你曾經有沒有想過,如果我們在一個輸入框輸入了很多的字元,那麼會發發生什麼是呢?就讓我們繼續看下去...
Buffer Overflow 俗稱『緩衝區溢位』。常見原因是程式未對輸入的資料進行長度檢查,導致若有使用者輸入一筆較長的資料,這會造成程式癱瘓或改變執行流程。
舉個簡單的例子,char 陣列(字串)的輸入
gets 沒有限制輸入長度
read 有限制最⼤輸入長度
這裡寫個 Code 來比較一下差異吧!
#include <stdio.h>
int main(){
char buffer[8];
gets(buffer); // Input
puts(buffer); // Output
return 0;
}
Compile & Run
gcc test.c -fno-stack-protector -o test //必須先關閉 canary 保護機制
./test
> hello
< hello
./test
> aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
< aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
zsh: segmentation fault (core dumped) ./test
常見的 Buffer Over Flow,在 CTF 中是很常見的題型,範例程式碼如下。
#include <stdio.h>
void func(arg1, arg2){
char buffer[16];
gets(buffer);
printf("Hello, %s", buffer);
}
如果夠敏銳一定可以察覺到 buffer 僅有 16 個 Bytes 的長度,而 gets 並沒有限制使用者輸入的長度,當使用者輸入大於 16 個字元時,可能就會造成程式錯誤。
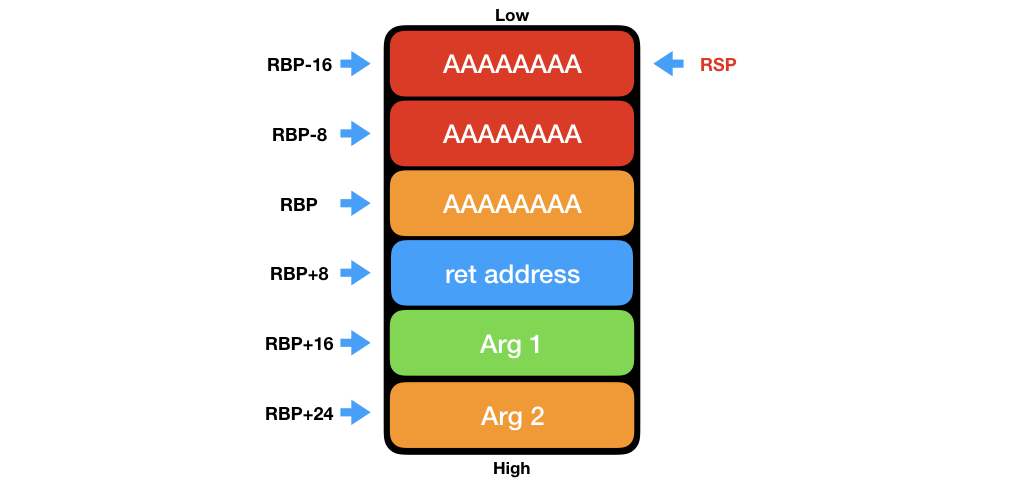
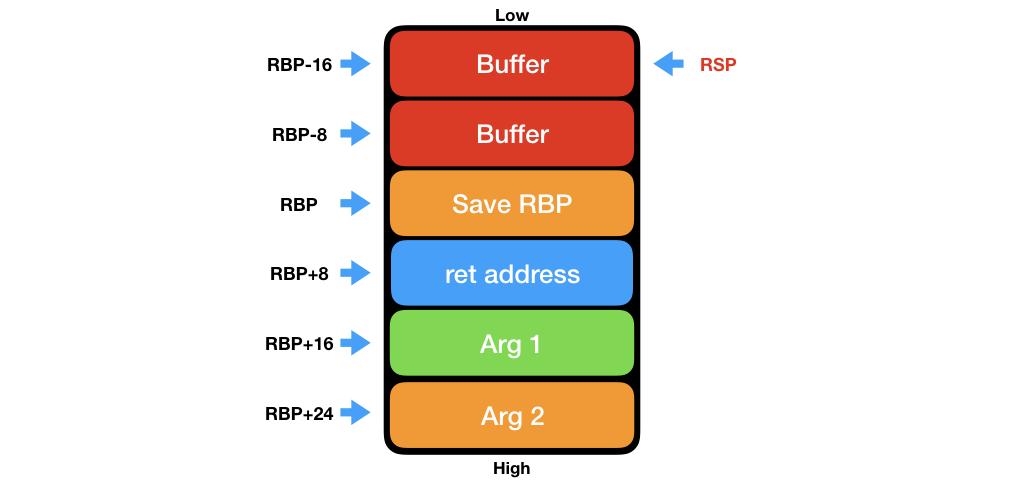
這樣說似乎有些抽象,假設 Stack 狀態如下。
當使用者輸入超過 16 個字元時的狀況,例如大量的 A,並且觀察 Stack 的狀態,可以發現所有資料都被取代成 A 了。
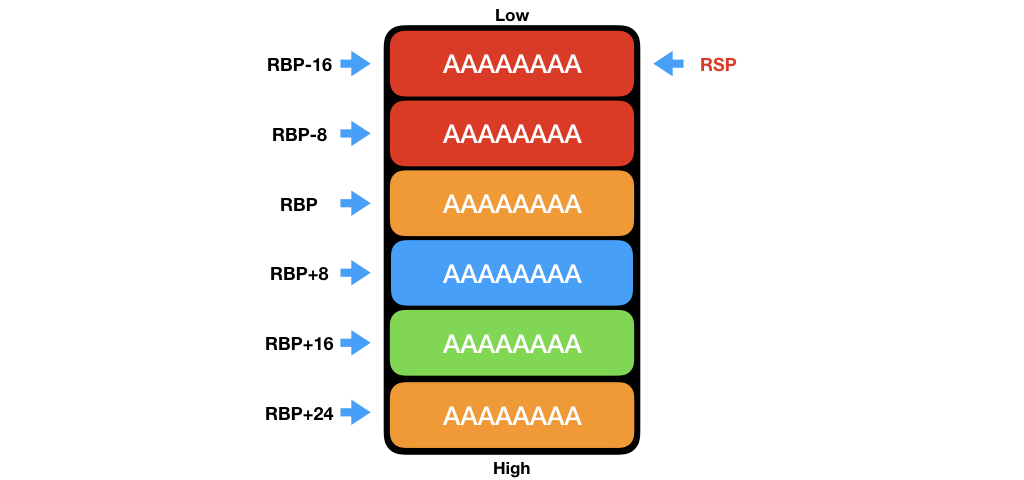
其中比較關鍵的地方是,原先為 ret address 的藍色區塊,ret address 紀錄的是一個進入該 Function 前的下一行指令的記憶體位置。
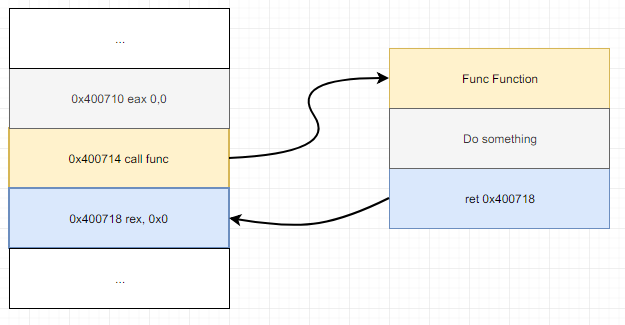
所以只要可以很精確地把 ret address 覆蓋成其他 Function 的記憶體位置,即可在該 Func Function 結束後跳至由使用者控制的目的地。