經過三天的基本名詞解釋以及建置爬蟲開發環境,相信各位讀者對於這些已經有初步的了解了。
接下來在第一個案例研究之前,我想先講一下有關於爬蟲「設計」的部份。首先,我們先試著回想一下,在大學的時候是不是大家都有一個經驗,就是會想要知道學校最新的訊息?我們通常都會在學校的網站上找尋這類的訊息。
但是,有的時候我們不太可能有一個固定時間,一直上去學校網站觀看最新消息,因此我們會想到會不會有一個程式或是服務可以幫我們擷取我們想要的資料下來?
因此這樣的一個案例研究就產生了,就是開發一個「擷取學校最新新聞」爬蟲。那我就以此學校為例子。
首先,我們進去網站之後,會看到如下的畫面。
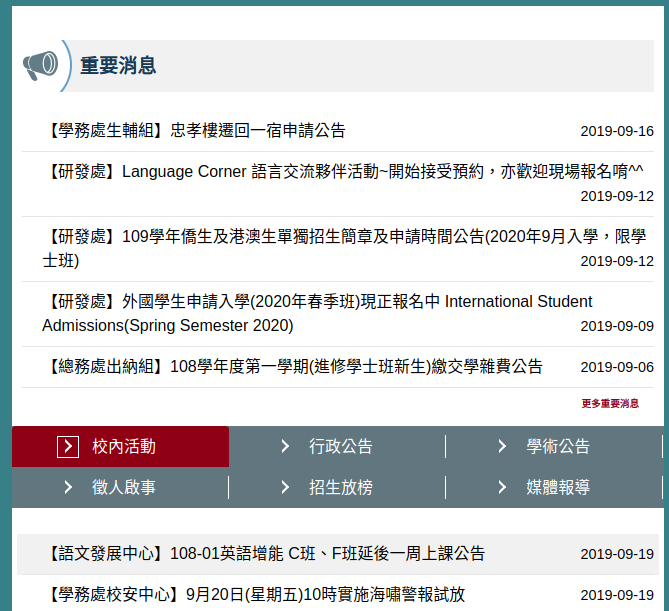
我們可以從上面的圖片知道,有上下欄位有消息的地方,一個是「重要消息」,另一個是六個最新消息的分類。
分別是「校內活動」,「行政公告」,「學術公告」,「徵人啟事」,「招生放榜」與「媒體報導」。
接下來我們點選「重要消息」之後,我們會到這裡,也如下圖所示。

我們可以知道,這個最新消息頁面有「RSS」訂閱頻道以及重要消息的列表。
其他的六個重要消息也是如同「重要消息」一樣,有對應的列表以及RSS訂閱頻道。
到這裡,基本的爬蟲設計就會出來了。下列是爬蟲的兩種開發方式:
RSS頻道進行擷取。RSS頻道RSS連結RSS
HTTP請求拿到每個消息列表網址連結JavaScript AJAX發送HTTP POST請求拿到分頁得消息資訊。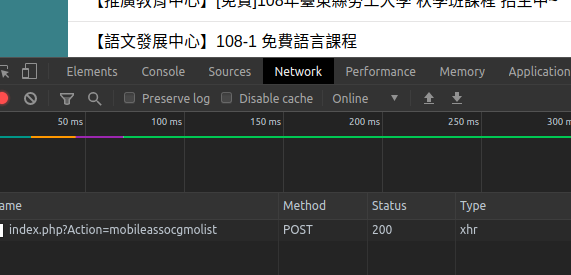
從上圖得知,我們可以透過Google Chrome F12打開的網頁開發控制台,找到當滾動到頁面最下面的時候,會再次發送請求,拿到下一個分頁的消息,如下圖就是每次發送AJAX請求所拿到的表單資料。
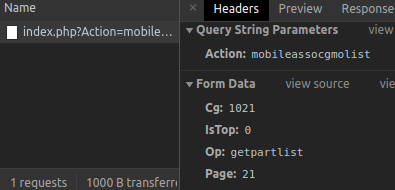
這兩種方式差異性是什麼?RSS方式只能抓到「最新」消息,沒有辦法儲存歷史的消息,當要追溯歷史訊息時,這個爬蟲就比較無法達成我們要的。
那第二種就可以達到擷取歷史消息與公告,所以從上述簡易比較,我們可以知道「利用消息列表」爬蟲會是最好的選擇。
1-1可以知道,當我們要抓取學校的「最新消息」的分析與實做的方法。1-2,就會實際的寫code來實做這兩種方法來達成我們要的擷取最新消息爬蟲。
