技術文章
技術問答
My Project
iT 徵才
聊天室
2026 鐵人賽
登入/註冊
文章
問答
Tag
邦友
鐵人賽
搜尋
第 12 屆 iThome 鐵人賽
DAY
13
0
AI & Data
今晚,我想來點經典NLP論文。
系列 第
13
篇
[D13] Weakly Supervised User Profile Extraction from Twitter (Li et al., 2014) 1/2
12th鐵人賽
victor.huang
2020-09-27 20:35:03
846 瀏覽
分享至
Paper Link
ACL 2014
https://www.aclweb.org/anthology/P14-1016.pdf
Key Points
本文旨在預測網路使用者個人資訊(profile)。
主要貢獻:
把預測任務轉換成資訊抽取任務。
提出一個大規模的資料集。
呈現資訊抽取任務的形式帶來的好處。
呈現此篇文章提出的模型的效果。
過去文獻:
Distant Supervision
利用現有的資料庫裡面的人物與其關係,蒐集訓練文本中可能描述這個關係的文字。
Homophily
利用社群網路上鄰居的資訊來獲得目標使用者的個人資訊。
同質性高的人們在社群網路上總是相連的。
Mislove et al. 曾從 Facebook 上爬下 4000 個 Rice U. 的學生並純粹基於網絡資訊來預測該學生的主修和預科。
但其並未使用作者的文字資訊。
資料庫收集
教育與工作
從 Google+ API 裡面蒐集帶有以下三個資訊的使用者。
工作
教育
Twitter 帳號
再從這些種子使用者裡面,找到同時在 Twitter 上與在 Google Circle 上都存在的好友/追蹤者。
這些好友也要帶有工作和教育資訊。
蒐集該使用者的所有帶有工作和教育相關的貼文,作為正資料集,其餘作為負資料集。
用 Freebase API 來對應別名,如 Harvard U. -> Harvard University。
婚姻
只有臉書有婚姻資訊,但公開的使用者不多。
退而求其次用 FreeBase 裡面的人物與關係。
這裡的人物幾乎都是名人,如歐巴馬。
貼文的收集方法一樣。
但不知道這些名人描述婚姻的方式是否與一般人相同?
與工作和教育不同,婚姻不具 Homophily。
但具 Reflexivity。
所以若 a 與 b 為婚姻關係。
那我們 a 提及 b 的貼文和 b 提及 a 的貼文都會收集。
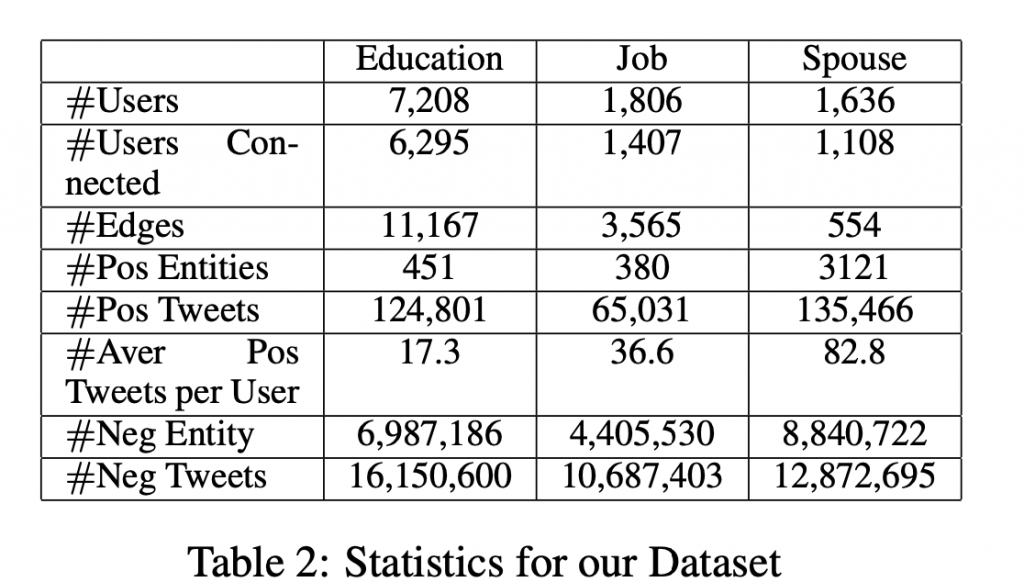
資料集收集結果如下
[未完待續]
留言
追蹤
檢舉
上一篇
[D12] Dynamic topic models (Blei and Lafferty, 2006) 2/2
下一篇
[D14] Weakly Supervised User Profile Extraction from Twitter (Li et al., 2014)
系列文
今晚,我想來點經典NLP論文。
共
17
篇
目錄
RSS系列文
訂閱系列文
1
人訂閱
13
[D13] Weakly Supervised User Profile Extraction from Twitter (Li et al., 2014) 1/2
14
[D14] Weakly Supervised User Profile Extraction from Twitter (Li et al., 2014)
15
[D15] Weakly Supervised User Profile Extraction from Twitter (2014) 2/2
16
[D16] Emotion Intensities in Tweets (2017) 1/2
17
[D17] Emotion Intensities in Tweets (2017) 2/2
完整目錄
熱門推薦
{{ item.subject }}
{{ item.channelVendor }}
|
{{ item.webinarstarted }}
|
{{ formatDate(item.duration) }}
直播中
立即報名
尚未有邦友留言
立即登入留言
iThome鐵人賽
參賽組數
66
組
團體組數
2
組
累計文章數
55
篇
最後報名日
9/15
看影片追技術
看更多
{{ item.subject }}
{{ item.channelVendor }}
|
{{ formatDate(item.duration) }}
直播中
熱門tag
15th鐵人賽
16th鐵人賽
13th鐵人賽
14th鐵人賽
17th鐵人賽
12th鐵人賽
11th鐵人賽
鐵人賽
2019鐵人賽
javascript
2018鐵人賽
python
2017鐵人賽
windows
php
c#
linux
windows server
css
react
熱門問題
ChatGPT Business & Codex 如何從零開始?
關於LSTM 做IDS分類資料集處裡
CODEX 桌面版本app重啟後分頁老是消失 (為什麼)
熱門回答
ChatGPT Business & Codex 如何從零開始?
熱門文章
[Tedium Is Stability-03] 與 AI 一起開發,轉念:別再「調 prompt」,你要設計的是一個「循環」
Day 01 - Claude Code 其實就只是一個 while 迴圈
2026 年網站設計新工具,CrocoBuilder 原生 AI 的 WordPress 網頁編輯器
【AI Agent 架構】Agent 不是越複雜越好:哪些機制該留,哪些可以拿掉?
Agent 產生的 UI 能顯示,不代表它已經可以上線
IT邦幫忙
×
標記使用者
輸入對方的帳號或暱稱
Loading
找不到結果。
標記
{{ result.label }}
{{ result.account }}


 iThome鐵人賽
iThome鐵人賽