這篇要介紹的是如何爬取 "PChome線上購物" 中產品的所有資訊!
這裡所寫的程式會從 def Firstlayer、def List、def Article 中的程式一層一層往下執行
首先我們進入到PChome的官網中,在左上角的地方輸入我們要搜尋的產品 (這裡我們搜尋NBA球衣)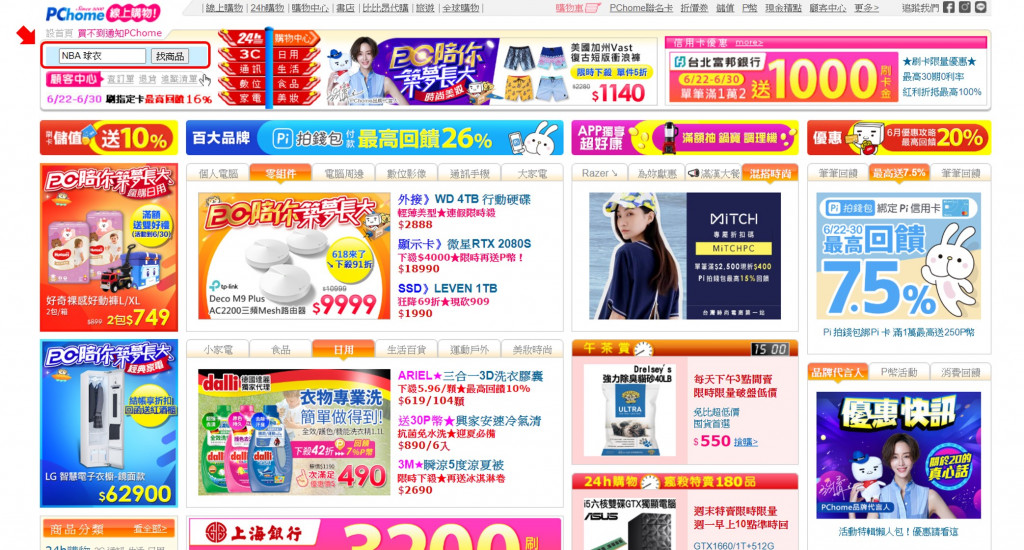
先將所有需要使用的套件import進來
import requests
from bs4 import BeautifulSoup
import json
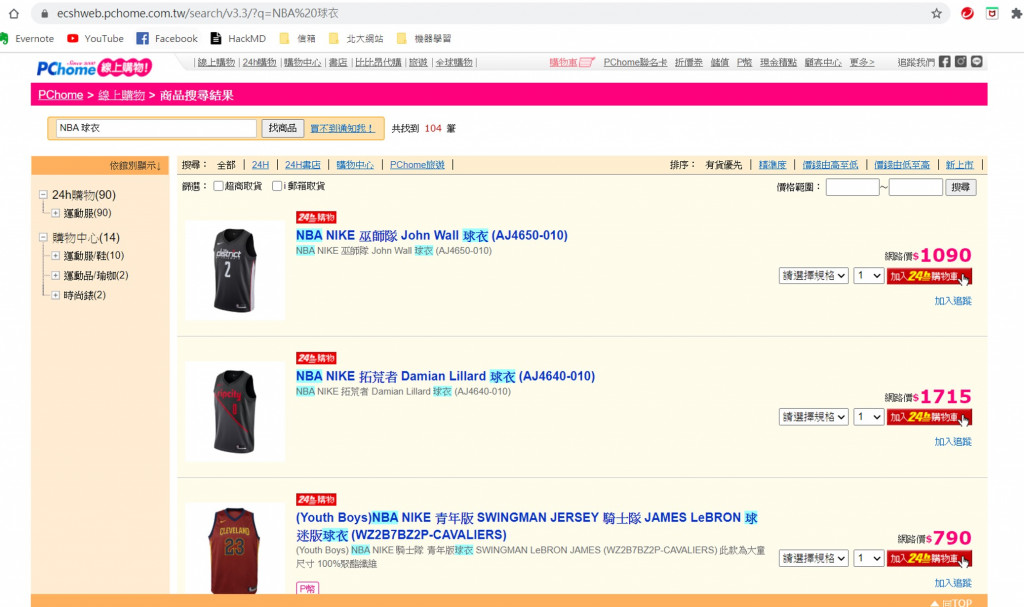
我們可以在 https://ecshweb.pchome.com.tw/search/v3.3/all/results?q=NBA球衣 這個網址中看到NBA球衣這個搜尋中的產品總共有5頁之多。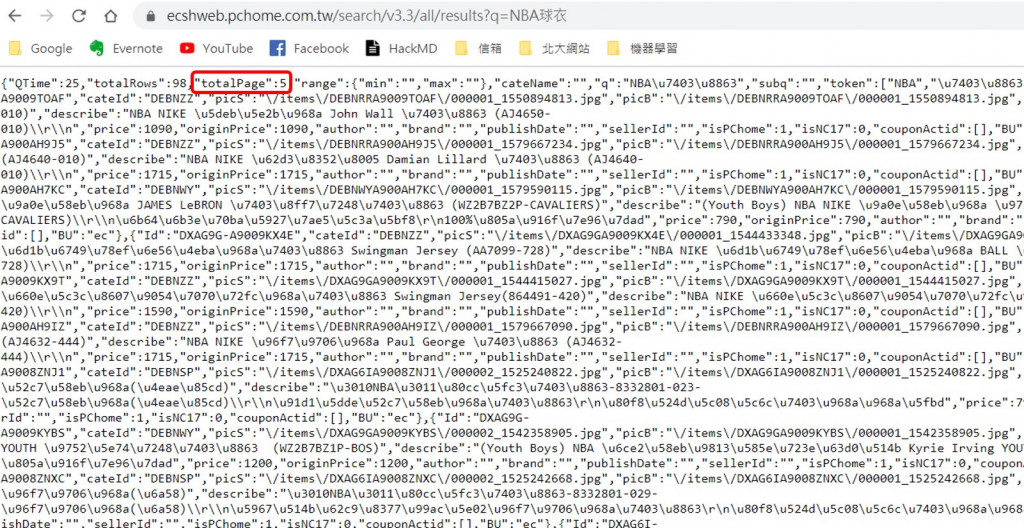
於是在程式中,我們會先抓取Page的值,再自動生成 "NBA球衣" 所有頁面的 url。
data={}是用來裝我們所有爬取的資料def Firstlayer(data, keyword):
DOMAIN = 'https://ecshweb.pchome.com.tw'
data = {}
ty_url = DOMAIN + '/search/v3.3/all/results?q={}'.format(keyword)
res = requests.get(ty_url).text
doc = json.loads(res)
Page = doc['totalPage']
for num in range(1, Page+1):
pg_url = ty_url + '&page={}&sort=sale/dc'.format(str(num))
List(pg_url, data, num)

在此步驟,我們是要獲得每個產品所對應到的網址(url)。
def List(pg_url, data, num):
print(pg_url)
resp = requests.get(pg_url).text
doc = json.loads(resp)
for product in doc['prods']:
data['Description'] = product['name']
pro_id = product['Id']
data['PrdCode'] = pro_id
article_url = 'https://24h.pchome.com.tw/prod/' + product['Id']
data['url'] = article_url
Article(pro_id, data)

在 parseArticle中,會根據每個商品的 article_url進行資料的爬取,
所有產品的相關資訊都放在這裡的 pg_url 網址中。
def Article(pro_id, data):
pg_id = pro_id + '-000'
pg_url = 'https://24h.pchome.com.tw/ecapi/ecshop/prodapi/v2/prod?id={}&fields=Price,Store,isArrival24h'.format(pg_id)
resp = requests.get(pg_url).text
doc = json.loads(resp)
# 如果資料不是空,則抓取產品相關資訊
if not len(doc) == 0:
data['Selling Price'] = doc[pg_id]['Price']['P']
data['List Price'] = doc[pg_id]['Price']['M']
if data['List Price'] == 0: data['List Price'] = doc[pg_id]['Price']['P']
brand_code = doc[pg_id]['Store']
data['Brand'] = brand(brand_code)
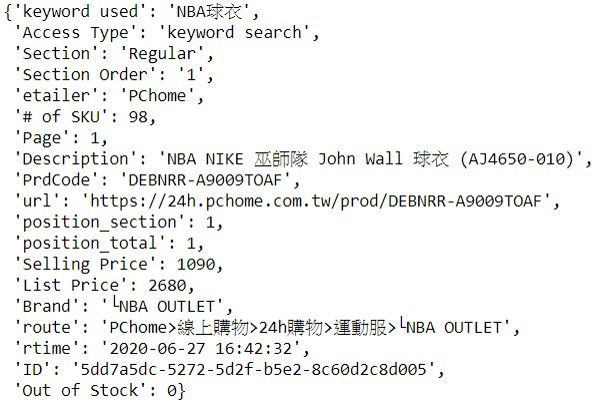
完整程式碼會提供在Github上,直接放到jupyter中,即可開始爬取工作。
https://github.com/wesley989898/PChome-search
 wesley41616
wesley41616

 iThome鐵人賽
iThome鐵人賽