筆者很廢...所以還請看到這篇練習文的大佬嘴下留情 :)
先確認BeautifulSoup4已經安裝了,若是還沒請:
pip3 install beautifulsoup4
安裝完成後我們就可以直接打開編輯器來導入了!
import requests
import re
from bs4 import BeautifulSoup
這裡我們優先導入幾個我們會用到的模組: requests, re, bs4
requests:用於請求伺服器回傳資料,可用正則表達式篩選所需的資料。
beautifulsoup:方便對特定的目標加以分析、擷取的強大模組。
常用屬性和方法:
select和find的語法差異則如下:
example_find = ex.find('div', class_ = 'title')
example_select = ex.select('div.title)
現在用requests去get網頁資料,建立beautifulsoup物件main後再用python內建的html.parser去解析。
hotpage = requests.get("https://www.ptt.cc/bbs/hotboards.html")
main = BeautifulSoup(hotpage.text, 'html.parser')
print(main.text) #這裡可以print看看已抓取到除標籤外的文字

接著我們尋找並擷取所有board資料,然後用for迴圈一個一個列出來。(以下部分有參考自kevin8701111的蟲王養成)
board_find = main.find_all('a', class_='board')
# print(board_find)
for board in board_select:
header_name = board.find('div', class_ = 'board-name')
print("看板表頭名稱:",header_name.text)
header_page = board.select('span')[0]
print("看板分類文章數:",header_page.text)
header_classes = board.find('div', class_ = 'board-class')
print("看板分類:",header_classes.text)
header_title = board.select('div.board-title')[0]
print("看板標題:",header_title.text)
header_url = 'https://www.ptt.cc' + board['href']
print("看板網址:"+ header_url)
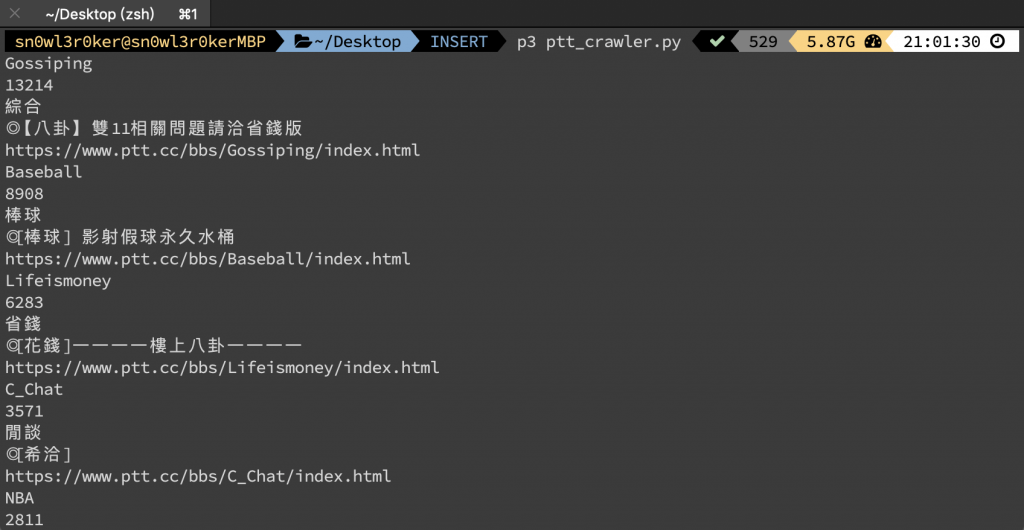
這邊補充一下網頁原始碼來對照。
下一篇 練習2:用Session和cookie通過18歲同意條款頁面
 sn0wl3r0ker
sn0wl3r0ker
