安裝requests!!!
前因:
剛開始接觸爬蟲的時候,學到的是以selenium為主搭配為爬蟲設置的geckodriver瀏覽器,模擬人類使用網頁的方法,取得所需要的資料。selenium插件是一款非常直觀的爬蟲方式,利用selenium搭配網頁的原始碼,可以很輕易的做出跟人類操作一模一樣的動作,但使用一段時間後發現,selenium方便歸方便,但是這是因為它還是使用了瀏覽器的功能,它只是模擬人類使用瀏覽器的方式。造成它在爬資料的時候,速度其實不快,更由於使用瀏覽器的關係,它無法在純終端機作業系統中進行操作,這對於在遠端部署爬蟲時是個致命的缺點。因此在朋友的強迫下,我開始接觸requests這個套件。
requests的安裝與使用:
安裝requests跟安裝python其他套件一樣簡單。
在安裝完Python的環境中(我使用的是Python3.8),使用終端機安裝。
pip install requests
or
pip3 install requests
執行完便成功安裝resqusts套件。
resqusts使用方法:
requests套件支援了HTTP的各種請求方法,其中GET與POST最常使用到,而我目前也只使用過這兩個方法就能達成一般爬蟲所需要的條件。以下示範如何使用requsts套件抓取網頁。
一般而言造訪一個網站,通常都以GET這個方法達成。而使用什麼方法我們可以在網頁上開啟開發人員工具來得到網頁的資訊。
以最常造訪的google首頁來做範例。
import requests
result=requests.get("https://www.google.com/")
只要使用requests.get這個方法就可以得到該網頁的資訊:
print(result.status_code)
print(result.text)
print(result.content)
我們可以由result.status_code拿到網頁的狀態碼,200代表正常。
result.text則是解過碼的字符串(比如html代碼)。當requests發送請求到一個網頁時,requests庫會推測目標網頁的編碼,並對其解碼,轉為字符串(str)。這種方法比較容易出現亂碼。
result.content是未解碼的二進位格式(bytes),不僅支持文本內容,還適用於二進位文件內容如圖片和音樂等。如果需要把文本內容轉化為字符串,一般使用result.content.decode('utf-8')方法即可。
以下為requsts可使用的HTTP請求方式。
import requests
requests.get("http://xxxx.com/")
requests.post("http://xxxx.com/post", data = {'key':'value'})
requests.put("http://xxxx.com/put", data = {'key':'value'})
requests.delete("http://xxxx.com/delete")
requests.head("http://xxxx.com/get")
requests.options("http://xxxx.com/get")
session
requests提供了一個session的功能,讓網頁不會重新讀取,每次讀取視為同一次。
可以用以下程式碼實現。
session_requests = requests.session()
result = session_requests.get("http://xxxx.com/")
在requests網頁的同時,我們可以附加上我們給定的headers值,如以下程式碼,讓我們在拜訪網頁的時候,可以偽裝成一般瀏覽器與網頁的交流。
headers = {
'user-agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
"Accept-Language": "zh-TW,zh;q=0.9,en-US;q=0.8,en;q=0.7"
}
result = session_requests.get("http://xxxx.com/", headers=headers)
headers以字典的方式存在於python的語言中。
提交資料
如果網頁要求提供資料以POST的模式,我們可以查看開發者人員模式下,選擇Network確認該網頁要求POST。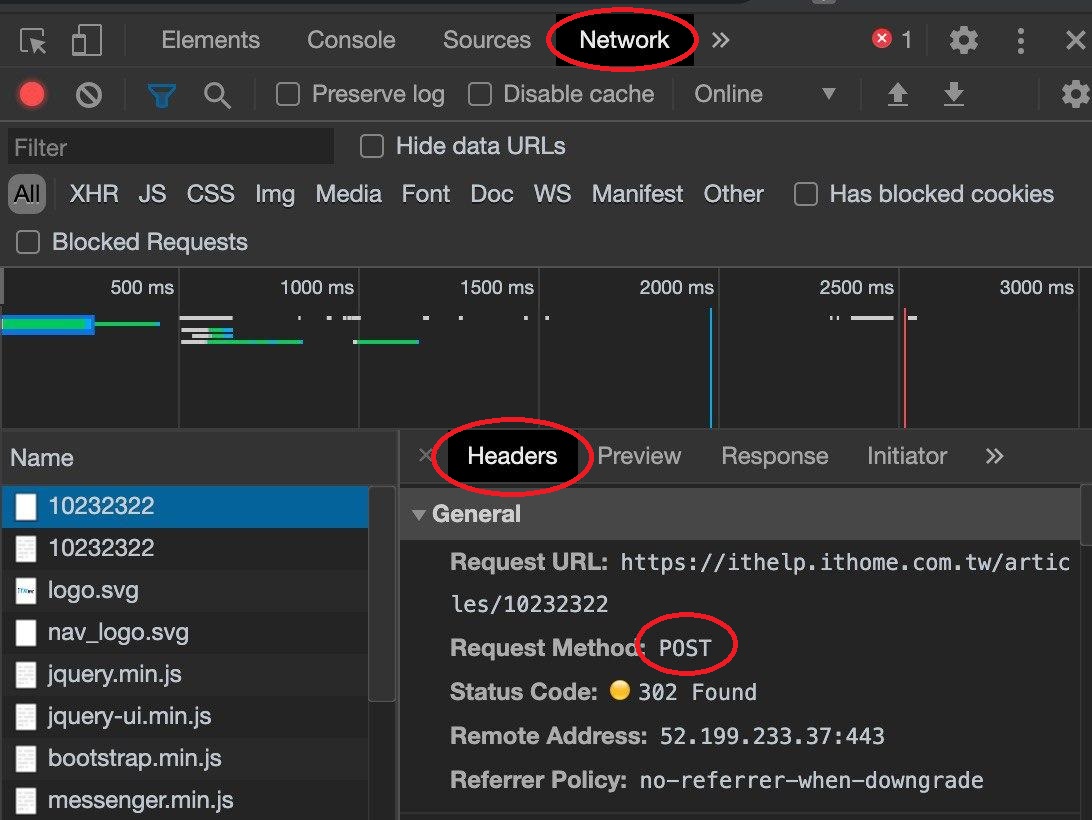
開發者人員模式拉到最下方可以觀察這個網頁所需要的FOR表。
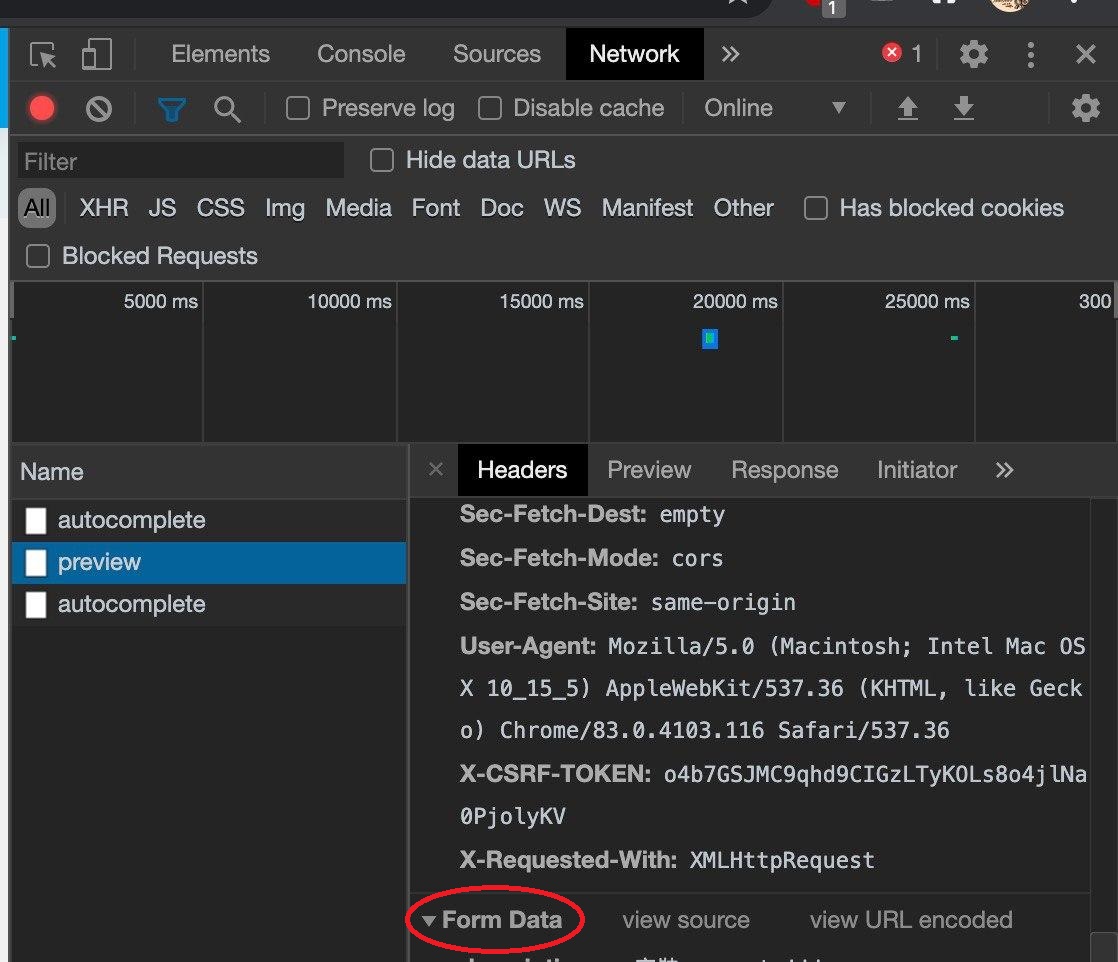
此時就可以根據FORM Data表看到所需要的資料,並以此做出以字典的方式做出要上傳的Data。
data = {
"xxxx": "xxxx",
"yyyy": "yyyy",
}
此時便可使用request.post指令上傳所需的資料。
result = requests.post("http://xxxx.com/", data=data, headers=headers)
關於requests的部份暫時就介紹到這邊,下篇文章會介紹如何分析我們用requests所抓取的網頁。
 tarrant777
tarrant777

 iThome鐵人賽
iThome鐵人賽