基本流程
1.連線到特定網址,抓取資料
2.解析資料,取得實際想要的部分
JSON格式資料
使用內建json模組即可
HTML格式資料
使用第三方套件BeautifulSoup來做解析
安裝套件
PIP套件管理工具:安裝Python時,就一起裝在電腦裡了
安裝BeautifulSoup:pip install beautifulsoup4
程式範例:
(連線被程式拒絕,因而我們需要使自己像一位普通的使用者來操作它,不能直接附上網頁的網址來找尋資料)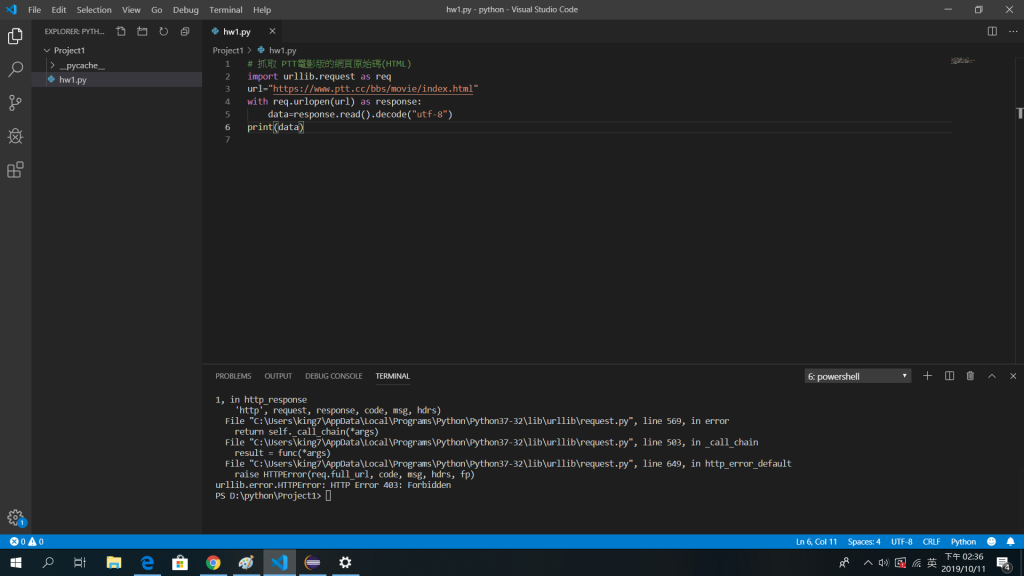
(為了解除這個問題,我們必須到原始網頁,點擊右上方的自訂及管理Chrone > 更多工具 > 開發人員資料 > network > 重新整理頁面 > 找到上方的index內的Headers > Request Headers的user agent > 複製下方網址)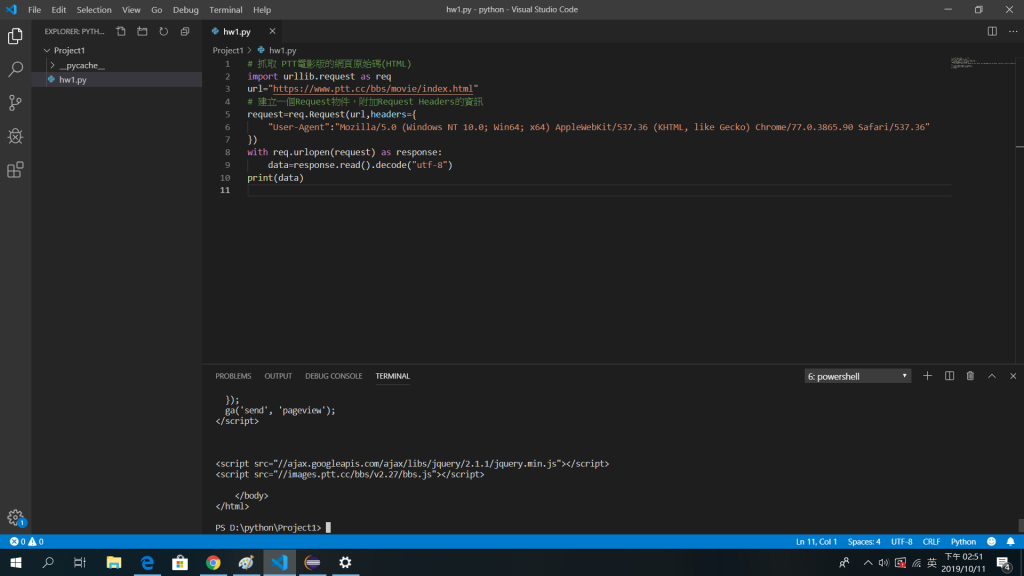
(安裝套件後,抓取網頁標題)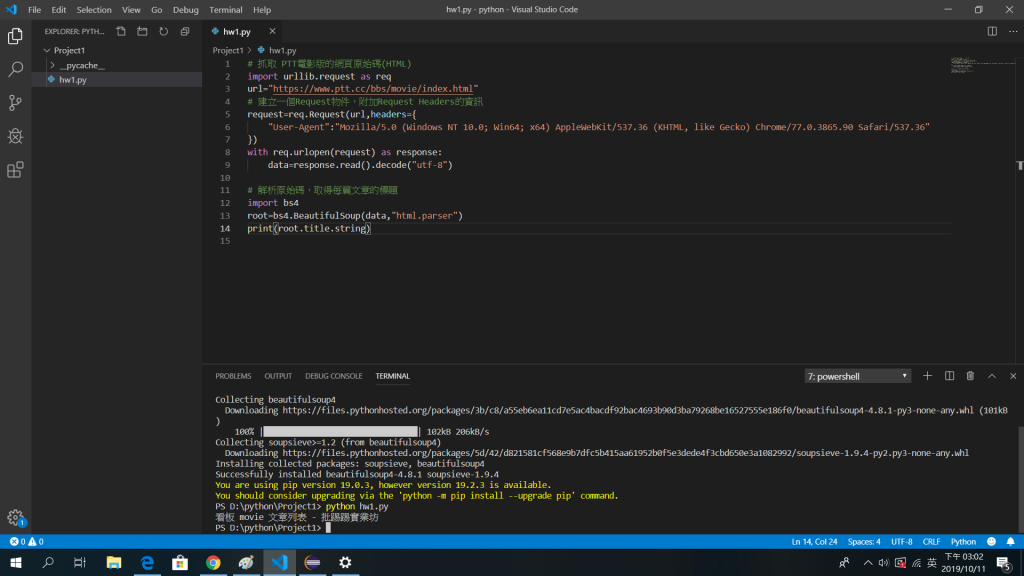
(抓取單一文章標題)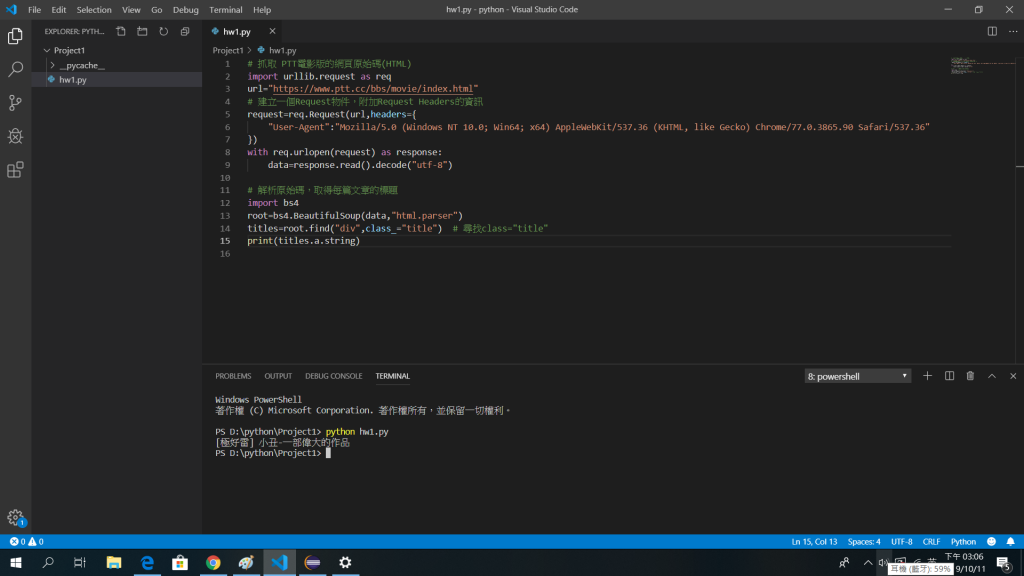
(抓取所有文章標題)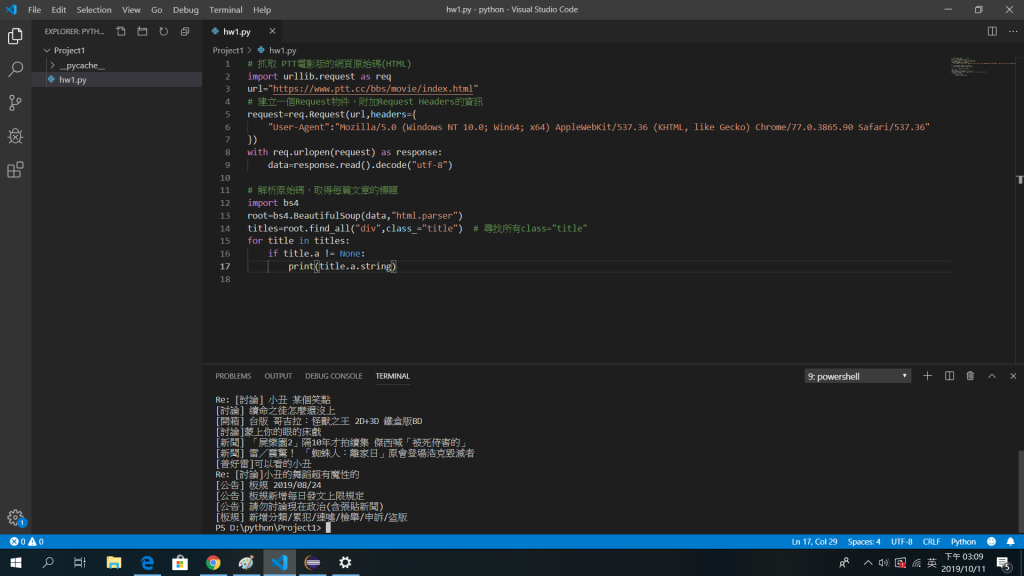


 iThome鐵人賽
iThome鐵人賽