查看資料欄位相關性,並做出判斷
培養分析資料的能力


基礎分析部分:
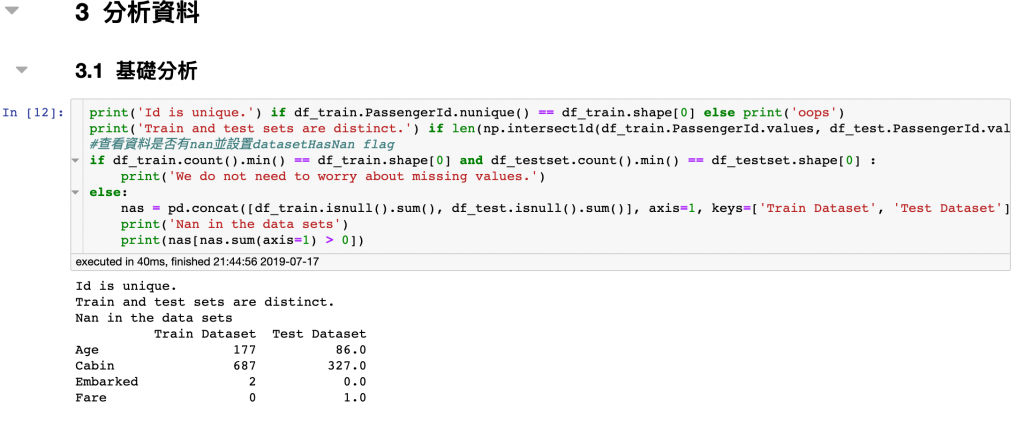
測試資料集ID都沒重複
測試與訓練資料集也沒重疊
但我們有很多缺值,再進一步分析
Age,Cabin,Embarked有很多缺值,而這邊我們還發現一個漏網之魚,Fare在測試資料集有個缺值需填補
而在相關性分析部分:
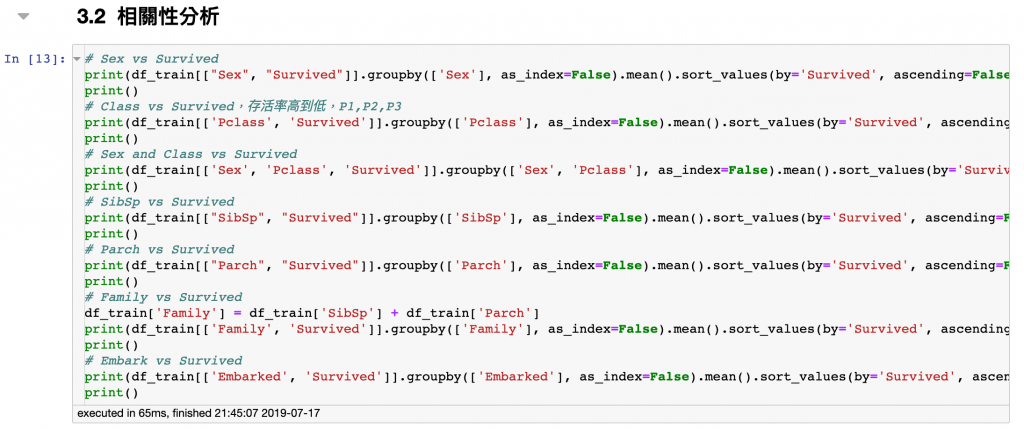
df_train['Family'] = df_train['SibSp'] + df_train['Parch']
注意:這邊將旁系與直系血親合併並新增為家族方便觀察關係
1.大部分男生都死了,大部分女生活下來
2.階級跟存活率成正比
3.最低艙等女性存活率還是比最高艙等男性高
4.旁系血親1個存活率最高
5.直系血親3個存活率最高
6.如果加總,有3個親友存活率高
7.船艙存活率C>Q>S
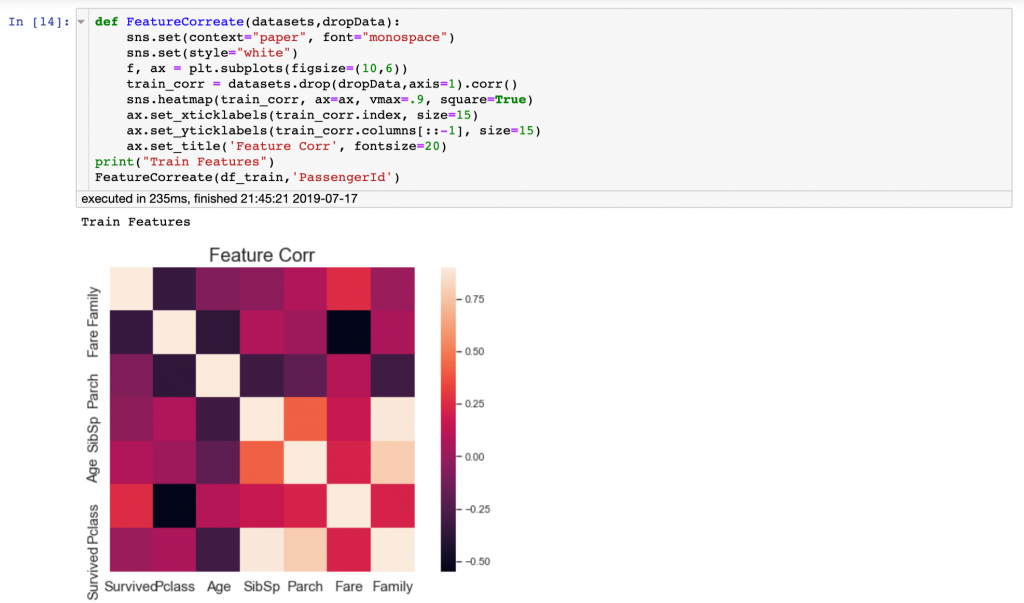
我們也可以繪Feature Correlation的heatmap來做特徵選擇
再來看一下heatmap
正相關(白色):
1.家族跟獲救
2.票價跟階級
3.直系血親跟年齡
4.生存跟旁系
5.旁系跟家族
負相關(黑色):
1.票價跟獲救
2.家族跟階級
3.直系血親跟階級
4.票價跟年齡
5.旁系血親跟年齡
6.生存跟年齡
7.直系跟旁系血親
8.直系跟家族
資料觀察跟分析得差不多了,接下來可以開始填補缺值,一般來說我們不會更動原始資料表,一切都是複製訓練與測試資料集成為一個大表格後在記憶體內運算
https://towardsdatascience.com/feature-selection-correlation-and-p-value-da8921bfb3cf

