Compound Model Scaling 是 EfficientNet 這篇論文提出的第一個關鍵技術。老頭找不到一個好的中文譯名,勉強可以把它翻成「複合式模型縮放」,下文就用這個譯名來指稱這個技術。
為了有益於複合式模型縮放公式的推導以及稍後 EfficientNet 的設計,作者引用了一個非常簡潔的 ConvNet 模型結構,在此結構下,每個模型是由若干個 stage 所構成,而每個 stage 內包含若干個卷積層 (Convolutional Layer),而位於同一個 stage 裏的卷積層皆是相同 CNN 架構。
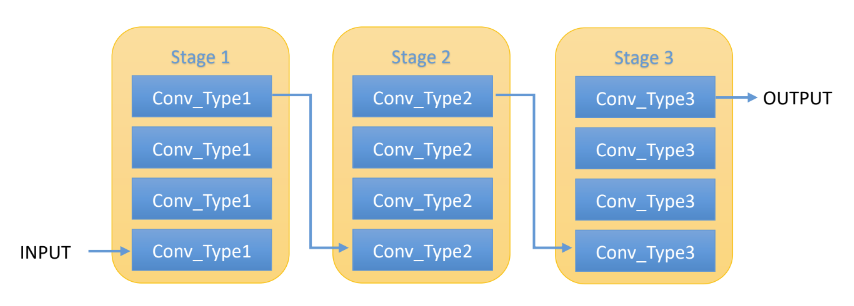
ResNet 就是類似這種結構的模型,它由 5 個 stage 所構成,而每一個 stage 內的卷積層,除了第一層用來作降低取樣數 (down-sampling) 之外,其他各層皆有相同的卷積層型式。所以論文作者雖然選用了簡潔的模型結構,但最終模型的效能應該不致於太打折扣,而後來他們的研究成果也證明了這一點。
在這個簡潔的模型結構下,論文作者把複合式模型縮放這個問題,定義為:
在此要注意的是「寬度 (Width)」 這個字,在論文中,所謂「寬度 (Width)」維度的改變,是指每層輸入的 Channel 數的改變。不要和每層輸入的(Hight, Width)中的 Width 相混淆。
以下節錄論文內關於問題描述的結論,供大家參考。
Our target is to maximize the model accuracy for any given resource constraints, which can be formulated as an optimization problem:
前面提到論文選定了三個維度(深度、寬度、解析度)來調整模型。
先來看看深度,深度的增加(亦即增加卷積層數)是最常用的手法。直覺上越深的模型越能找出輸入影像中各種複雜的特徵 (Feature),越能處理複雜的問題,其泛化(Generalization)的能力也應該比較好。然而模型越深越難訓練,而且隨著深度的增加,它對模型精確度的影響也隨之遞減。
而寬度的調整過去較常用於小模型,它能夠找出比較微細的特徵 (fine-grained features),也讓模型比較容易訓練。但是過寬的模型反而會增加擷取高階特徵 (higher level features)的難度,同時模型精確度的增加量很快就會隨著寬度而飽和了(就是精確度不再改善了)。
解析度亦然,最早普遍流行的解析度是 224x224,後來陸續出現 299x299,331x331,480x480,600x600 等。隨著計算力的提升和實務上(如醫療影像)的需求,更高解析度是必然的趨勢。高解析度有助於擷取微細的特徵,同時也能提升模型精確度,但和前兩者一樣,提升的效果是隨著解析度的增加而遞減。
在此,論文作者提出他們的第一個觀察結論(原汁原味,不翻了):
Observation 1 – Scaling up any dimension of network width, depth, or resolution improves accuracy, but the accuracy gain diminishes for bigger models.
從以上的論述,我們知道這三個維度各有其優點及限制,直覺上它們三者應是相關的,應該同時考量。作者做了些實驗,並得到了第二個觀察結論:必須平衡三者的調整幅度,方能得到效率及精確度高的模型。
Observation 2 – In order to pursue better accuracy and efficiency, it is critical to balance all dimensions of network width, depth, and resolution during ConvNet scaling.
提出了這個觀察結論之後,作者開始建構其複合式模型縮放的公式,它的縮放原則是: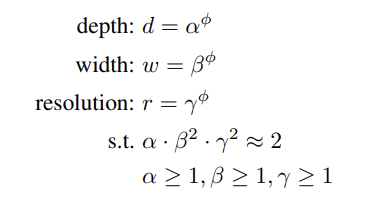
d, w, r 分別表示深度、寬度及解析度的增加倍數,它們分別由常數 α, β, γ 及縮放係數 φ 來決定。作者將透過實驗及網格搜尋(Grid Search)去找到適當的值。其中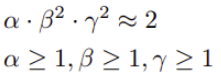
的限制是來自於 FLOPS 運算量的考量。在 ConvNet 下,增加深度(卷積層數)與所增加的運算量是線性的,而增加寬度及解析度,所需的運算量是平方倍增加,有了這個限制,將使得 φ 每增加 1,模型所需的運算量增加為原來的兩倍。
舉例來說,當 φ 為 0 時,d, w, r 皆為 1,表示其為 baseline model。當 φ 為 1 時,d = α, w = β, r = γ,模型的深度、寬度及解析度就依照這三個倍數來增加,增加後所需的算力,依上述限制式,約為 baseline model 的 2 倍。
決定了縮放原則,EfficientNet 的設計就可以正式開始了。


