在爬蟲領域中,最簡單、常使用的套件非 requests 與 BeautifulSoup 莫屬,
只要使用這兩個套件,幾乎95%的資料都可以被爬取!
首先會介紹 requests ,下一章節再介紹 BeautifulSoup。
requests套件:最常用到的就是 get 以及 post 兩大功能;透過發出 get 或 post 請求,來取得網頁資訊
首次使用需先安裝套件 !pip install requests
import requests
from bs4 import BeautifulSoup
url = 'https://www.ettoday.net'
res = requests.get(url).text
print(res)

當發現沒辦法取得完整網站內容時,可以加入 headers
可以先嘗試加入 user-agent & Host;若不行再加入 cookie
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'cf_clearance=dbae418fe0c6a07fe6280635e7057f44f0c5aeca-1576140663-0-150; __cfduid=de4411bb1db85959721be2c90e1ed0a721576140663;ASP.NET_SessionId=mxu4rworc32oovw3ftckcuo1; _ga=GA1.3.241510402.1576140666; _gid=GA1.3.640675067.1576140666; _gat=1'
}
url = 'https://www.new7.com.tw/NewsList.aspx?t=03'
res = requests.get(url, headers=headers).text
print(res)

在爬蟲前,可以先在網頁中查看要用 GET 或 POST 的方式取得資料。
先在網頁中按右鍵點選"檢查",複製網頁中的一段文字,在 Network 的地方查詢資料放在何處。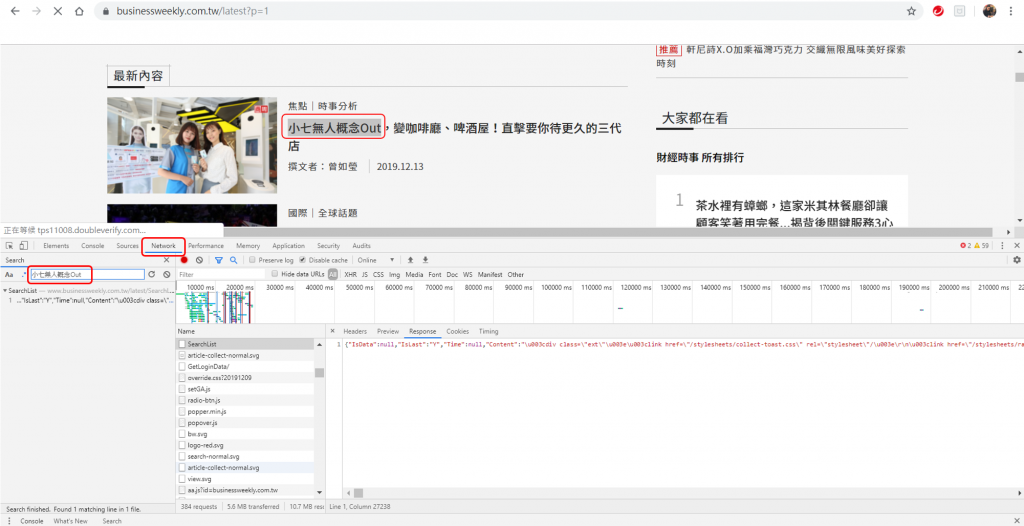
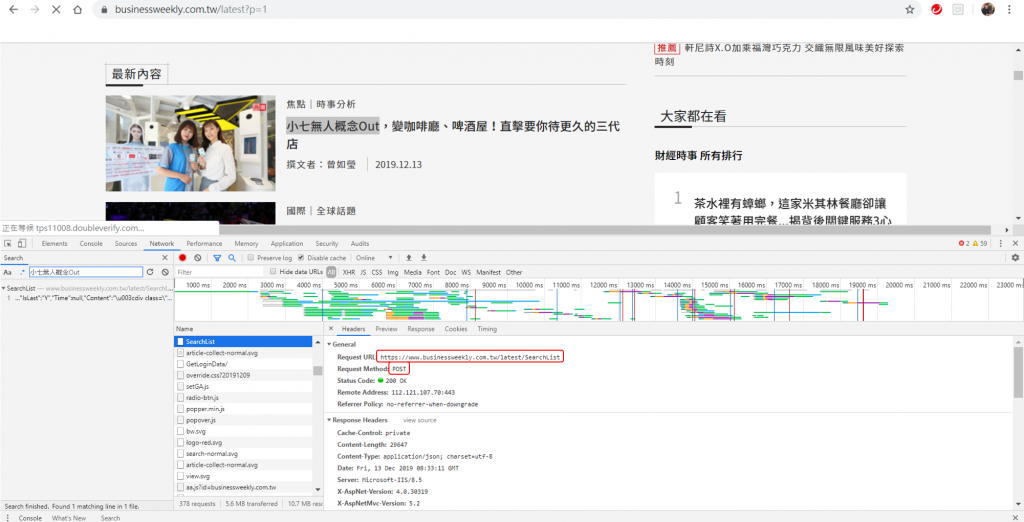
從上圖我們可以看出必須用POST的方式來抓取資料。
這裡要使用的網址為 Headers 中的 Request URL,而不是原本的 URL !

若 Headers 中有 form_data ,也須將其放入程式中。
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Host': 'www.businessweekly.com.tw',
}
form = {
'CurPage': '0'
}
url = 'https://www.businessweekly.com.tw/latest/SearchList'
res = requests.post(url, headers=headers, data=form).text
print(res)

 wesley41616
wesley41616

 iThome鐵人賽
iThome鐵人賽