B+樹,相信在學習資料庫時,多多少少都會聽過,如同二元樹、平衡二元樹等,他就是一種資料結構,定義十分複雜,在這裡只會簡單對B+樹做個簡介。
是一種資料結構,在 B+樹中所有紀錄結點都是按照鍵值大小順序放在同一層的葉子結點上(leaf node),各葉子結點會用 pointer 連結,可以從一個葉子結點到下一個葉子結點,這個好處是找到資料後可以很快再移動到下一個資料就不需要每次都從 root 出發,如圖1:是一顆高度=2 的 B+ 樹。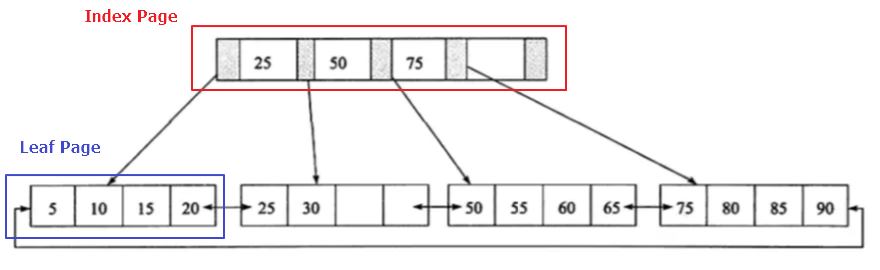
圖1 參考至書籍-MySQL 技術內幕 InnoDB 存儲引擎
這裡可以看到兩個部分
前面是簡單說一下一顆 B+樹的長相,但是 B+樹在資料庫中的實現就是B+樹索引,又可以分成
這兩種索引都是 B+樹。
上一篇文章有說過,在 InnoDB 中,每一張表都是索引組織表,可以回去看一下MySQL 系列文 - 索引的相關知識 - 索引組織表,也就是說每張 TABLE 都是依照 PK 順序存放,而這裡說的叢集索引,就是依照每張 TABLE 的 PK 順序建立的一顆 B+樹,葉子結點的部分就是放所有的資料,簡單來說
當我們在SELECT 資料時,如果優化器決定使用叢集索引,那麼就可以在叢集索引的葉子結點上直接找到資料。如果查的是範圍資料例如SELECT * FROM table_name WHERE id>10 and id <20 也能快速找到這個範圍,因為資料都已經依照 PK 去排序了。
假設有一張表: tel_tb
PK: id
id|name|phone_num
----|-------------
2|Amy|0912345678
5|Simon|0912876543
8|Terry|0912222222
9|Bob|0912111111
結構如下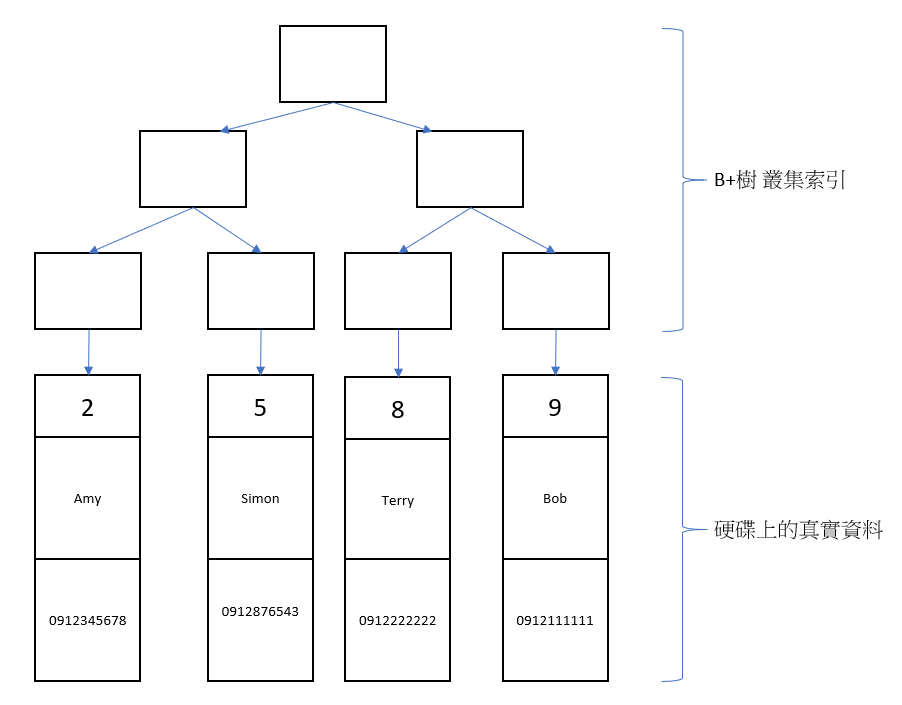
圖2
現在有一個語法 SELECT * FROM tel_tb WHERE id = 5 其查找流程如下
找到葉子結點,資料就在葉子結點上。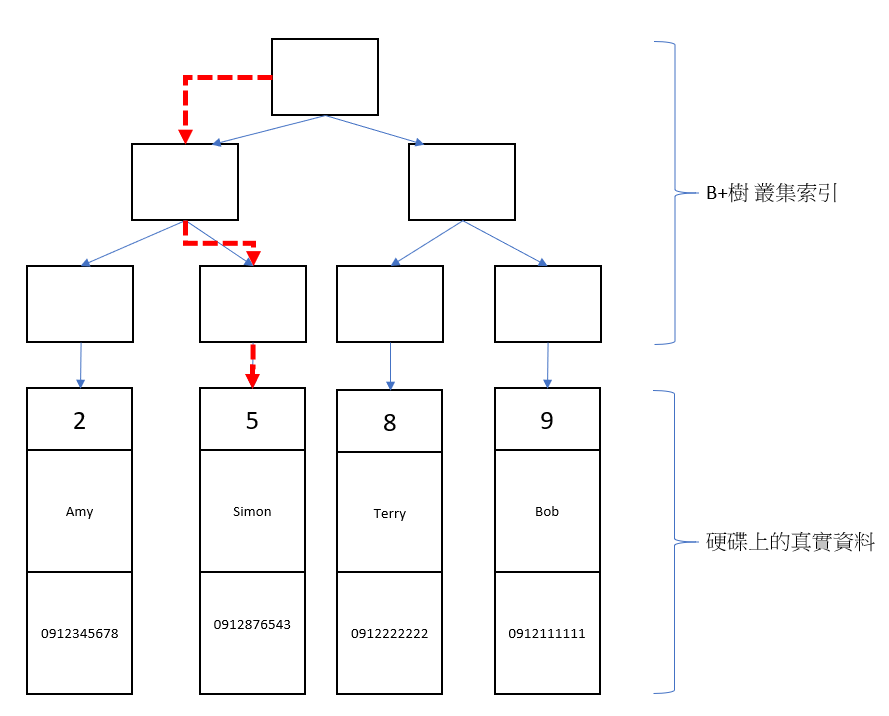
圖3
又稱為非叢集索引,跟叢集索引不同的是,其葉子結點不包含每一筆資料的所有資料。這裡的葉子結點放的是兩個部分
同上面的範例
假設有一張表: tel_tb
PK: id
id|name|phone_num
----|-------------
2|Amy|0912345678
5|Simon|0912876543
8|Terry|0912222222
9|Bob|0912111111
現在另外建立一個輔助索引在 name 欄位 CREATE INDEX index_name ON tel_tb (name)
結構如下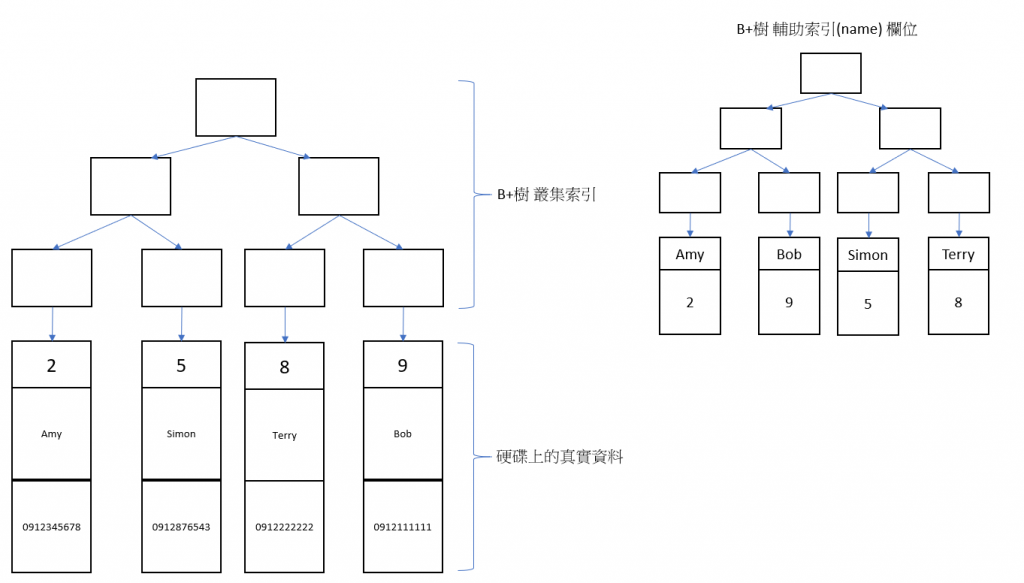
圖4
從圖中可以知道,每建立一個輔助索引,就會在建立一個 B+樹,所以表的空間會占用 Disk 更多,此外注意看輔助索引的葉子結點,並不是真實資料,放的是索引結點,也就是 name 欄位的值,而資料區域放的是對應的PK。
現在有一個語法 SELECT * FROM tel_tb name = 'Bob' 其查找流程如下
先找輔助索引找到對應的PK是 9 ,再到叢集索引去找到 9 所對應的真實資料。
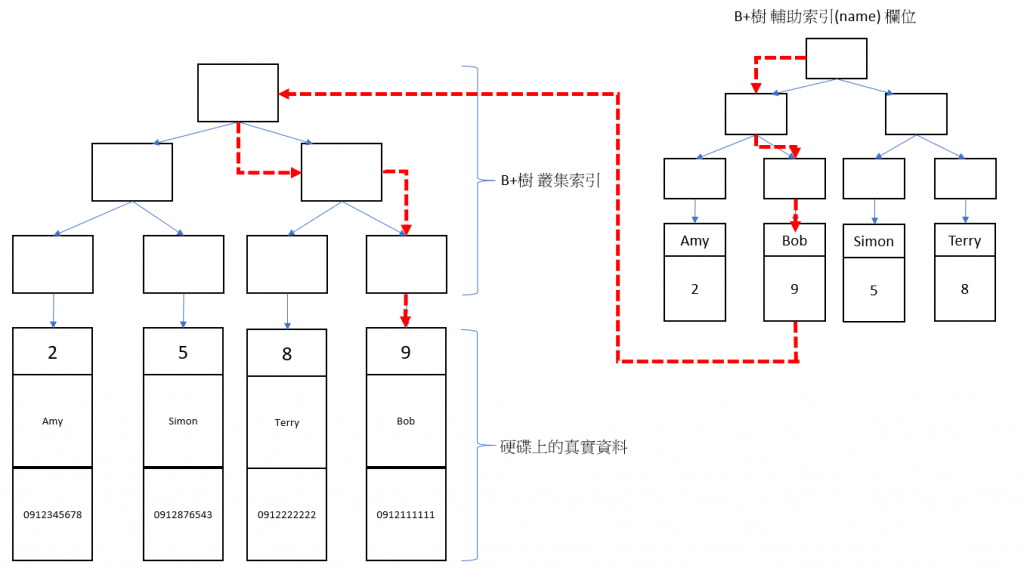
圖5
這篇主要在講叢集索引與輔助索引的差異,以及當我們在下 SELECT 語法時,怎麼在 InnoDB 裡面去查找,其實有一些狀況是不會到叢集索引裡面去拿資料的,這個觀念會在下一篇跟大家說明。
資料庫知識相當廣泛,文中若有不正確的地方,也煩請各位大神不吝指教,謝謝
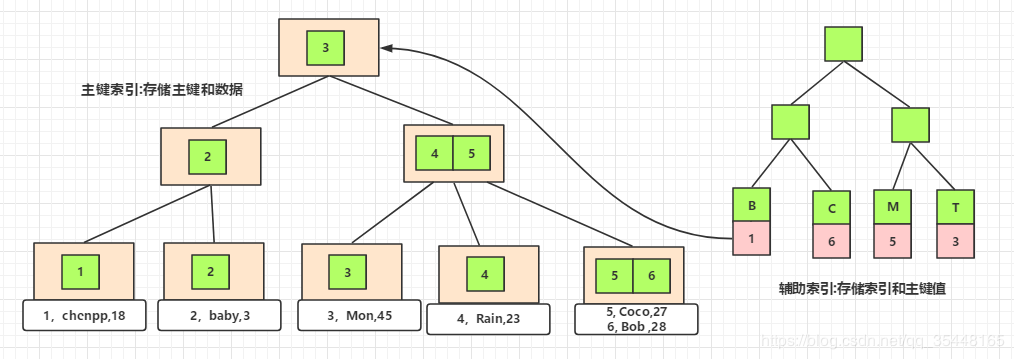
你的輔助索引應該是用phone_num 來做索引,那你覺得這棵樹的分佈還是用PK的順序去存嗎?
隨手找到一個類似,你看右邊的輔助索引,是用B,C,M,T.剛好四個.當索引值,存PK.
你再研究看看是否如此?
這真是個好問題,理解上輔助索引應該是要依照輔助索引選擇的欄位順序去存。 這部分我確認看看後再上來更新一下。
感謝大大認真的發現盲點!沒有問到我的確沒有想到。
我文章做了修正,輔助索引的欄位改用 name,比較清楚。
查了幾篇文章,輔助索引的順序應該是依照建立的 Index 欄位去存,畢竟他也是一個 B+樹,就要依照B+樹的原則。
另外你的圖,第三級部分,跟葉(資料部分),你再思考一下.
左邊的圖,真實資料部分, 你的線包含的少了,電話部分,沒包進去.
我看到了@@",我的圖跑掉了,謝謝大大!
 Stock
Stock
