
plot_feature_importances(clf.best_estimator_.steps[1][1] , X_feature)
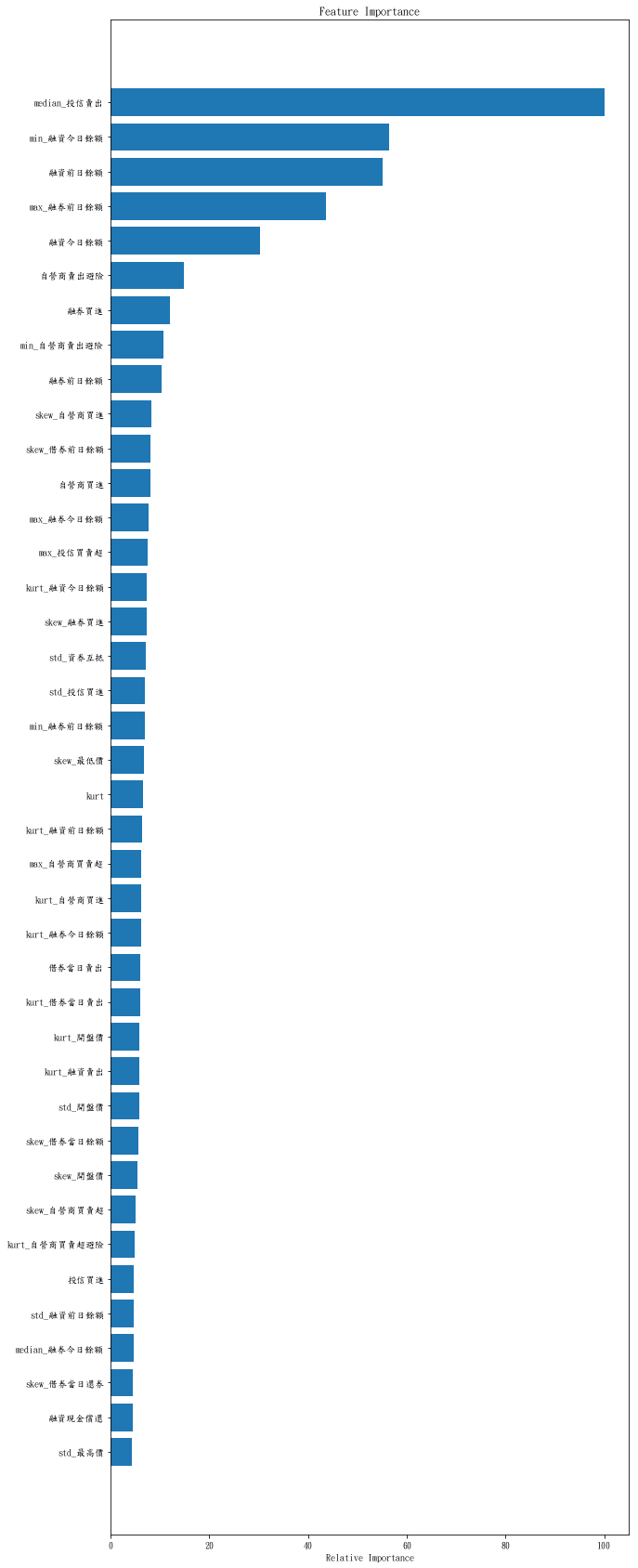
目前還是人工判斷,之後會繼續研究,嘗試更多特徵,並把人工的觀察盡量量化,在成功研究出來前,還是好好學爬蟲跟資料分析去找個穩定的工作邊工作邊研究比較實際。


 iThome鐵人賽
iThome鐵人賽