上章節講完結構與找尋點方法,這章介紹怎鑲嵌至訓練過程。
初始化參數
class Memory(object): # stored as ( s, a, r, s_ ) in SumTree
epsilon = 0.01 # 避免tranistion太小,最小賦予0.01
alpha = 0.6 # [0~1] 轉換TD-error為priority
beta = 0.4 # importance-sampling, from initial value increasing to 1
beta_increment_per_sampling = 0.001
abs_err_upper = 1. # 裁減絕對值error
資料儲存,第一次儲存會從所有節點中找出最大值。會這樣做是因為想讓剛新增的樣本都能訓練到,以防一開始值很小,埋沒不用。
def store(self, transition):
max_p = np.max(self.tree.tree[-self.tree.capacity:])
if max_p == 0:
max_p = self.abs_err_upper
self.tree.add(max_p, transition) # set the max p for new p
資料採樣,輸入指定要的資料數量(n)。因為prioritized會打亂原本隨機性的資料分布,這裡我們會設定個參數ISWeights去做控制loss值做縮放,詳細的說明可參考paper。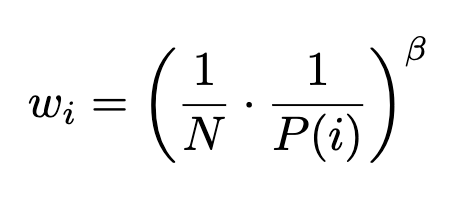
def sample(self, n):
b_idx, b_memory, ISWeights = np.empty((n,), dtype=np.int32), np.empty((n, self.tree.data[0].size)), np.empty((n, 1))
pri_seg = self.tree.total_p / n # priority segment
self.beta = np.min([1., self.beta + self.beta_increment_per_sampling]) # max = 1
min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.total_p # for later calculate ISweight
for i in range(n):
a, b = pri_seg * i, pri_seg * (i + 1)
v = np.random.uniform(a, b)
idx, p, data = self.tree.get_leaf(v)
prob = p / self.tree.total_p
ISWeights[i, 0] = np.power(prob/min_prob, -self.beta)
b_idx[i], b_memory[i, :] = idx, data
return b_idx, b_memory, ISWeights
這裡會批量更新,用設定的裁減參數(clipped_errors, alpha)去控制。
def batch_update(self, tree_idx, abs_errors):
abs_errors += self.epsilon # convert to abs and avoid 0
clipped_errors = np.minimum(abs_errors, self.abs_err_upper)
ps = np.power(clipped_errors, self.alpha)
for ti, p in zip(tree_idx, ps):
self.tree.update(ti, p)
prioritized replay我們介紹到這,儲存、採樣跟控制loss皆有點複雜,採樣管理的重要性不小於設計演算法。好哩今天到這邊,下次介紹要怎設計個OpenAI規範化的environment,我們明天見囉!
莫凡RL程式碼參考:https://bre.is/tCA5GuPc


 iThome鐵人賽
iThome鐵人賽