最後一個樹模型「梯度提升機」,
類似於隨機森林,但各樹間有關聯性,
會根據前一棵樹來修正。
每次⽣成樹都是要修正前⾯面樹預測的錯誤,
並乘上 learning rate 讓後⾯面 的樹能有更多學習的空間。
參考文章GBDT︰梯度提升決策樹,
訓練一個提升樹模型來預測年齡︰
訓練集是4個人,A,B,C,D年齡分別是14,16,24,26。
樣本中有購物金額、上網時長、經常到百度知道提問等特征。
提升樹的過程如下︰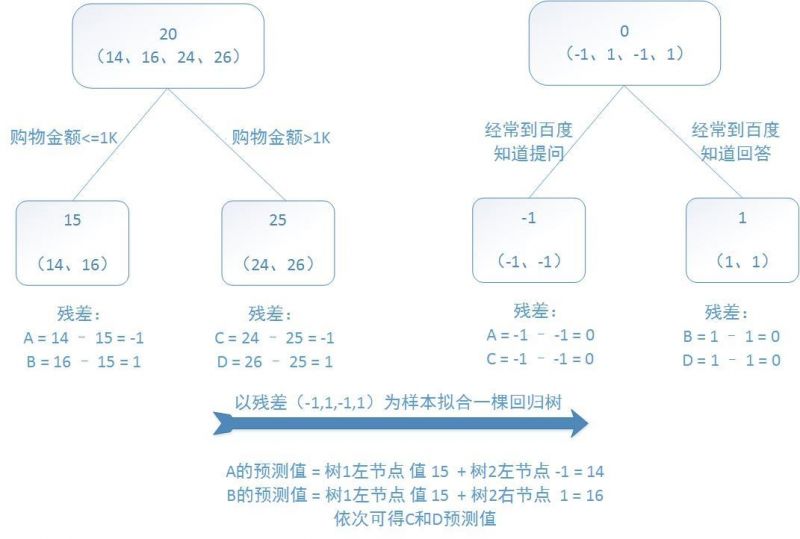
提升樹示例
該例子很直觀的能看到,預測值等于所有樹值得累加,
如A的預測值 = 樹1左節點 值 15 + 樹2左節點 -1 = 14。
因此,給定當前模型 fm-1(x),只需要簡單的擬合當前模型的殘差。
現將回歸問題的提升樹算法敘述如下︰

| 隨機森林 | 梯度提升機 |
|---|---|
| 每一個棵樹都是獨立,前一顆樹的結果不會影響下一顆 | 因為下一棵樹是為了修正前一棵樹的錯誤,因此每一棵樹街有關聯 |
| Bagging抽樣生成樹 | Boosting序列生成樹 |
| 可處理overfit | 可能會overfit |
| 可減少變異數 | 可減少誤差和變異數 |
| 獨立分類 | 序列分類 |
from sklearn.ensemble import GradientBoostingClassifier
clf = GradientBoostingClassifier(
loss="deviance", #Loss 的選擇,若改為 exponential 則會變成 Adaboosting 演算法,概念相同但實作稍微不同
learning_rate=0.1, #每棵樹對最終結果的影響,應與 n_estimators 成反比
n_estimators=100 #決策樹的數量)
梯度提升機的程式語言滿類似隨機森林,
和隨機森林不同的是,
若有兩個特徵很類似,其中一個會被踢除。
以上,打完收工。


 iThome鐵人賽
iThome鐵人賽