不管用的是哪一種 RDBMS,相信大家都有聽過索引,不外乎就是希望SQL語法可以跑得更有效率,針對 SELECT 的 WHERE 條件欄位添加索引。
關於索引的知識也非常廣,不是一篇文章就可以說明完成,以下幾個主題是我自己覺得蠻重要的,在這裡紀錄一下也分享給大家,會以系列文的方式撰寫,這裡都是以 InnoDB 引擎的角度去撰寫。
到目前為止,MySQL 默認的儲存引擎是 InnoDB(跟其他引擎有什麼差異不在這裡討論),在 InnoDB 中 TABLE 都是依照 PK 順序組織存放的,此種儲存方式的 TABLE 就稱為索引組織表。
因此每張 TABLE 都一定要有一個 PK,如果在建立 TABLE 的時候沒有明確的指定 PK,那麼 InnoDB 會主動選擇或是創建一個 PK,也就是說一定要每張表都有 PK 的意思。選擇的規則如下
首先建立一張 TABLE ,不要指定 PK。裡面只有 c 欄位有建立唯一索引。
CREATE TABLE test1
(
a INT NOT NULL,
b INT,
c INT NOT NULL,
UNIQUE KEY a1 (c)
);
INSERT INTO test1 VALUES(1,2,3);
透過兩個方式來看看到底哪個會是 PK
方式 1 - 利用 _rowidSELECT a, b, c, _rowid FROM test1
結果如下, _rowid 可以顯示 TABLE 的 PK,可以發現 InnoDB 選了欄位 c 當 PK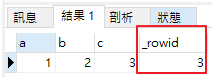
方式 2 - 利用系統表
SELECT TABLE_SCHEMA, TABLE_NAME, GROUP_CONCAT(COLUMN_NAME) as pk_column
FROM information_schema.COLUMNS
WHERE column_key = 'PRI'
AND table_schema = 'test'
AND table_name = 'test1';
結果如下,可以發現 PK 的確是選了 c 欄位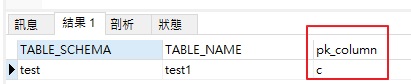
本篇大概說明了一下何謂索引組織表,不過這些前提是使用的 InnoDB 儲存引擎。後面會再說明最常見的B+樹索引
資料庫知識相當廣泛,文中若有不正確的地方,也煩請各位大神不吝指教,謝謝
參考網站
Clustered and Secondary Indexes
https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
 Stock
Stock
