參考來源:https://www.guru99.com/linux-regular-expressions.html
正則表達式是特殊字符,可幫助搜索數據,匹配複雜模式。正則表達式縮寫為“regexp”或“regex”。
正則表達式的類型:
一些常用的正則表達式命令是tr,sed,vi和grep。下面列出了一些基本的正則表達式。
符號 說明
。 替換任何角色
^ 匹配字符串的開頭
$ 匹配字符串的結尾
例子:
執行cat示例以查看現有文件的內容。
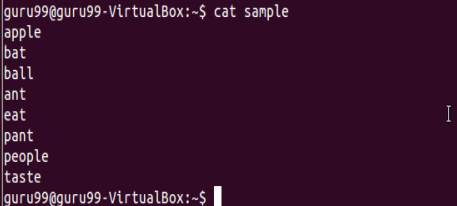
搜索包含字母'a'的內容。
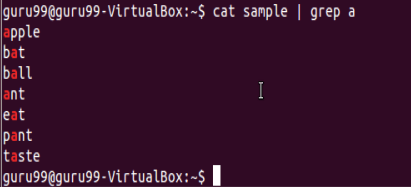
' ^ '匹配字符串的開頭。讓我們一起搜索STARTS的內容。

僅過濾以字符開頭的行。忽略開頭不包含字符“a”的行。
例2: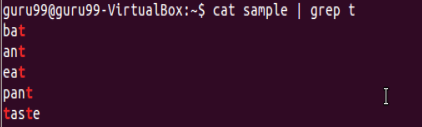
僅選擇那些以$結尾的行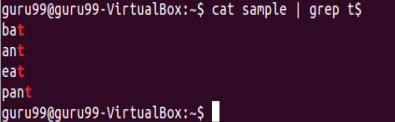
區間正則表達式
這些表達式告訴我們字符串中字符的出現次數。他們是:
表達 描述
{N} 匹配前面的字符完全出現'n'次。
{N,M} 匹配前面的字符出現'n'次但不超過m。
{n,} 僅當前一個字符出現'n'次或更多時才匹配前一個字符。
例:
過濾掉包含字符'p'的所有行

我們想要檢查字符“p”在一個接一個的字符串中正好出現2次。為此,語法將是:
cat sample | grep -E p{2}
注意:需要為這些正則表達式添加-E。
擴展正則表達式
這些正則表達式包含多個表達式的組合。他們之中有一些是:
表達 描述
\ + 匹配前一個字符的一個或多個匹配項。
\? 匹配前一個字符的零次或一次匹配。
例:
搜索所有字符't'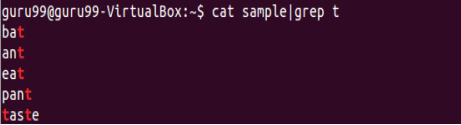
我們可以使用命令
cat sample|grep "a+t"
支撐擴張
大括號擴展的語法是大括號“{}”內的序列或逗號分隔的項列表。序列中的起始和結束項由兩個句點“..”分隔。
一些例子: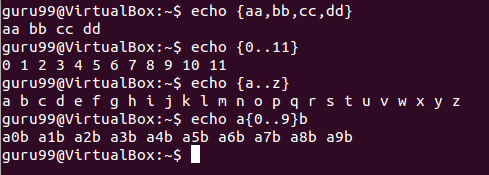
在上面的示例中,echo命令使用大括號擴展創建字符串。
之後學環境變量。

