第 11 屆 iThome 鐵人賽
分享至
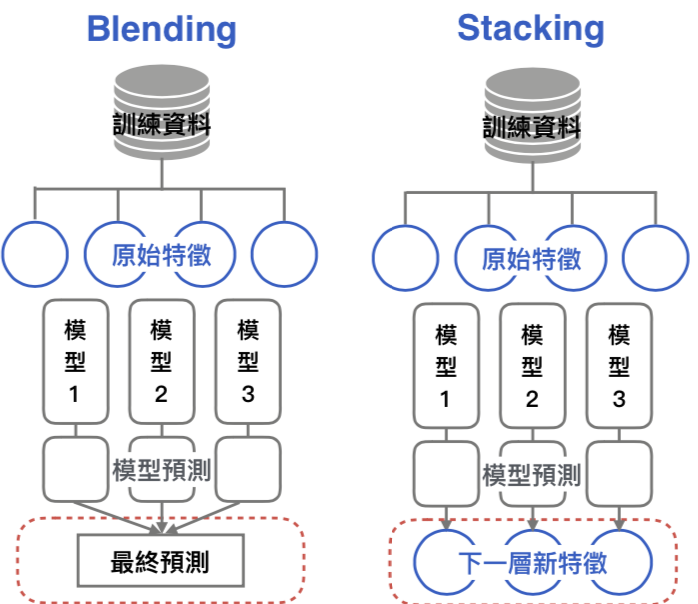
使⽤不同訓練資料 + 同一種模型,多次估計的結果合成最終預測
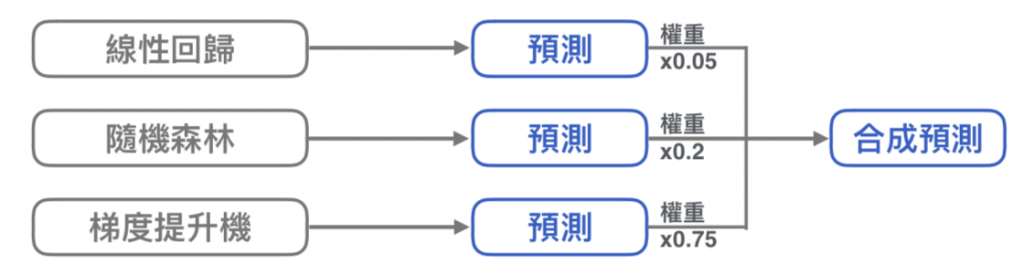
使⽤同⼀資料 + 不同模型,合成出不同預測結果
混合泛化相對堆疊泛化來說,優點在於使用容易,缺點在於無法更深入的利用資料更進一步混合模型。
以上,打完收工。
IT邦幫忙


 iThome鐵人賽
iThome鐵人賽