在 Day 1 ,我定義了本次挑戰要解決的問題:「利用 ES Cloud 打造我的盤後選股工具」。接下來,最重要的任務就是搜集盤後資訊並且放進 Elastic Search。首先從基礎的核心概念開始探索吧!
Node 用來存放資料。當我們啟動一個 Elasticsearch 的實例時,也就是啟動了一個 Node。而一個 Elasticsearch instance 其實就是作業系統中的一個 Java Process,因此在一個機器上,可以有多個 Node 來存放資料。
Node = ES instance = Java Process
Cluster 是相關聯 Node 組成的集合。在 ES Cloud 上部署 Elasticsearch,實際上就是創建一個 Cluster。透過 Kibana 的 Dev Tools,我們可以察看 Cluster 的資訊,如圖: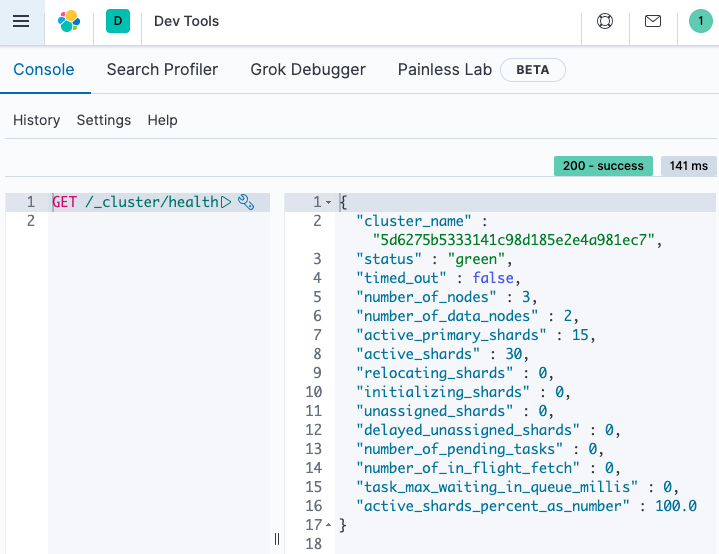
可以發現,在 ES Cloud 上的預設部署會創建一個 Cluster,其中包含 3 個 Node。
ES 中,資料的最小單位叫 Documen,是 JSON 物件,存放在 Index 中。而相同類型的資料為其創建 Index,形成一個集合。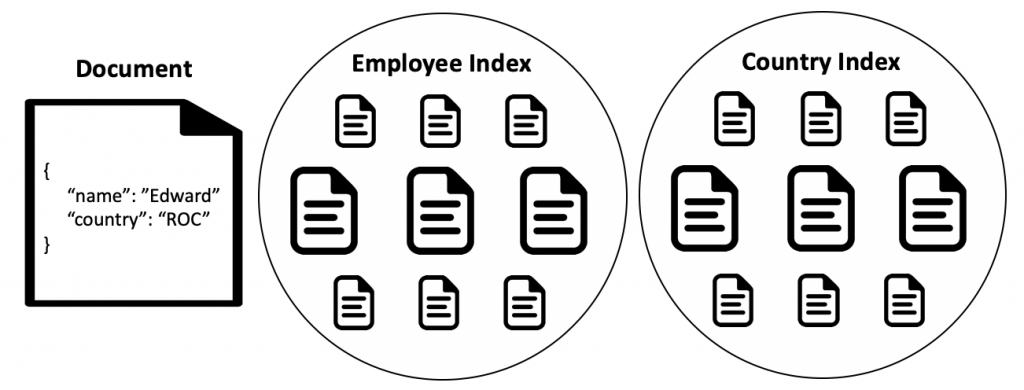
同樣的透過 Dev Tool,可以觀察一下 ES 部署後,預設的 Index 資訊,如圖: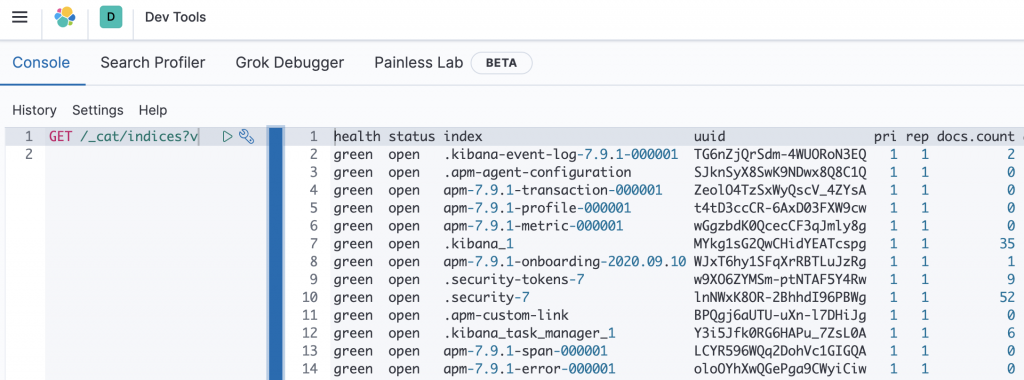
在比較舊的 ES 版本中有所謂的對映型別 (Mapping Type),並將其對比於關聯式資料庫的 Table。但這其實是一個不正確的對比假設,並且造成了一些潛在的問題,因此 ES 7.0 以上的版本已經將 Mapping Type 移除了,詳細資訊可以參考這篇文章。
對 Elasticsearch 的資料管理有了概念上的理解後,下一步,就來看看怎麼把資料塞進去吧!


 iThome鐵人賽
iThome鐵人賽