
今天我們要來繼續 CNN 的前行計算之路(Forward)所需要用到的計算模式,會順便提一下在 Pooling 以及 Activation 上不同的選擇以及效果
我們再次參考上一章的圖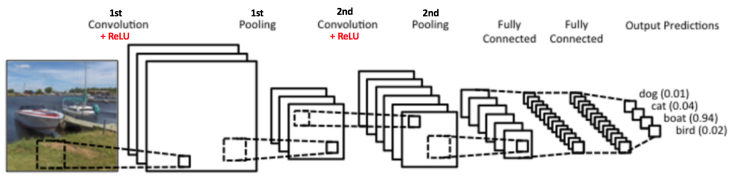
從這張圖我們可以看到 Convolution layer完了之後琪時並不會立刻屆下一層的 Convolution Layer,反而是會有Activation layer 以及pooling layer等 Layer 出現,我們依次來介紹這兩種 layer 的運算行為為何?
Pooling Layer 也被稱為 Downsampling 、 Spatial Pooling)或 Subsampling,主要是可以縮小、濃縮 Feature map,但同時希望能夠保留 Feature map 內的關鍵訊息。效果就像是這個下面連結一樣:
Pooling效果參考
把一張照片擷取些小照片資訊拼起來,畫面變小但還是看得出來是啥
Pooling主要的效果有:

最開始的時候,科學家們參考了生物學界的神經在傳遞資訊給下一個神經元時會有全有全無律,意即如果不超過一定量值時,是不會傳遞資訊下去的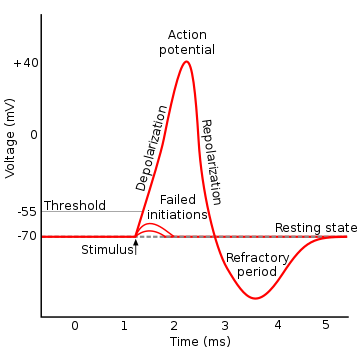
在類神經網路中使用Activation Function(激勵函數),主要是利用非線性方程式,解決非線性的問題,若不使用激勵函數,類神經網路即是以線性的方式組合運算(意即多個矩陣相乘還是只是個矩陣),而Activation Function其實可以隨意設計但有以下兩個限制:
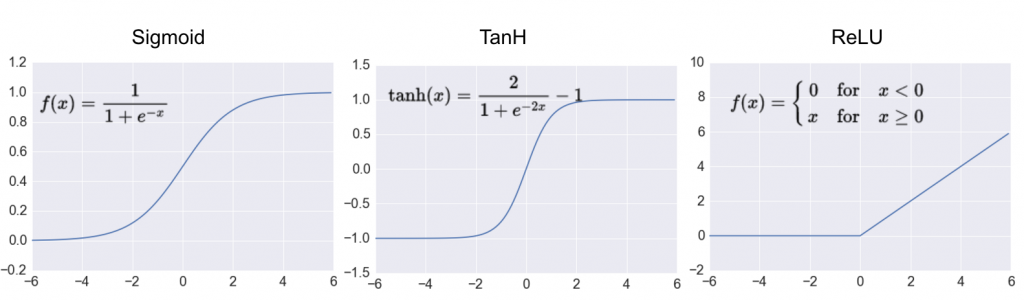
有了這些工具,其實我們已經有能力可以構建出一個 CNN 模型,但這個雖然能動,卻還不具備學習的能力,因此下一章我們將介紹 CNN 進步的動力: Backpropagation !

 iThome鐵人賽
iThome鐵人賽