在編寫處理字串的程式或網頁時,經常會有查找符合某些複雜規則的字串的需要,正規表示式就是用於描述這些規則的工具,它定義了字串的匹配模式。檢查一個字串是否有跟某種模式匹配的部分或從一個字串中將與模式匹配的部分提取出來或替換。
如果你在的 Windows 操作系統中使用過文件查找並且在指定文件名時使用過通配符( * 和 ? ),正規表示式是類似的文本匹配工具,它能更精確地描述你的需求。比如可以編寫一個正規表示式,用來查找所有以 0 開頭,後面跟著 2 ~ 3 個數字,然後是一個連字號 '-',是 7 或 8 位數字的字串(如 028-12345678 或 0813-7654321),我們希望計算機能夠識別和處理符合某些模式的文本,正則表達式就顯得非常重要了。幾乎所有的程式語言都提供了對正則表達式操作的支持,Python 透過 re 模組支持正規表示式操作。
正規表示式中的一些基本符號進行的扼要總結。如果需要匹配的字符是正則表達式中的特殊字符,那麼可以使用 \ 進行轉義處理,例如想匹配小數點可以寫成 .,因為直接寫 . 會匹配任意字元,想匹配圓括號必須寫成 ( 和),否則圓括號被視為正規表示式中的分組。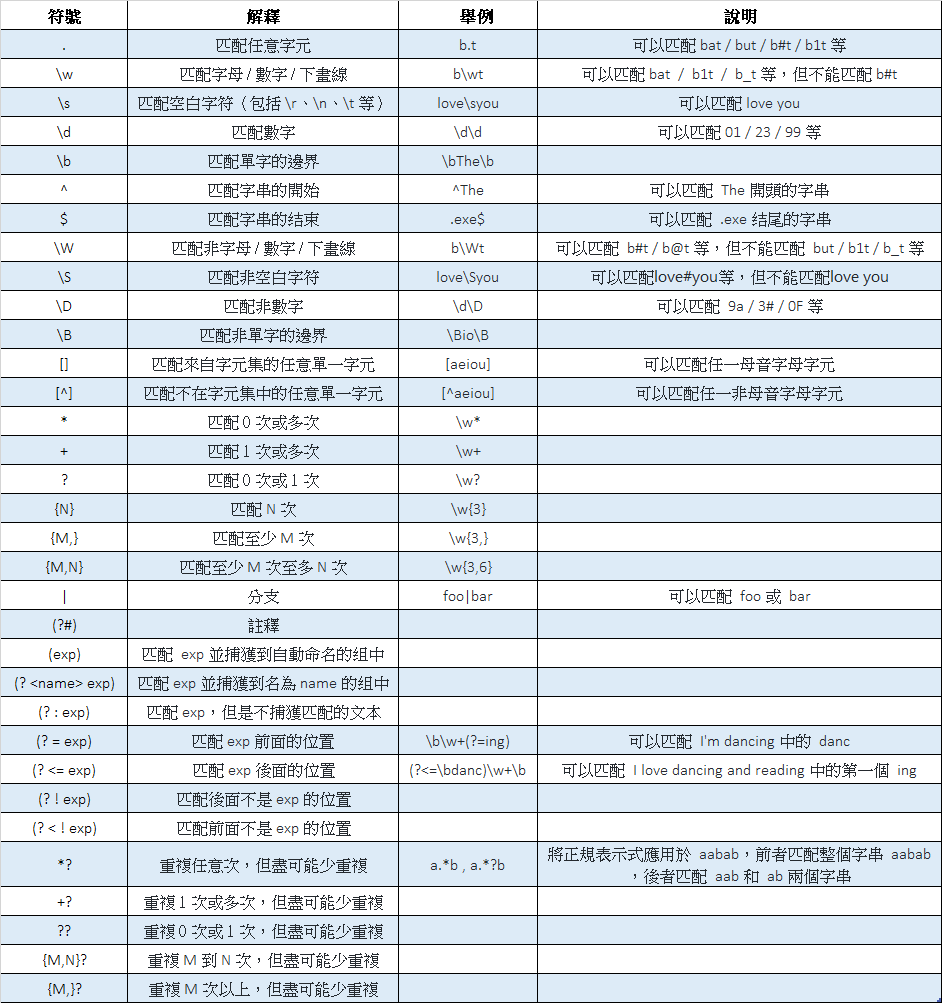
Python 中提供了 re 模組對正規表示式的相關操作,下面是 re 模組中的核心函數。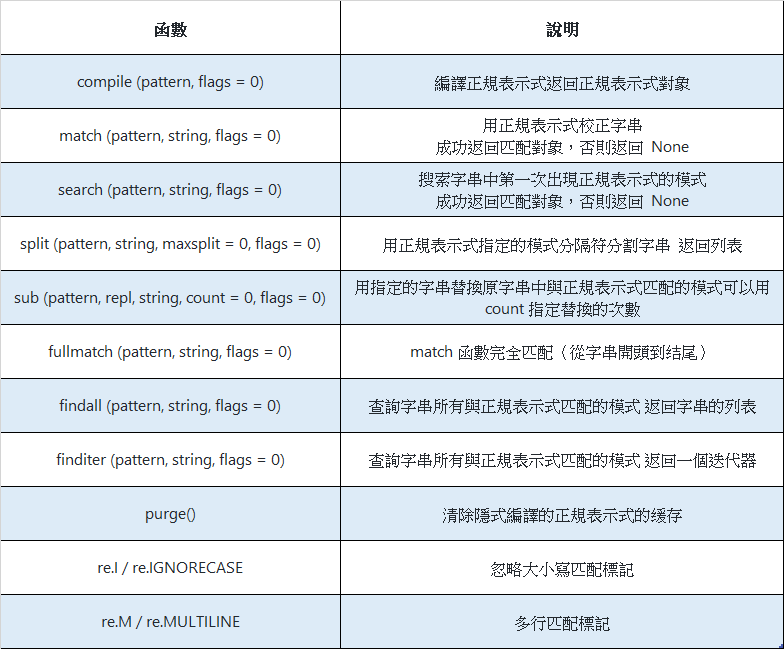
下面範例中使用正規表示式時使用'原始字串'的寫法(在字串前面加上 r),原始字串就是字串中的每個字元都是它原始的意義,就是字串中沒有轉義字元。因為正規表示式中有很多元字元和需要進行轉義的地方,如果不使用原始字串就需要將反斜線寫作 \。例如表示數字的 \d 就得書寫成 \d。
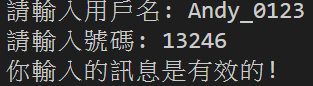
範例1 - 驗證輸入用戶名和號碼是否有效並給出對應的提示訊息。
用戶名必須由字母、數字或下畫線構成且長度在 6 ~ 20 個字元之間,號碼是 5 ~ 12 個數字且第一位不能是 0。
import re
def main():
username = input('請輸入用戶名: ')
number = input('請輸入號碼: ')
# match函數的第一個參數是正規表示式字串或正規表示式對象
# 第二個參數是要跟正規表示式做匹配的字串
m1 = re.match (r'^[0-9a-zA-Z_]{6,20}$', username)
if not m1:
print('請輸入有效的用戶名')
m2 = re.match (r'^[1-9]\d{4,11}$', number)
if not m2:
print('請輸入有效的號碼')
if m1 and m2:
print('你輸入的訊息是有效的!')
if __name__ == '__main__':
main()

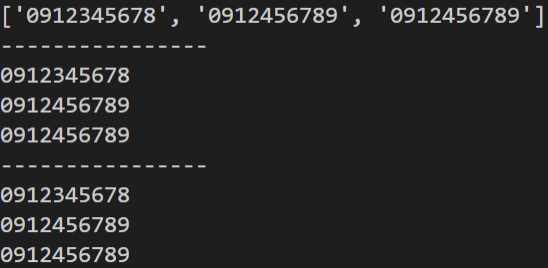
範例2 - 從一段文字中提取出手機號碼。
import re
def main():
# 創建正規表示式對象
pattern = re.compile(r'(?<=\D)09[0-9]{8}(?=\D)')
sentence = '''
重要的事情說 0123456789 遍,Andy 的手機號碼是 0912345678,
不是 0912456789,也不是 110 或 119,Alan 的手機號碼才是 0912456789。
'''
# 查詢所有匹配並保存到一個列表中
mylist = re.findall(pattern, sentence)
print(mylist)
print('----------------')
# 利用迭代器取出匹配對象並獲得匹配的内容
for temp in pattern.finditer(sentence):
print(temp.group())
print('----------------')
# 利用 search 函數指定搜索位置找出所有匹配
m = pattern.search(sentence)
while m:
print(m.group())
m = pattern.search(sentence, m.end())
if __name__ == '__main__':
main()
範例3 - 替換字串中的不良內容。
import re
def main():
sentence = '你是笨蛋? Fuck!!! shit!!!'
purified = re.sub('fuck|shit|笨蛋',
'*', sentence, flags = re.IGNORECASE)
print(purified)
if __name__ == '__main__':
main()

範例4 - 拆分長字串。
import re
def main():
poem = '床前明月光,疑是地上霜。舉頭望明月,低頭思故鄉。'
sentence_list = re.split(r'[,。, .]', poem)
while '' in sentence_list:
sentence_list.remove('')
print(sentence_list)
if __name__ == '__main__':
main()


