為了解決更複雜的問題,或是提高 AI 系統的精確度,放大 (Scaling Up) ConvNets (作者習慣用 ConvNet 稱呼 CNN,以下依作者的習慣)是設計模型時常用的手法,一般使用的方法是調整深度、寬度、或者輸入解析度來達到目的。 雖然這三個維度是可以同時調整的,過去的研究中,大家通常只調整其中一個維度,這那麼做的原因可能是因為模型調整的過程中,三個維度變化的複雜程度較高,而且沒有一個可供參考的原則,只好使用試誤法 (try-and-error) 來進行,非常耗費時間及資源,所以只好將就於一兩個維度的調整。這樣做出來的結果想必不是效率最好的模型結構。
針對這個維度調整的問題,這篇論文有以下的發現:
Our empirical study shows that it is critical to balance all dimensions of network width/depth/resolution, and surprisingly such balance can be achieved by simply scaling each of them with constant ratio.
也就是說,依照一個固定的比例來調整這三個維度,可以獲得一個有效率的模型。作者稱這種調整方法為「複合式模型縮放 (compound model scaling)」,它的公式是:
深度:
寬度:
解析度:
模型所需計算資源:N ∈ {0, 1, 2, 3, …}
N是自然數的集合,N = 0 時代表 Baseline Model 的比例:
深度:1
寬度:1
解析度:1
模型所需計算資源:1
N = 1 時:
深度:
寬度:
解析度:
模型所需計算資源:
表示我們應將 Baseline Model 的深度,擴充為原來的 1.2 倍,寬度擴充為 1.1 倍,而輸入解析度則擴充為 1.15 倍。此時新的模型所需的計算資源大約是原來的 2 倍(所謂計算資源,稍後論文有詳細的定義)。
找到了「複合式模型縮放」這個公式後,論文作者們更進一步利用這個公式設計出一系列的 ConvNets,這一系列的模型,即是 EfficientNets 。
在設計 EfficientNets 之初,必須找到一個 Baseline Model ,這個模型非常重要,因為它必須是有效率的模型,否則由一個沒有效率的模型擴充出來的新模型,就算用再好的擴充方法,出來的結果也是不理想的。
作者使用「自動化模型結構搜尋法 (Neural Architecture Search; 註一)」,產生了一個 Baseline Model ,稱之為 EfficientNet-B0 (B 代表 Baseline, 0 代表 N = 0),接著使用「複合式模型縮放」,以 N = 1 到 7 分別產生了 7 個擴充模型,命名為 EfficientNet-B1 到 EfficientNet-B7 ,之後將它們和一些著名的 CNN 模型做了效能比較,如下圖:
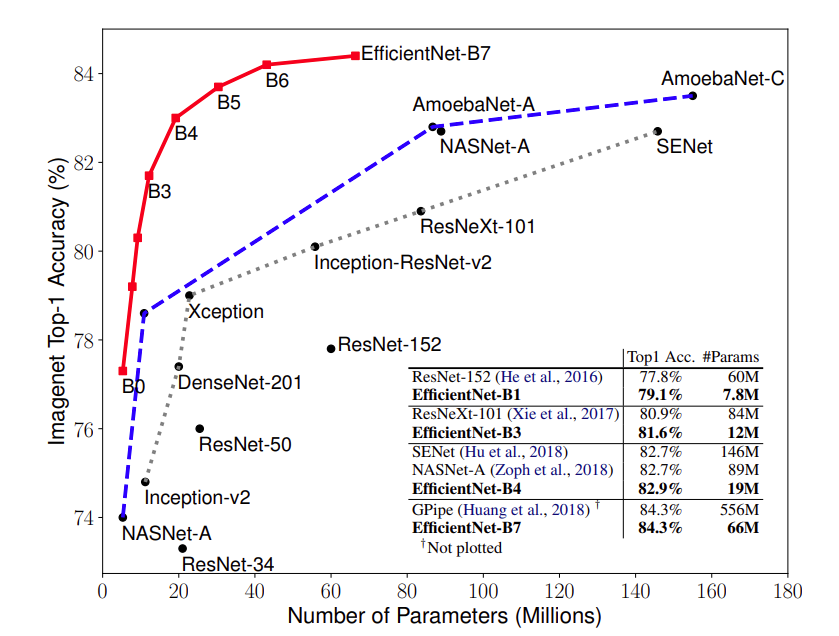
和當時 ImageNet Top 1 排行前茅的 GPipe 相比,EfficientNet-B7 可以達到與其相當的精確度,但是模型大小只有它的 12%!相較於知名的 ResNet-50,EfficientNet-B4 與其模型規模相當,效能則提升了 6.7% (Top 1 精確度由 76.3% 提升至 83.0%)。
到此,我們概略了介紹了 EfficientNet,接下來,我們將深入探討論文的技術細節。
(註一:作者參考了
Zoph, B. and Le, Q. V. Neural architecture search with reinforcement learning. ICLR, 2017;
Tan, M., Chen, B., Pang, R., Vasudevan, V., Sandler, M., Howard, A., and Le, Q. V. MnasNet: Platform-aware neural architecture search for mobile. CVPR, 2019.)

